Not long ago, the conversation around AI capability had a predictable shape. OpenAI built something. Everyone else scrambled to catch up. The gap between a proprietary frontier model and anything freely available felt less like a technical gap and more like a wall — one that would take years, maybe a generation of models, to scale.
That wall came down faster than almost anyone expected.
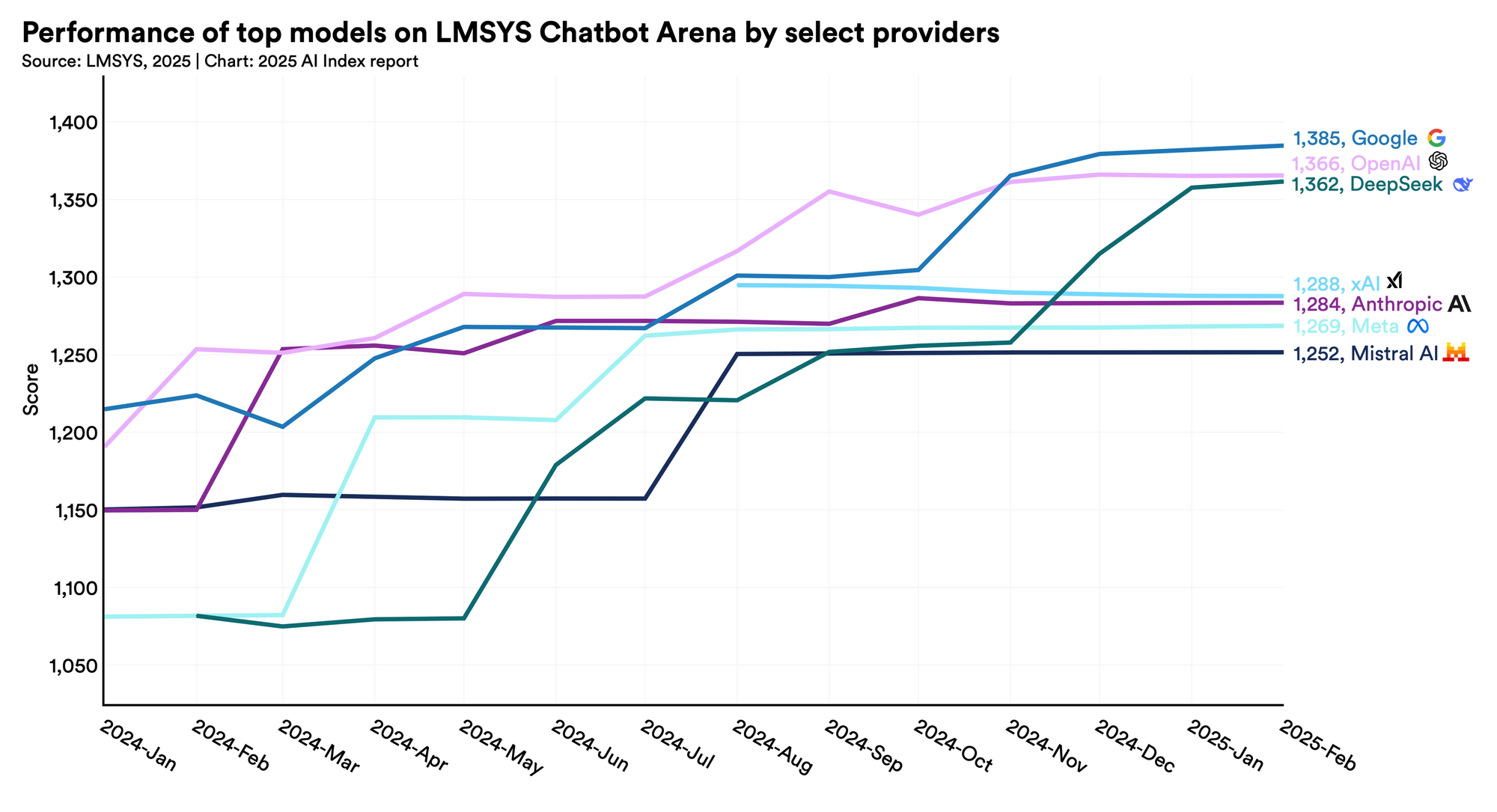
According to Stanford's 2025 AI Index Report, the Elo score gap between the top-ranked and tenth-ranked model on the Chatbot Arena leaderboard — the human-preference benchmark powered by over five million user votes — shrank from 11.9% to just 5.4% in a single year. The gap between the top two models dropped from 4.9% to 0.7% over the same period. Meanwhile, on the MMLU benchmark, which tests knowledge across dozens of academic domains, the performance difference between the best open-weight and best proprietary models collapsed from 17.5 percentage points to roughly 0.3 in 2025.
For context: in 2022, achieving a score above 60% on MMLU required a model with at least 540 billion parameters. By 2024, Microsoft's Phi-3 Mini managed the same threshold with just 3.8 billion. That is a 142-fold reduction in model size for equivalent benchmark performance. The efficiency gains happening inside open-source AI development are not incremental. They are structural.
This is the story of how free models broke the proprietary advantage, why it happened so fast, and what it means if you are building, investing, or deploying AI right now.
What Changed, and When
The acceleration has roots in early 2023, when Meta released the first LLaMA weights to researchers. Within four months, the open-source community had instruction-tuned LLaMA into Vicuna, a conversational model that researchers at UC Berkeley and Carnegie Mellon claimed achieved roughly 90% of ChatGPT's quality. The speed of that replication rattled closed-model labs. A leaked internal Google memo from that period captured the mood plainly: open-source models were "lapping" the large labs in iteration speed, and no amount of proprietary infrastructure would change that dynamic permanently.
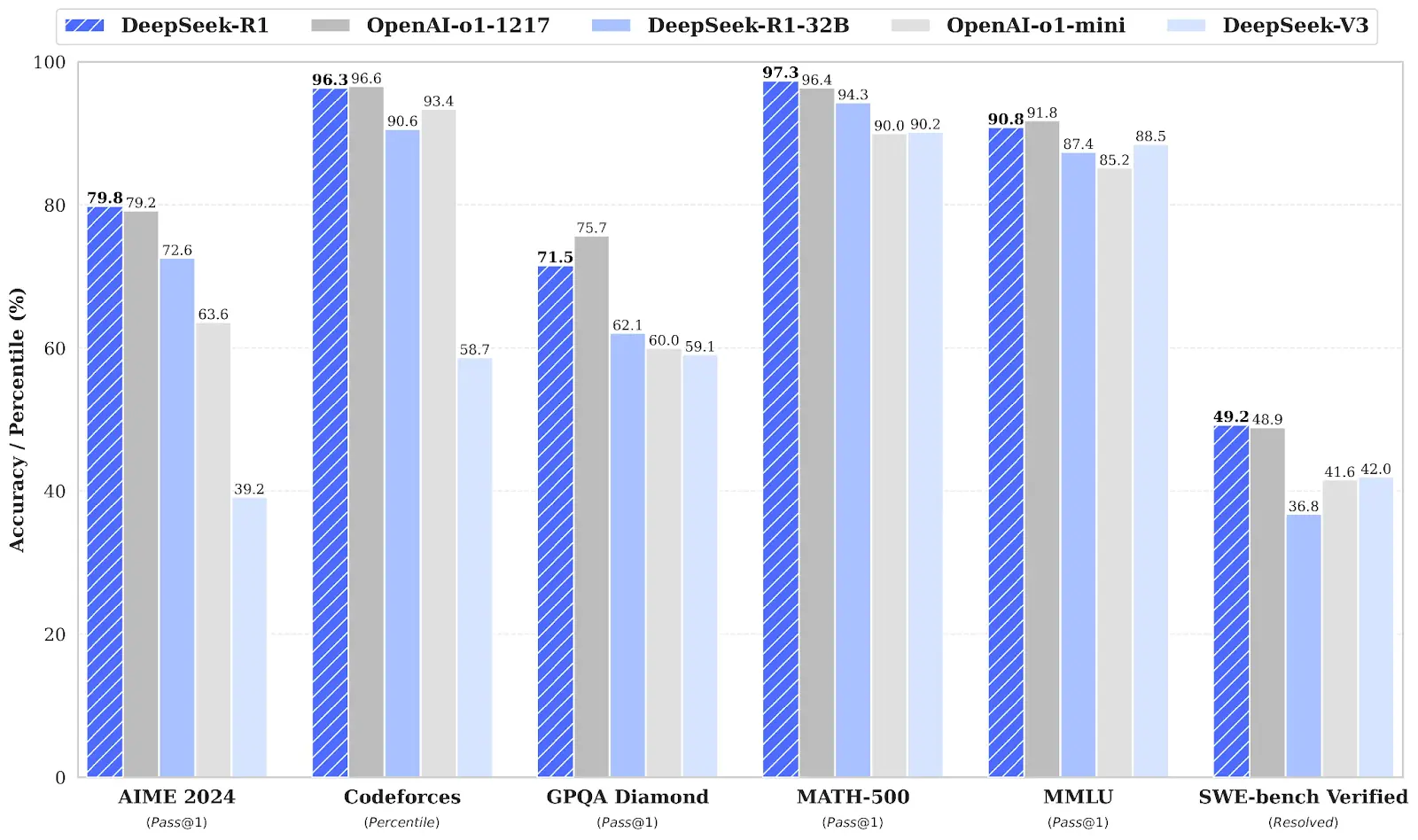
The real inflection point came in January 2025, when DeepSeek released R1, a reasoning-focused model built for a reported cost under six million dollars. For reference, GPT-4's training cost was estimated in the hundreds of millions. DeepSeek R1 matched OpenAI's o1 on key reasoning benchmarks. The AI industry had a genuine shock moment. Not because the model existed, but because of what it cost to build.
By mid-2025, Alibaba's Qwen3-235B was matching or beating GPT-4o on most public benchmarks while activating only 22 billion of its 235 billion parameters per inference pass, a technique called Mixture-of-Experts that dramatically cuts compute costs. Meta's Llama 4 Scout arrived with a 10 million token context window, large enough to process roughly 7,500 pages of text in a single session, and it ran on a single H100 GPU. Moonshot AI's Kimi K2, with around one trillion total parameters but only 32 billion active at inference, posted scores on agentic task benchmarks that met or exceeded several paid proprietary models.
The calendar matters here. These releases did not trickle in over five years. They arrived within roughly twelve months of each other.
How Open-Weight Models Compete Without Infinite Compute
Understanding why the gap closed requires looking at the architectural and training innovations behind these models, not just the benchmark scores.
Mixture-of-Experts Architecture
Traditional dense transformers activate every parameter on every token. If a model has 70 billion parameters, all 70 billion are in play every time the model processes a word. Mixture-of-Experts models route each token to a subset of specialized "expert" sub-networks. Qwen3-235B activates 22 billion parameters per token, not 235 billion. DeepSeek V3.2 activates 37 billion of its 671 billion. The result is frontier-level output at a fraction of the inference compute.
This is not a shortcut. It is a smarter architecture. And it allows open-source labs with more constrained budgets to build models that punch significantly above their operational weight class.
Efficiency at Training Time
DeepSeek's training efficiency was reported at roughly 180,000 H800 GPU hours per trillion training tokens. By contrast, frontier proprietary models have historically required far more compute. The gap in training costs is closing through better data curation, improved reinforcement learning from human feedback pipelines, and refined post-training techniques that coax more capability out of smaller base models.
The Post-Training Flywheel
Qwen3's July 2025 thinking update demonstrated something important: base model weights are only part of the story. Post-training, which includes reinforcement learning from human feedback, direct preference optimization, and chain-of-thought fine-tuning, can substantially upgrade a model's effective performance without retraining from scratch. Open-source communities have built robust post-training toolchains. The Hugging Face ecosystem, tools like OpenLLM, and deployment frameworks like Ray Serve mean that improvements compound quickly and publicly.
Why It Matters Right Now
The benchmark numbers are interesting. The business and ecosystem implications are what actually change behavior.
For Startups and Developers
Running a product on GPT-4-class intelligence used to mean accepting OpenAI's API pricing, latency, and terms. Today, a startup can self-host Llama 4 Scout or Qwen3, run it on a single H100, and access comparable capability with no per-token API cost and full control over the data pipeline. DeepSeek V3.2 API pricing has been reported at as low as $0.07 per million tokens with cache hits. GPT-4's pricing at scale runs meaningfully higher.
This is not a marginal cost difference. For a company making tens of millions of API calls per month, the difference between $0.07 and $15 per million tokens is an existential one for the unit economics.
For Enterprises
Data sovereignty has been a persistent friction point for enterprise AI adoption. Healthcare, finance, and legal sectors often cannot send sensitive data to third-party API endpoints. Self-hosted open-weight models eliminate that friction entirely. The model runs inside your infrastructure. The data never leaves. This was always theoretically possible with open-source AI, but performance parity with proprietary models was the missing condition. That condition is now met for most use cases.
For the Competitive Landscape
The arrival of Llama 4 Scout hitting 38.1% on LiveCodeBench, outperforming GPT-4o's 32.3% on the same benchmark, is not just a bragging point for Meta's research team. It is a signal to every organization that relies on proprietary model APIs for a technical moat. The moat is eroding in real time.
The Players Reshaping the Market
Meta and the Llama Ecosystem
Meta's decision to release Llama weights publicly was consequential in ways the company probably did not fully anticipate in 2023. Llama 3, particularly the 405 billion parameter version, demonstrated that open-source AI could rival GPT-4 on complex reasoning tasks. Llama 4 Scout extended that by dramatically expanding context length and improving coding benchmarks. Meta's motivation is strategic rather than altruistic: commoditizing the AI model layer benefits companies that compete on distribution and infrastructure, which is precisely what Meta does.
DeepSeek
The Chinese AI lab arrived with less fanfare than the American giants but delivered some of the year's most technically significant work. DeepSeek R1's sub-$6 million training cost and competitive o1-level reasoning triggered genuine reappraisal inside major American labs about how efficiently high-performance models could be trained. DeepSeek V3.2 added specialized sparse attention mechanisms that improved long-context efficiency by a reported 50%. For developers evaluating cost per reasoning operation, DeepSeek's numbers are hard to ignore.
Alibaba's Qwen Team
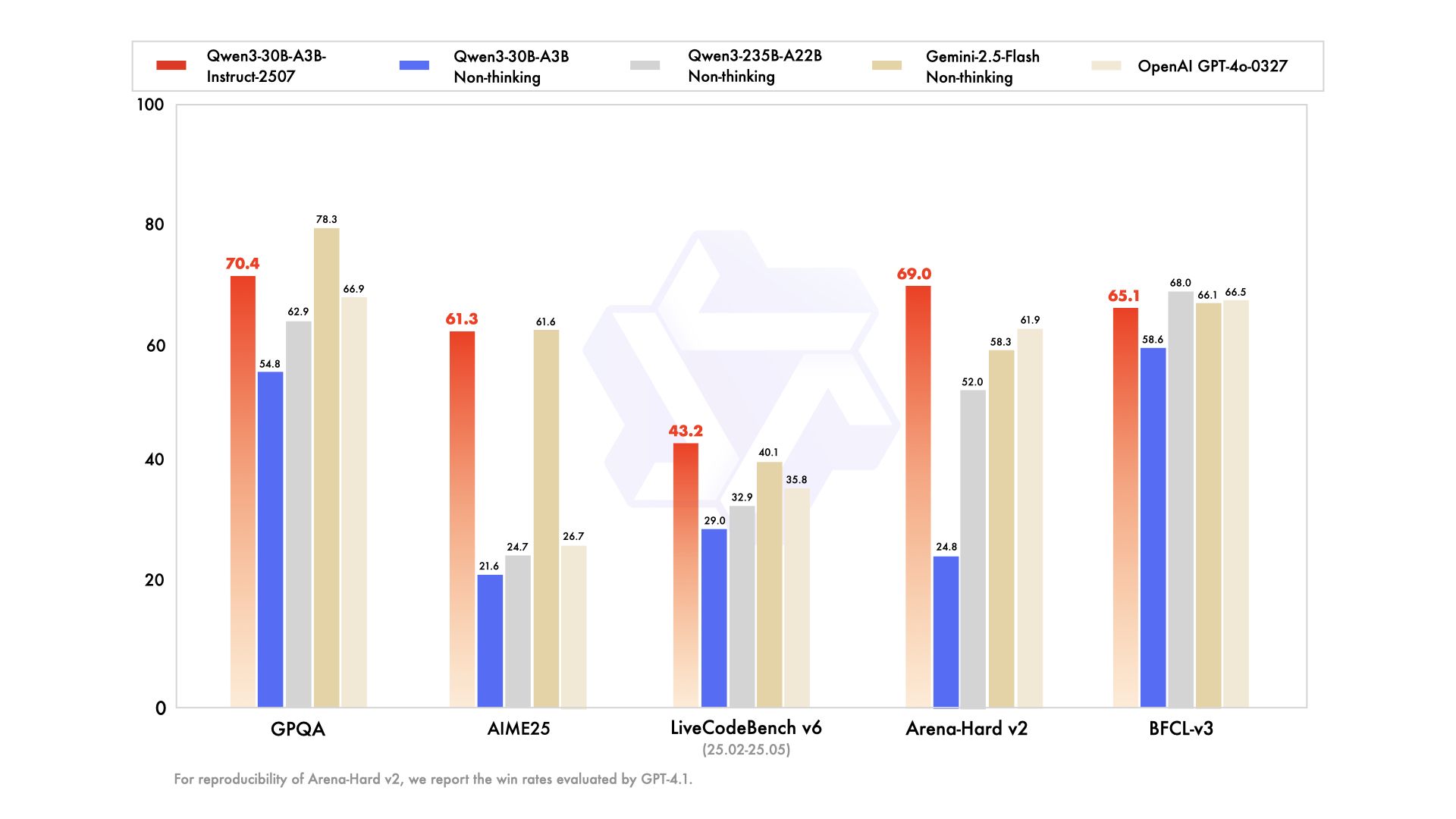
Qwen3 has become one of the most capable open-weight model families available. The 235 billion parameter Mixture-of-Experts model scored 85.7 on the AIME 2024 math benchmark and 81.5 on AIME 2025, with its thinking mode reaching 92.3 on the harder 2025 problems. For coding specifically, it achieved 74.8 on LiveCodeBench v6. These are not scores a reasonable person would describe as behind proprietary models. They are competitive with the best available systems.
Microsoft and the Phi Series
Microsoft's Phi-3 family proved something distinct from the giants: that small models trained on carefully curated data can outperform large models trained on noisy web crawls. Phi-3 Mini, at 3.8 billion parameters, achieves GPT-3.5-class performance. The implication is that efficient data curation is as important as scale. For edge deployment on laptops, phones, and embedded systems, this matters enormously.
The Risks and Limitations That Still Exist
Benchmark parity does not mean these models are identical to proprietary systems in every real-world scenario. It is worth being direct about the gaps that remain.
- Reliability and consistency remain harder to guarantee in open-weight models without specialized post-deployment monitoring infrastructure. Closed APIs provide hosted reliability, rate limiting, moderation layers, and enterprise SLAs that an organization must build from scratch with self-hosted models.
- Safety alignment varies significantly across open-weight releases. Some models are released with minimal safety tuning, which creates risk for consumer-facing deployments. Responsible use requires additional investment in red-teaming, fine-tuning for safety, and content moderation layers.
- Support and maintenance fall entirely on the deploying organization. There is no support contract. When Hugging Face or Meta releases a new version, migration is the deploying team's problem to manage.
- Multimodal capability, particularly deep visual reasoning and audio understanding at frontier quality, remains an area where closed models like Gemini Ultra and GPT-4V have historically held an advantage. Open-weight multimodal models are improving rapidly, but the very highest end of multimodal performance still leans proprietary as of early 2026.
Finally, benchmark gaming is a real concern. As open-source models are increasingly evaluated against specific public benchmarks, there is an incentive, conscious or not, for training data to overlap with benchmark distributions. Some of the headline numbers may reflect overfitting to benchmark format rather than genuine general capability. This does not invalidate the trend but warrants healthy skepticism about any single benchmark result.
What This Means for Builders and Buyers
If you are building an AI product today, the calculus that existed in 2022 and 2023 — default to GPT-4, iterate, and hope the costs become manageable — no longer holds.
The practical evaluation framework has changed. For most applications in the median complexity range, open-weight models are adequate. For high-stakes, reliability-critical applications at the extreme frontier of reasoning complexity, proprietary models still offer an edge, though it is narrowing. For any application involving sensitive data that cannot leave your infrastructure, open-weight deployment is often the only viable path.
Cost modeling has to be part of the evaluation now. A product that sends 50 million tokens per day to a proprietary API at $15 per million is spending $750,000 per day. The same workload on a self-hosted Qwen3 or DeepSeek deployment costs a fraction of that in infrastructure. The ROI math on building internal model infrastructure has changed fundamentally.
Investor attention is shifting accordingly. The open-source AI layer itself is difficult to monetize directly, but infrastructure, tooling, fine-tuning services, and deployment platforms built around open-weight models represent a significant market forming right now.
The Bigger Picture: What Comes Next
The trajectory of the last twelve months suggests the remaining performance gap between open and closed systems will continue to compress. The architectural innovations that drove DeepSeek and Qwen's efficiency gains are publicly described in research papers. Open-source teams are iterating on them. The post-training toolchains are maturing. The hardware to run frontier-class models is becoming more accessible.
The Stanford AI Index's observation that the gap between the top-ranked and tenth-ranked model on Chatbot Arena narrowed from 11.9% to 5.4% in one year is probably understating the pace at which open models will continue to close ground. The models releasing in the first quarter of 2026 already include further context window expansions beyond Llama 4 Scout's 10 million token ceiling and improved agentic tool-use capabilities across multiple open-weight families.
The parallel to Linux is imperfect but instructive. Linux did not replace every closed operating system. But it captured the infrastructure that mattered most: servers, cloud compute, mobile devices. The question for proprietary AI labs is not whether open-weight models will be competitive. They already are. The question is which layers of the AI stack remain genuinely differentiated, defensible, and worth paying a premium for. That list is getting shorter.
Frequently Asked Questions
Are open-source AI models as good as GPT-4?
For many real-world tasks, yes. Models like Meta's Llama 4 Scout, Alibaba's Qwen3-235B, and DeepSeek V3.2 match or exceed GPT-4 on standard benchmarks including MMLU, LiveCodeBench, and AIME math problems. On Chatbot Arena, the human-preference benchmark, the gap between the best open-weight and best proprietary models narrowed from 8% to 1.7% between January 2024 and February 2025. The most significant remaining advantage for proprietary models is in enterprise-grade reliability, support infrastructure, and certain multimodal tasks.
What is the best open-source AI model available right now?
As of early 2026, the leading open-weight models include Meta's Llama 4 Scout, Alibaba's Qwen3-235B, and DeepSeek V3.2. Each excels in different areas: Llama 4 Scout offers an unprecedented 10 million token context window, Qwen3-235B leads on reasoning benchmarks including math and coding, and DeepSeek V3.2 is optimized for cost-efficient long-context tasks and agentic workflows.
Why are open-source AI models so much cheaper to use?
Open-weight models can be self-hosted on your own infrastructure, eliminating per-token API fees. Models using Mixture-of-Experts architecture, like Qwen3-235B and DeepSeek V3.2, activate only a subset of parameters per inference pass, making them efficient to run even at scale. Operational costs come down to hardware and electricity rather than API subscriptions.
What is a Mixture-of-Experts model and why does it matter?
Mixture-of-Experts is an architecture where a model routes each input to a subset of specialized sub-networks rather than activating all parameters for every token. Qwen3-235B has 235 billion total parameters but only activates 22 billion per token. This allows the model to store broad knowledge in its full parameter set while performing inference cheaply. It is a key reason why open-source labs have been able to achieve frontier-level performance at significantly lower compute cost.
Can businesses safely deploy open-source AI models?
Yes, with appropriate due diligence. Open-weight models deployed on private infrastructure offer full data sovereignty, which is a significant advantage for healthcare, legal, and financial use cases. The trade-offs are that enterprises must build their own reliability, monitoring, moderation, and maintenance infrastructure rather than relying on a vendor's SLA. Safety alignment also varies across open-weight releases, so additional fine-tuning and red-teaming may be required.
What is the DeepSeek R1 and why did it cause a market reaction?
DeepSeek R1 is a reasoning-focused large language model released by a Chinese AI lab in January 2025. It attracted significant attention because it achieved performance comparable to OpenAI's o1 model on reasoning benchmarks while reportedly costing less than six million dollars to train, a fraction of the cost associated with comparable proprietary models. The release prompted reappraisal across the industry about the true cost floor for building frontier-level AI systems.
Will open-source AI eventually replace proprietary models?
Open-source models will not replace proprietary systems entirely, but they will capture the majority of use cases where hosted API reliability and cutting-edge multimodal capability are not essential requirements. The parallel to Linux is useful: Linux did not eliminate closed operating systems, but it became the dominant infrastructure layer for servers, cloud compute, and mobile devices. Open-weight models are on a similar trajectory for AI infrastructure.
How do open-source AI models handle data privacy compared to GPT-4?
Self-hosted open-weight models offer complete data privacy by design. Data processed by a locally hosted model never leaves your infrastructure and is never sent to a third-party API. GPT-4 and other hosted proprietary models process data on their providers' servers, subject to those providers' data handling policies, which creates compliance friction for regulated industries. For organizations with strict data residency requirements, open-weight deployment is often the only viable path.
Related Articles