The same AI model that earned a gold medal at the International Mathematical Olympiad cannot reliably tell you what time it is from a clock face, and that sentence is precisely documented.
Stanford's 2026 AI Index, released April 13, tracks what researchers call the "jagged frontier" of AI capability: a profile of progress so uneven that the distance between what these systems can and cannot do defies any simple summary. On some of the hardest problems in human knowledge, AI has quietly become the best tool we have. On tasks that a five-year-old performs without a second thought, the same models fail at rates that would embarrass a coin flip. Understanding why this happens, and what it means practically, is the most important thing most people have not yet internalized about the current state of AI.
What the Numbers Actually Show
Where AI Has Become Superhuman
Stanford's Technical Performance chapter documents a set of gains that, looked at individually, would have seemed implausible eighteen months ago.
- Coding. On SWE-bench Verified, a benchmark that tests models against real GitHub issues requiring actual code changes in real repositories, performance rose from 60% to near 100% in a single year — not incremental improvement but compression of the entire human-to-AI performance gap in twelve months.
- PhD-level science. On GPQA Diamond, which tests graduate-level science questions designed to be difficult for experts, model accuracy rose above the expert human validator baseline of 81.2%, reaching 93% in 2025. Top models came within 0.4 percentage points of the best human expert reference on MMMU, a multimodal benchmark built around diagrams, charts, tables, and equations. Stanford's report states that frontier models "outperform human chemists on average" on ChemBench.
- The hardest exam ever built. Humanity's Last Exam is 2,500 questions contributed by subject-matter experts across 1,000 institutions in 50 countries, specifically designed to stump frontier AI models. Questions include Roman inscription translation, obscure hummingbird anatomy, and competition mathematics that would defeat most PhD holders. In 2025, the top model answered 8.8% correctly. A year later, as of April 2026, Claude Opus 4.6 and Google's Gemini 3.1 Pro were both clearing 50%. A benchmark designed to last years was approaching the halfway mark in two.
- Olympic mathematics. Gemini Deep Think scored 35 points at the 2025 International Mathematical Olympiad, earning a gold medal and working in natural language within the 4.5-hour time limit. The year before, the best score was a silver at 28 points.
- Autonomous computer use. AI agents went from 12% to approximately 66% task success on OSWorld, a benchmark that tests general computer use across operating systems, representing a more than five-fold improvement.
Where AI Has Stayed Shockingly Bad
- Analog clocks. ClockBench measures whether a multimodal AI can look at an image of an analog clock and report the correct time. OpenAI's GPT-5.4, the best-performing model on this benchmark as of March 2026, read the time correctly 50.1% of the time. Unspecialized humans score 90.1%. Claude Opus 4.6, the same model that surpasses PhD-level experts on Humanity's Last Exam, read analog clocks correctly 8.9% of the time.
- Household tasks. Robots succeed in only 12% of household tasks on the BEHAVIOR-1K simulation benchmark. Tasks like folding laundry and washing dishes remain effectively unsolved at the system level despite years of research effort.
- Implicit reasoning. In February 2026, a prompt asking leading AI models whether it is better to walk or drive to a car wash 50 meters away spread virally because most systems gave the wrong answer. The question requires recognizing that the car itself needs to arrive at the car wash, an implicit constraint the language of the question does not state. A systematic test by Opper across 53 models found 42 said to walk. A subsequent preprint by Yubo Li and colleagues, "The Model Says Walk: How Surface Heuristics Override Implicit Constraints in LLM Reasoning," formalized this as a category of failure rather than an isolated error.
- Hallucination. The AA-Omniscience Index, which measures factual recall and knowledge calibration across 6,000 questions in 42 economically relevant domains, operates on a scale from -100 to 100. A score of zero means the model answers correctly as often as it answers incorrectly. Among all evaluated frontier models, only three score above zero. Claude 4.1 Opus leads with a score of 4.8. The remaining frontier models produce more incorrect answers than correct ones when forced to answer knowledge questions. Stanford's 2026 AI Index separately tracked hallucination rates across 26 models on the AA-Omniscience benchmark and found rates varying from 22% to 94%, with no clear relationship between a model's capability benchmark scores and its hallucination rate.
Why the Jagged Frontier Exists
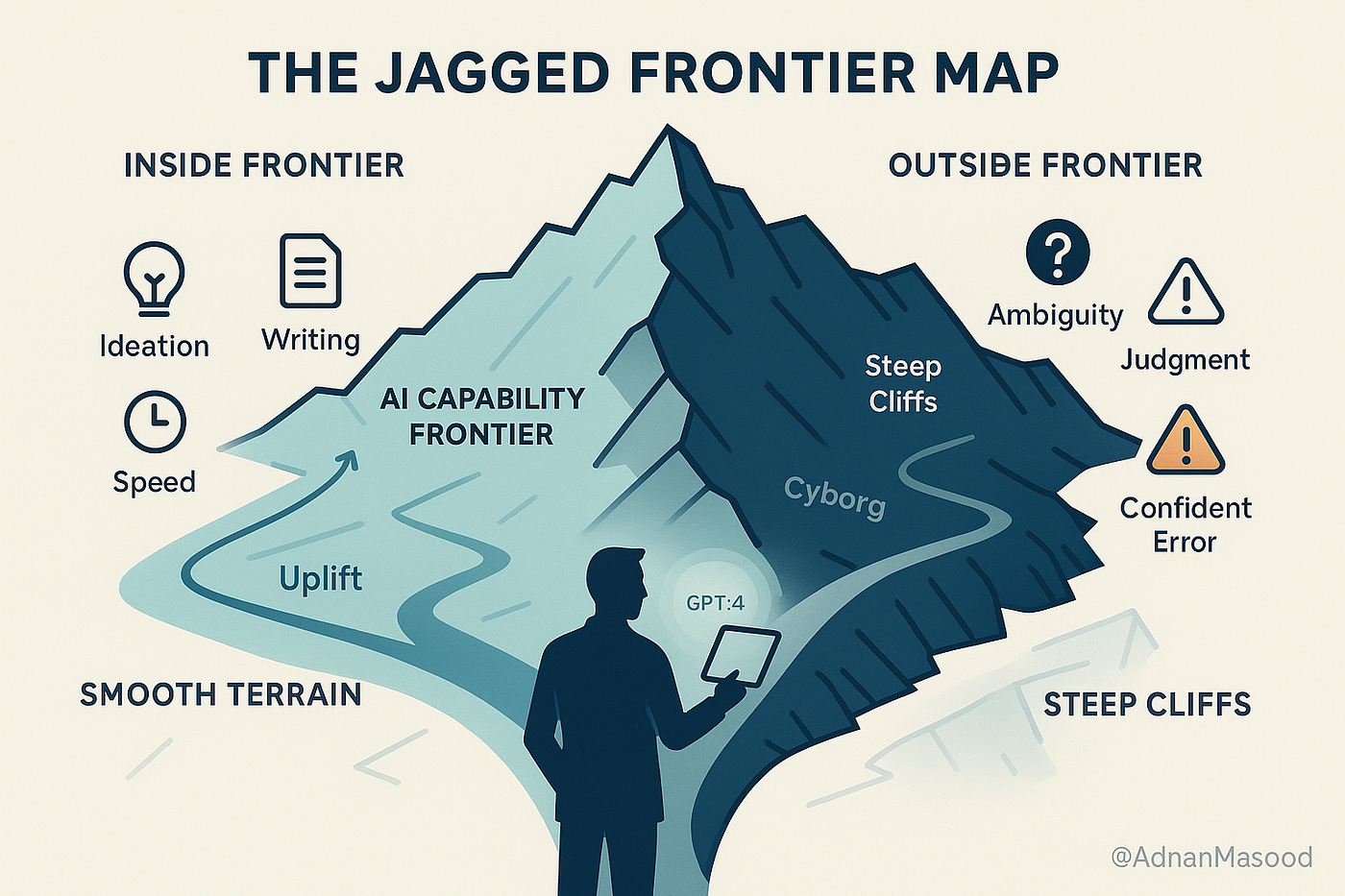
Ray Perrault, co-director of Stanford HAI's AI Index steering committee, offered the research community's best current explanation for the analog clock failure in the IEEE Spectrum coverage of the report: "There is a research thread that shows that when systems are asked questions about combinations of language with other modalities, such as images or audio, the language component carries a surprisingly large part of the burden."
This means that when a model looks at an image of a clock, it is not processing visual information the way a human visual cortex processes it. It is, in some meaningful sense, leaning on language-trained pattern matching to interpret what it sees, and that pattern matching is less robust to the specific spatial and rotational relationships encoded in an analog clock face than it is to the kind of pattern matching that works well on text.
The car wash problem points to a different failure mode: surface heuristics overriding implicit constraints. When the question is framed in language that pattern-matches to "distance" and "mode of transport," the model activates reasoning about those concepts and produces a plausible answer to that version of the question, without correctly representing what the question actually required. The reasoning is coherent while the constraint space is wrong.
These are systematic patterns rather than random failures, reflecting something structural about how large language models work: they are extraordinarily good at pattern matching within distributions they have been trained on, and they generalize poorly to situations that require reasoning about combinations or constraints at the edges of those distributions.
What the Jagged Frontier Means for Benchmarks
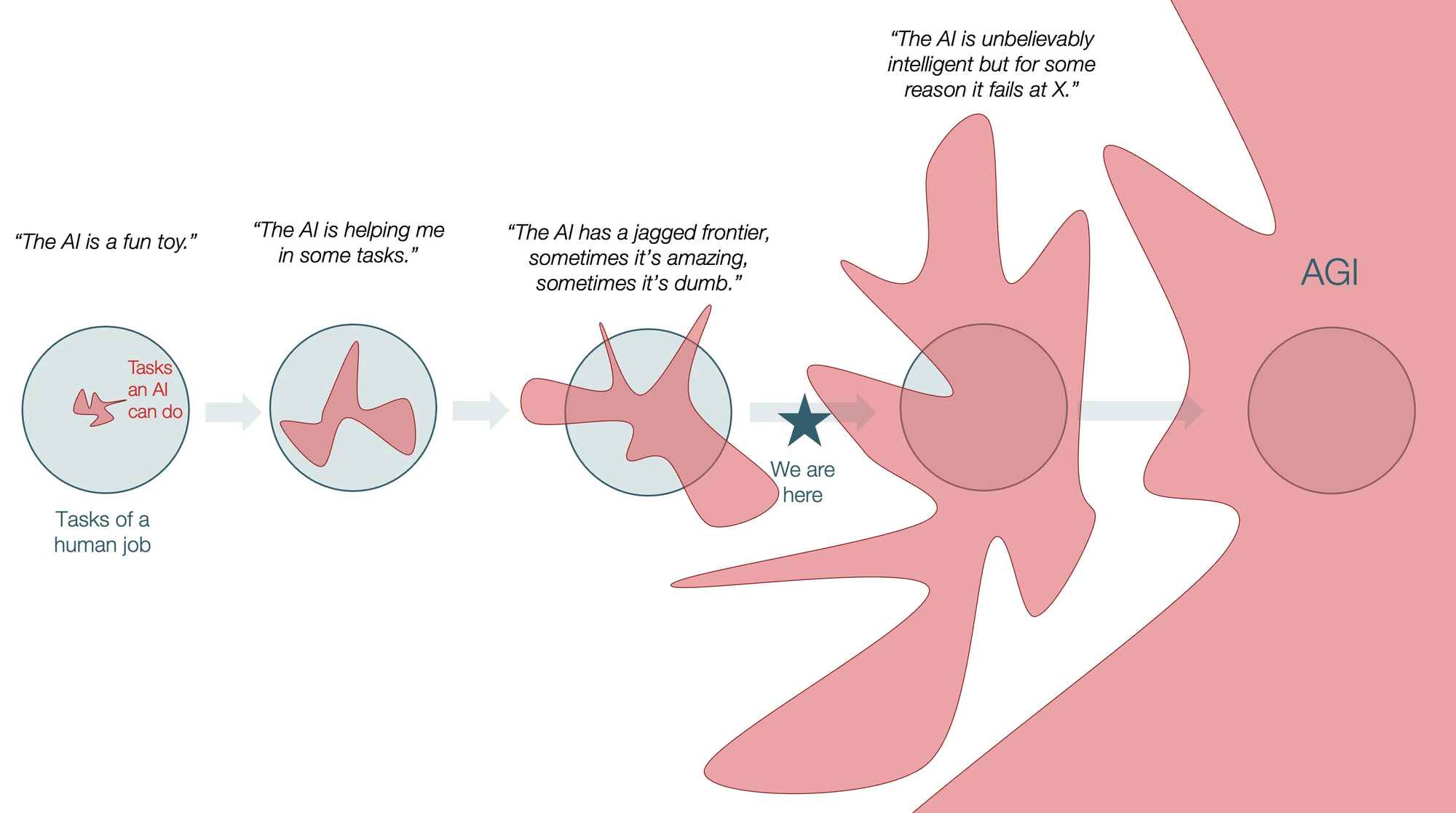
The jagged frontier creates a specific problem for how AI progress is discussed and evaluated, because headline benchmark performance leads naturally to headline benchmark conclusions.
When a model achieves near-human performance on GPQA Diamond, the temptation is to conclude that AI has achieved something like general scientific competence. The ClockBench result shows why that conclusion is premature. The model performing at expert level on one demanding task can simultaneously be worse than random on a different task that any sighted adult handles effortlessly.
Stanford's report identifies a parallel problem with benchmarks themselves: they saturate. A benchmark designed to be challenging for years is often cleared in months once the frontier advances. This creates a measurement gap in which the field's standard evaluations no longer distinguish among the best models, and new harder benchmarks must be created to replace them.
This dynamic has a practical consequence that Stanford's Perrault stated directly: "Knowing that a benchmark for legal reasoning has 75 percent accuracy tells us little about how well it would fit in a law practice's activities." Benchmark scores are poor proxies for real-world reliability because benchmarks are standardized and models have typically been trained on data that resembles them, while real-world tasks are heterogeneous and rarely map cleanly to the structures benchmarks are designed to test.
The legal system has already encountered this concretely. The Stanford 2026 AI Index cites cases where attorneys used AI to generate more than two dozen fake citations and misrepresentations of fact, leading to public reprimands from the US Sixth Circuit Court of Appeals. The models involved would have scored well on many legal reasoning benchmarks. The benchmark score did not predict the failure mode.
The Responsible AI Gap
Alongside the jagged capability frontier, the 2026 Stanford report documents a responsible AI gap that is widening rather than closing.
Documented AI incidents, defined by the AI Incident Database as "harms or near harms realized in the real world by the deployment of AI systems," reached 362 in 2025, up from 233 in 2024. The report attributes much of this increase to the same growth in adoption that drives the positive economic numbers: more deployment means more opportunity for real-world failures.
Almost all leading frontier AI model developers report results on capability benchmarks, while reporting on responsible AI benchmarks covering safety, bias, and harmful output rates remains "spotty" in the report's language. The models most visibly deployed are the least transparently evaluated on safety dimensions.
Stanford also notes a research finding that compounds the difficulty: improving one responsible AI dimension, such as safety, can degrade another, such as accuracy, and those tradeoffs are real, not always intuitive, and not always predictable. A model tuned to refuse more confidently may hallucinate less but also provide less useful information in legitimate contexts. Optimizing for helpfulness in one direction can create new failure modes in another.
The Public-Expert Divide
One finding in the Stanford report sits between the capability data and the responsible AI data and helps explain both: the 50-point gap between expert and public views on AI's impact on employment.
Among AI experts, 73% expect AI to have a positive impact on how people do their jobs. Among the general public, 23% agree. That 50-point gap is not a communication failure or a knowledge deficit that better science journalism can close.
It reflects that experts are primarily observing AI's performance on the tasks where it excels, while the public is experiencing AI's deployment in contexts where the jagged frontier creates visible failures, and where the employment effects fall first on workers who have the least ability to absorb them.
The jagged frontier is experienced differently depending on what you are using AI for. If you are using it for the tasks where it is superhuman, the expert optimism seems obviously correct. If you are using it for tasks where it fails at coin-flip rates, or absorbing the labor market effects of its deployment in your industry, the public skepticism seems equally well-grounded. Both groups are observing the same technology while looking at different parts of the frontier.
Frequently Asked Questions
What is the "jagged frontier" of AI?
The jagged frontier is the term Stanford researchers use to describe AI's uneven capability profile: extraordinary performance on some of the hardest problems in human knowledge, combined with surprising brittleness on tasks that humans find trivially easy. The same models that surpass PhD-level expert performance on science benchmarks fail to read analog clocks at better than coin-flip accuracy. The frontier is not uniformly advancing; it has peaks and valleys that reflect structural features of how these systems work.
Why can't AI read an analog clock if it can solve graduate-level science problems?
Stanford AI Index co-director Ray Perrault attributes the clock-reading failure to a research-documented phenomenon: when models are asked questions combining language with other modalities like images, the language component carries a disproportionately large share of the cognitive burden. The model processes the clock image through pattern matching more similar to text understanding than visual spatial reasoning, and that approach breaks down on the rotational and spatial relationships encoded in clock hands. The failure is systematic, not random.
What is Humanity's Last Exam, and how is AI performing on it?
Humanity's Last Exam is 2,500 questions contributed by nearly 1,000 subject-matter experts across 500 institutions in 50 countries, designed to stump frontier AI models. Questions span advanced mathematics, obscure scientific domains, and specialist knowledge inaccessible to generalists. In 2025, the best model answered 8.8% correctly. By April 2026, Claude Opus 4.6 and Google's Gemini 3.1 Pro were both clearing 50%. A benchmark designed to remain challenging for years is approaching the halfway mark in two.
What is the hallucination problem, and how serious is it in 2026?
The AA-Omniscience benchmark, which measures factual recall and knowledge calibration across 6,000 questions in 42 domains, operates on a scale where zero means as many correct as incorrect answers. Among all evaluated frontier models, only three score above zero. The leading model, Claude 4.1 Opus, scores 4.8. Most frontier models produce more incorrect answers than correct ones on factual knowledge questions when forced to respond. Hallucination rates across 26 models on this benchmark ranged from 22% to 94%, with no reliable correlation to capability benchmark performance.
What does the responsible AI gap mean for people using AI tools?
Documented AI incidents rose from 233 in 2024 to 362 in 2025. Almost all leading AI developers report on capability benchmarks; reporting on safety and responsible AI benchmarks "remains spotty," according to Stanford. Research has also found that improving AI on one safety dimension can degrade performance on another. For users, this means strong capability benchmark scores do not predict safety in deployment, and models should be evaluated specifically on the tasks they will actually perform rather than assumed to be reliable based on general scores.
Related Articles