
Announced just yesterday on November 17, 2025, this upgrade promises to redefine how we interact with AI, blending razor-sharp intellect with enhanced empathy, creativity, and reliability.
At its core, Grok 4.1 addresses the subtleties of real-world conversations that have long challenged AI systems. Drawing from the advanced reinforcement learning infrastructure pioneered in Grok 4, the model has been fine-tuned for better style, personality, and alignment. It's now more attuned to users' nuanced intents, making interactions feel compelling and coherent—whether you're brainstorming ideas, seeking emotional support, or collaborating on a project. xAI's engineers went a step further by leveraging frontier agentic reasoning models as reward signals, allowing the system to iterate on responses at scale, even for subjective qualities like emotional depth.

One of the standout advancements is a dramatic reduction in factual hallucinations, particularly for information-seeking queries. Internal evaluations show significant drops in error rates, ensuring responses are not just insightful but trustworthy. Grok 4.1 introduces two distinct modes to cater to different needs: "Grok 4.1 Thinking" (codenamed quasarflux), which employs thinking tokens for deeper reasoning on complex tasks, and a streamlined non-reasoning mode (codenamed tensor) for quick, immediate replies.
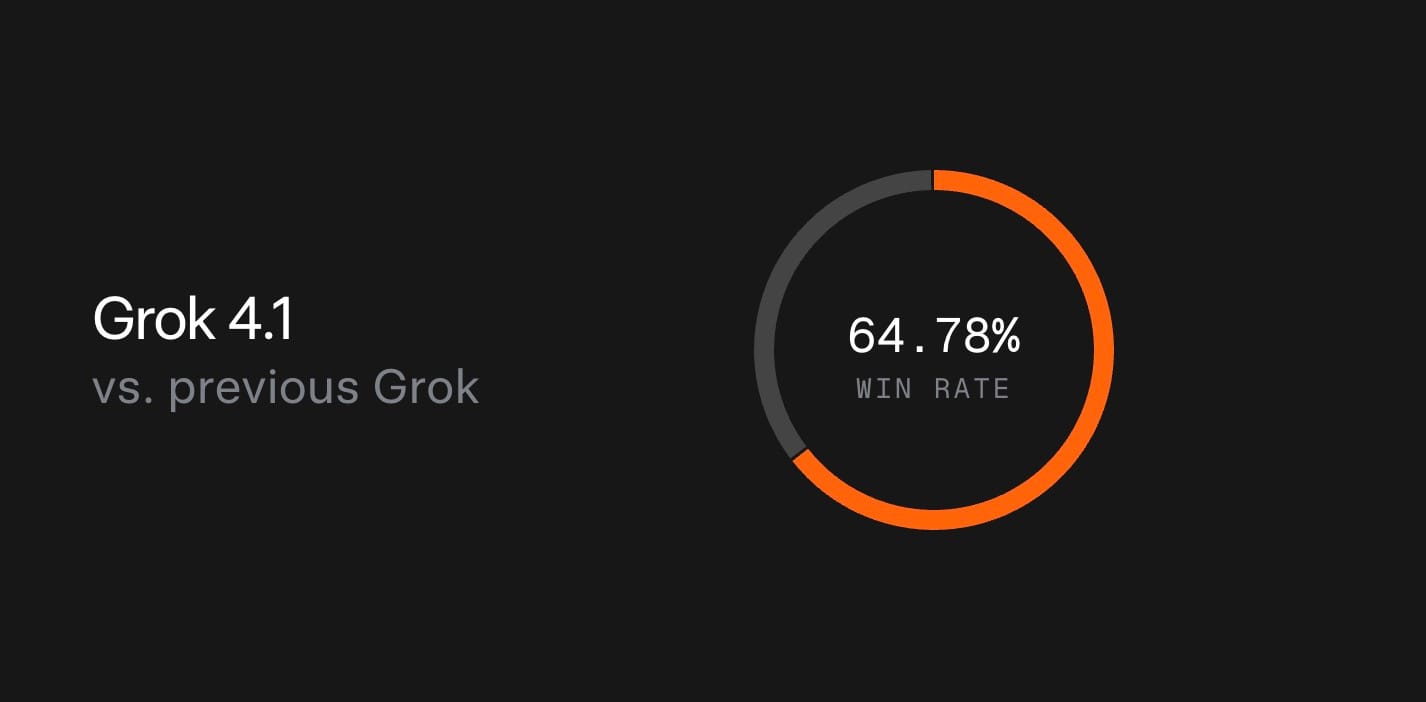
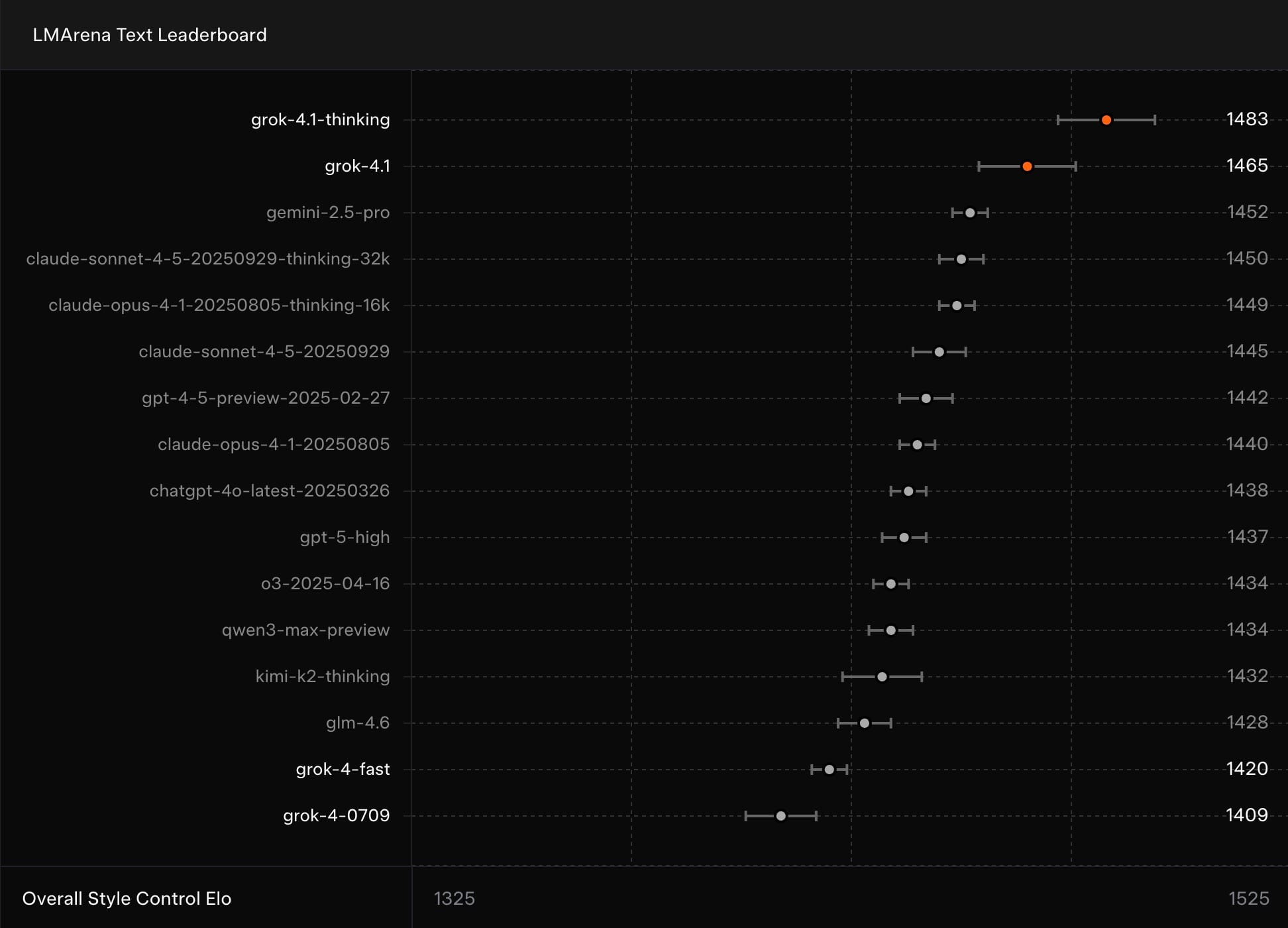
The proof is in the benchmarks, where Grok 4.1 doesn't just compete—it dominates. In blind pairwise evaluations against the previous production model, it was preferred a whopping 64.78% of the time. On the LMSYS Arena Text Leaderboard, it claims the #1 spot overall with an impressive 1483 Elo rating—a 31-point lead over the next non-xAI contender. Even in non-reasoning mode, it ranks #2 at 1465 Elo, outpacing every other model's full-reasoning setup and leaving Grok 4 (previously #33) in the dust.
But Grok 4.1 shines brightest in areas where raw compute meets human nuance. On EQ-Bench3, a rigorous test of emotional intelligence across 45 roleplay scenarios, it excels in empathy, insight, and interpersonal skills—evaluated using Claude Sonnet 3.7 as a judge. Creative Writing v3 benchmarks, based on 32 prompts iterated three times, highlight its prowess in generating compelling narratives, with scores normalized via Elo ratings and detailed rubrics. And for factuality, metrics like FActScore (tested on 500 biography questions) and hallucination rates on production queries underscore a model that's as reliable as it is imaginative.
Accessibility is key to xAI's mission, and Grok 4.1 is rolling out immediately to all users—no gatekeeping here. You can access it on grok.com, X (formerly Twitter), and the Grok iOS/Android apps. It starts in "Auto" mode for seamless integration, but power users can select "Grok 4.1" explicitly from the model picker. This follows a stealthy preliminary rollout from November 1–14, 2025, where early builds were tested on growing slices of production traffic, all validated through ongoing blind evaluations.
As AI continues to weave into our daily lives, Grok 4.1 feels like a pivotal moment: an AI that's not just smart, but relatable. Whether you're a writer chasing the perfect plot twist, a developer debugging with a dash of wit, or simply someone venting about a tough day, this model is designed to meet you where you are. xAI's relentless push toward understanding the universe just got a whole lot more personal.
Stay tuned for more updates as users dive in and share their experiences. What's your first prompt for Grok 4.1? Drop it in the comments below!
For the full technical deep-dive, check out the official announcement here.
Read more about Grok AI:













