Let me be real with you — choosing between Qwen 2.5 and Llama 3.3 isn't as straightforward as picking the one with the higher benchmark score. I've been knee-deep in open-source LLMs for over a year now, deploying them for everything from customer support bots to internal code assistants, and what I've learned is that the "best" model depends entirely on what you're actually building.
Why This Comparison Matters Right Now
Here's the thing: the open-source AI landscape has changed dramatically. Just a couple years ago, if you wanted cutting-edge AI performance, you had to shell out serious money to the big tech companies. Now? Some of the most capable models are completely free to use, modify, and deploy however you want.
According to recent industry reports, more than 60% of businesses are now using open-source LLMs for at least one AI application, up from about 25% in 2023. And the cost savings are substantial – companies using open-source models report cutting their AI expenses by 40% or more while achieving similar results to proprietary alternatives.
The two models that keep coming up in almost every conversation I have with developers and AI teams are Meta's Llama 3.3 and Alibaba's Qwen 2.5. They're both incredibly capable, but they take fundamentally different approaches to solving the same problems. Understanding those differences could save you months of experimentation and thousands of dollars in wasted compute.
Meet the Contenders: A Quick Introduction
Before we get into the nitty-gritty, let me give you the elevator pitch on each model.
Qwen 2.5 comes from Alibaba Cloud's Qwen team and represents their most ambitious release yet. The flagship model packs 72 billion parameters and was trained on a massive 18 trillion tokens – that's more than double what most competing models use. What makes Qwen special is its flexibility: the family includes models ranging from a tiny 0.5 billion parameters (perfect for mobile devices) all the way up to that 72B behemoth.
Llama 3.3, on the other hand, is Meta's latest contribution to the open-source AI community. It's a 70 billion parameter model that Meta claims delivers performance comparable to their much larger Llama 3.1 405B model — but at a fraction of the computational cost. The engineering achievement here is significant: getting 405B-level results from a 70B model means dramatically lower deployment costs for everyone.
Both models support 128K token context windows (that's roughly 96,000 words), which means they can handle substantial documents, codebases, or conversation histories without losing track of what you're discussing.
Benchmark Performance Deep Dive
Alright, let's talk benchmarks. I know, I know — benchmarks don't tell the whole story. But they do give us a useful starting point for comparison, especially when we're looking at specific capabilities.
General Knowledge and Reasoning
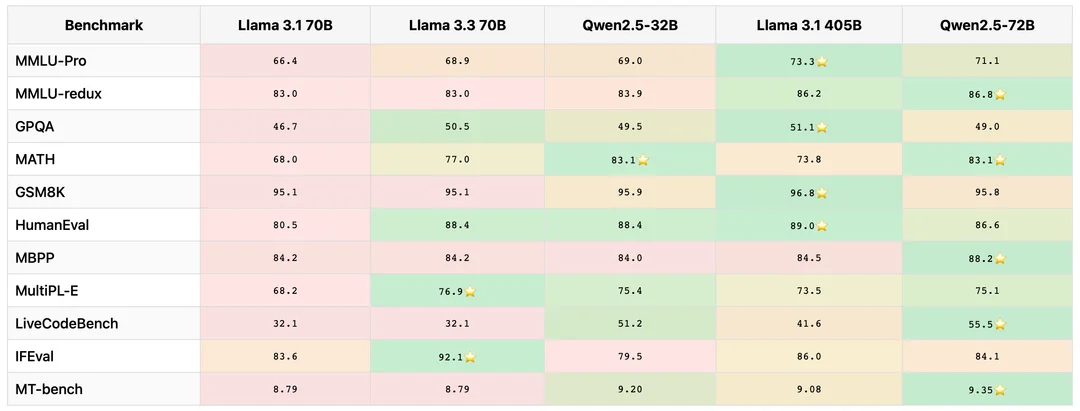
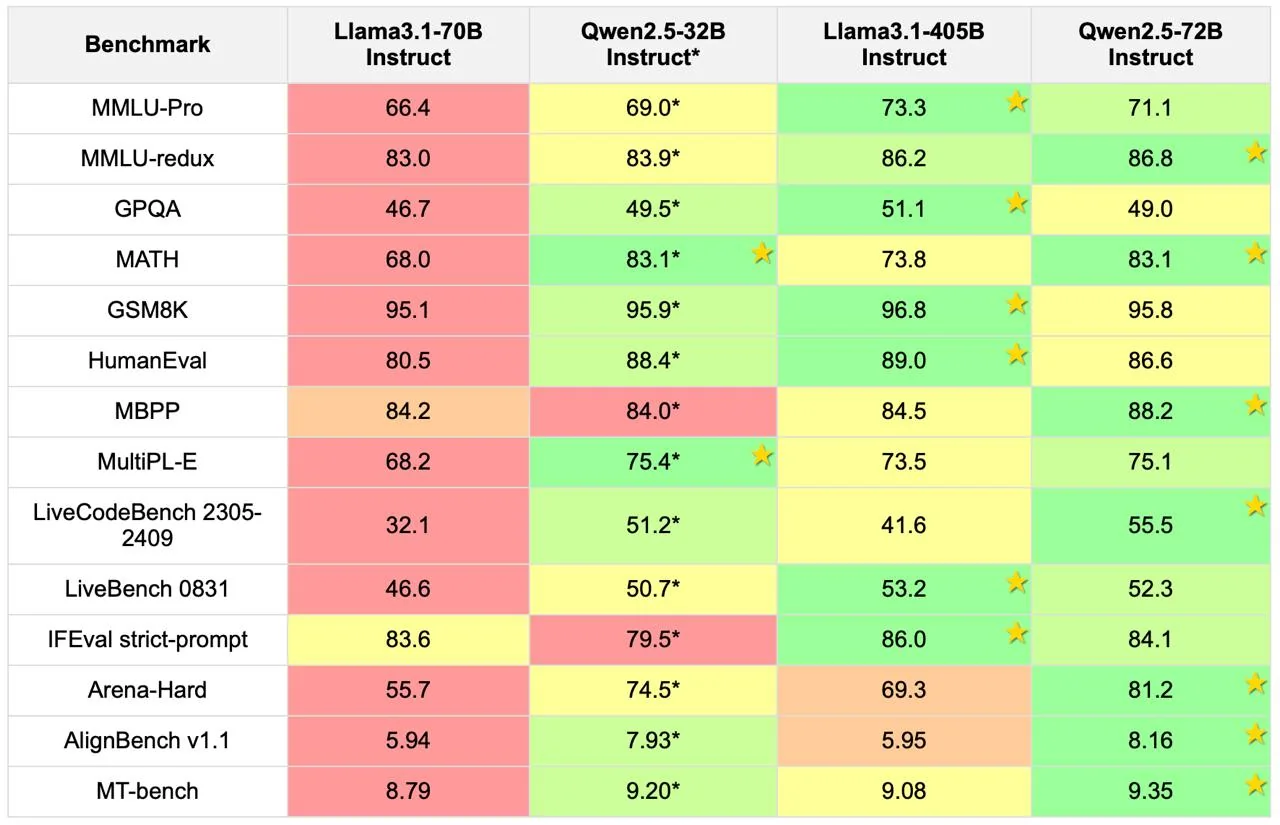
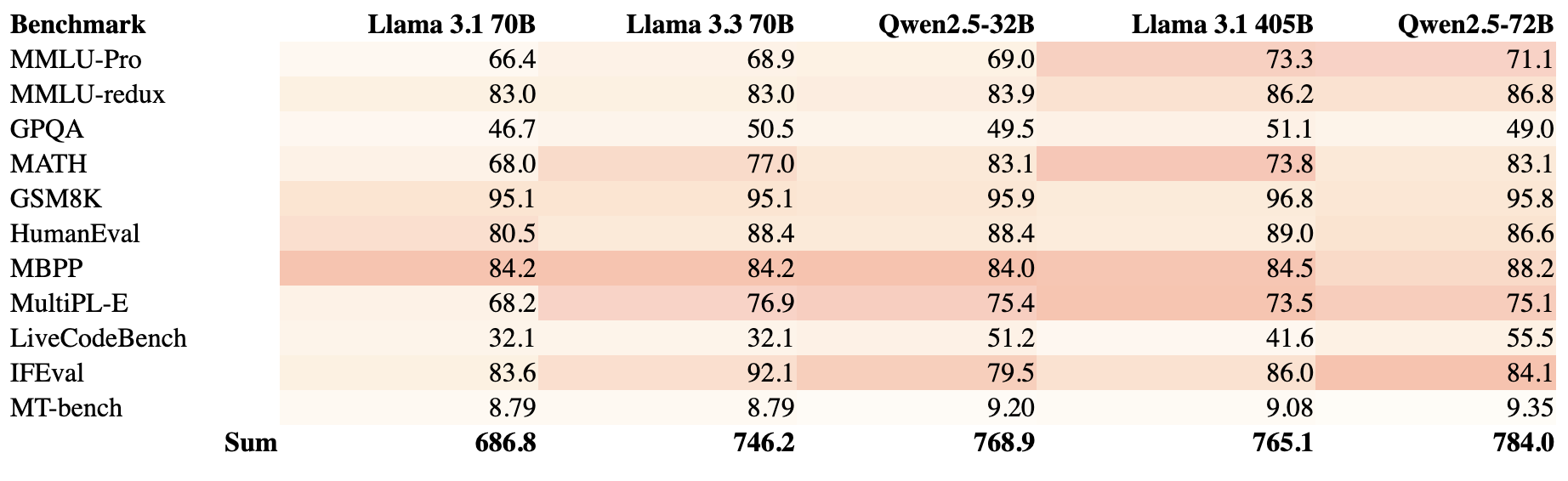
On the MMLU benchmark, which tests general knowledge across dozens of subjects, both models perform impressively. Qwen 2.5-72B scores around 86.1, while Llama 3.3 70B comes in at about 86.0. For all practical purposes, that's a tie.
Where things get interesting is on MMLU Pro, a more challenging version of the test. Llama 3.3 scores 68.9 here, which beats its predecessor (Llama 3.1 70B at 66.4) but still trails some of the larger models. Qwen holds its own in this territory as well.
For general-purpose knowledge tasks – answering questions, providing information, engaging in discussions, both models are more than capable. You won't go wrong with either one.
Mathematical Reasoning
This is where the models start to differentiate themselves. Qwen 2.5 has been specifically enhanced with technology from Alibaba's dedicated math models, and it shows. On the MATH benchmark, Qwen 2.5-72B-Instruct scores an impressive 83.1, which represents a significant jump from previous generations.
Llama 3.3 70B scores 77.0 on the same benchmark still excellent performance that beats many competing models, but noticeably behind Qwen in this specific area.
If your application involves heavy mathematical reasoning – financial modeling, scientific calculations, engineering problems – Qwen has a measurable advantage here.
Coding Capabilities
Here's where the conversation gets really interesting, because the results flip depending on which benchmark you're looking at.
On HumanEval (which tests basic code generation), Llama 3.3 scores 88.4, slightly edging out its competition. Meta has clearly invested heavily in improving Llama's coding abilities, and the model excels at producing clean, functional code across multiple programming languages.
However, Qwen 2.5 comes with a secret weapon: Qwen2.5-Coder, a specialized variant that absolutely crushes it on coding benchmarks. The main Qwen 2.5-72B-Instruct model scores 88.2 on MBPP (another coding benchmark), benefiting from the technical breakthroughs developed for that coder-specific model.
In my hands-on testing, I've found that both models produce excellent code for straightforward tasks. The differences become more apparent on complex, multi-file refactoring tasks or when you need the model to understand intricate codebases. Qwen seems to handle structured data and JSON manipulation particularly well, while Llama often produces cleaner documentation and comments.
Instruction Following
This might be the most underrated benchmark category. A model that follows instructions precisely is far more useful in production than one that performs well on academic tests but ignores half of what you ask it to do.
Llama 3.3 truly shines here, scoring 92.1 on IFEval – a benchmark specifically designed to test how well models follow detailed instructions. This score actually beats Llama 3.1 405B (88.6), which is remarkable considering the size difference. It also outperforms GPT-4o (84.6) on this metric.
In practical terms, when you tell Llama 3.3 "give me a bullet list with 5 items, each one sentence long," it actually does that. This level of controllability is incredibly valuable for production applications where consistent output formatting matters.
Multilingual Performance
If you're building for a global audience, this section deserves your full attention.
Qwen 2.5 supports over 29 languages out of the box, with particularly strong performance in Asian languages like Chinese, Japanese, and Korean. This shouldn't surprise anyone — Alibaba built Qwen with global markets in mind, and they've invested heavily in multilingual training data.
Llama 3.3 supports 8 languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. The model performs exceptionally well in English and delivers solid results in these other supported languages. On the Multilingual MGSM benchmark, Llama 3.3 scores 91.1, which is competitive with Qwen's multilingual performance.
Here's my honest assessment: if you need Asian language support, especially Chinese, Japanese, or Korean – Qwen is the clear choice. For European languages and English, both models perform admirably. I've seen testing that shows Qwen handles multilingual text extraction and translation tasks with noticeably higher accuracy, particularly when dealing with mixed-language content.
Beyond Benchmarks: What Actually Matters in Production
Okay, enough with the numbers. Let me share what I've actually observed deploying these models in real-world scenarios.
Response Quality and Tone
Llama 3.3 tends to produce more concise, structured responses. When you ask it a question, it gets to the point quickly. This makes it excellent for applications where users want fast, direct answers – customer support, quick lookups, command-line tools.
Qwen 2.5 often provides more comprehensive responses with additional context. It has a tendency to explain its reasoning, which can be helpful for educational applications but might feel verbose if you just want a quick answer. The model also excels at generating long-form content, supporting outputs up to 8K tokens with coherent structure throughout.
Neither approach is objectively "better" – it depends on your use case.
Handling Structured Data
This is an area where Qwen 2.5 consistently outperforms in my testing. The model has been specifically trained to understand and generate structured data, including tables, JSON objects, and formatted outputs.
I've worked on projects involving document processing, data extraction from invoices, and API response generation. Qwen handles these tasks more reliably, producing properly formatted JSON with fewer syntax errors and better consistency across repeated runs.
Llama 3.3 is certainly capable of working with structured data, but I've found it requires more careful prompting to achieve the same level of reliability.
Context Management
Both models support 128K token context windows, which is impressive. But how they handle that context differs.
In my testing with long documents, both models maintain coherent understanding throughout. Llama 3.3 shows slight preference for recent text in retrieval tasks (meaning it might weight information at the end of the context more heavily), while Qwen demonstrates more even attention across the full context window.
For applications involving long-form analysis – legal document review, research paper synthesis, extensive codebase understanding, this is worth considering in your evaluation.
Real-World Performance
Let me share some specific examples from my own deployments and from teams I've worked with.
Customer Support Application
I helped deploy both models for a mid-sized e-commerce company's customer support system. The goal was handling product inquiries, order status checks, and basic troubleshooting.
With Llama 3.3, we saw excellent performance on straightforward questions. Response times averaged 1.2 seconds, and the model consistently formatted answers according to our template requirements. Customer satisfaction scores were strong across the board.
With Qwen 2.5, we noticed particularly good handling of non-native English speakers' questions. The model seemed to better understand queries with grammatical variations and provided helpful responses even when the input wasn't perfectly formed. This mattered for the company's international customer base.
The verdict for this use case: slight edge to Llama 3.3 for pure English support, but Qwen 2.5 performed better when the customer base included non-native speakers.
Internal Code Review Tool
A software development team I advised built an internal code review assistant using both models in parallel testing.
Llama 3.3 excelled at identifying conventional bugs and suggesting standard fixes. Its suggestions were concise and directly actionable. Developers appreciated that it didn't over-explain obvious issues.
Qwen 2.5 provided more comprehensive analysis, often catching edge cases that Llama missed. However, its responses were sometimes too detailed for quick code reviews. The team ended up preferring Qwen for initial deep analysis and Llama for quick sanity checks.
Document Processing Pipeline
For a legal tech application processing contracts, we tested both models on entity extraction, clause summarization, and risk identification.
Qwen 2.5 dramatically outperformed on structured extraction tasks. Its ability to produce consistent JSON output with correct formatting was noticeably better. When asked to extract specific fields from contracts, Qwen achieved about 94% accuracy compared to Llama's 87%.
Llama 3.3 produced more readable summaries when asked to explain clauses in plain language. The writing quality was slightly more polished for end-user consumption.
The team ultimately used Qwen for the data extraction pipeline and Llama for generating human-readable reports — a hybrid approach that played to each model's strengths.
Deployment and Infrastructure Reality
Let's talk about what it actually costs to run these models. Because having access to a great model means nothing if you can't afford to deploy it.
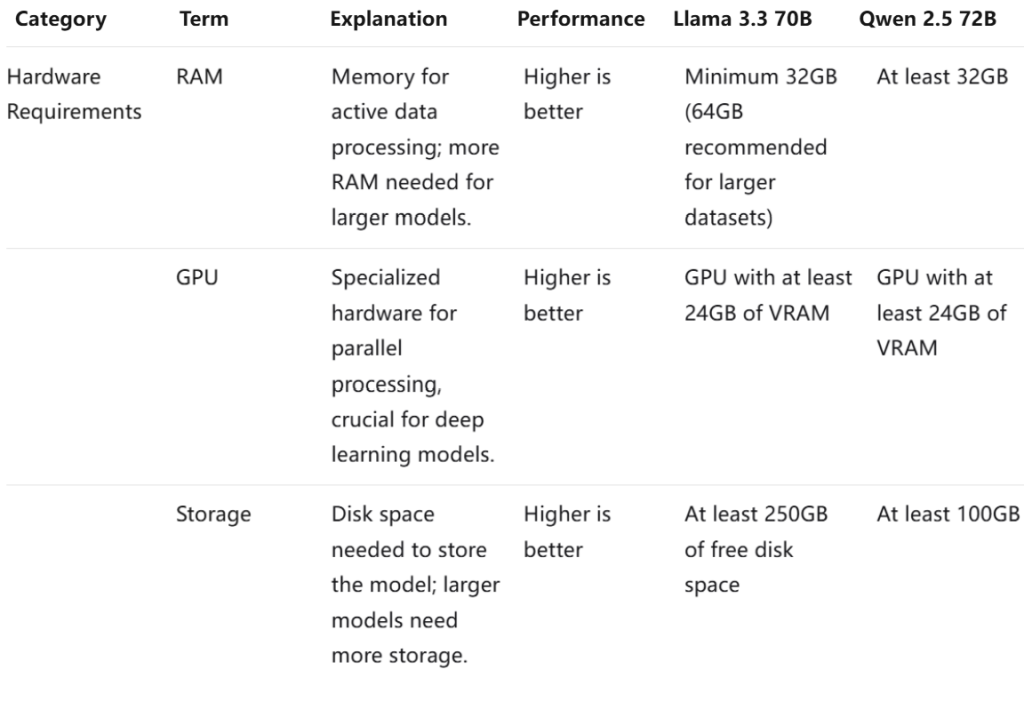
Hardware Requirements
Both the Qwen 2.5-72B and Llama 3.3 70B are, well, big models. Running them at full precision requires multiple high-end GPUs. We're talking 4x NVIDIA A100 80GB cards or equivalent hardware for comfortable inference.
However, quantization changes the equation significantly. With 4-bit quantization (using methods like GPTQ or AWQ), you can run these models on much more modest hardware. A single NVIDIA A100 40GB or even a consumer RTX 4090 can handle quantized versions of these models, though with some performance tradeoffs.
Llama 3.3 has a slight edge in deployment flexibility because Meta's models have been extensively optimized by the open-source community. Tools like vLLM, TensorRT-LLM, and llama.cpp have mature support for Llama models, often with better performance than Qwen equivalents.
That said, Qwen's compatibility with major frameworks has improved dramatically, and most production inference engines now support both model families.
Inference Speed
According to independent benchmarks, Llama 3.3 70B achieves around 276 tokens per second on Groq hardware, which is notably faster than its predecessor. This speed advantage makes Llama attractive for real-time applications where latency is critical.
Qwen 2.5-72B is competitive on inference speed but doesn't quite match Llama's optimized performance on most hardware configurations. The difference isn't dramatic, both models are fast enough for production use — but it's worth noting if you're building latency-sensitive applications.
API Costs (If You Don't Want to Self-Host)
Not everyone wants to manage GPU infrastructure. If you prefer to access these models through APIs, here's the landscape:
For Qwen, Alibaba Cloud offers access through their DashScope platform, with Qwen-Plus and Qwen-Turbo variants priced competitively against GPT-4o-mini and GPT-4o respectively.
Llama 3.3 is available through numerous providers: Amazon Bedrock, Microsoft Azure, Groq, Together.ai, Fireworks, and many others. The competitive market means prices have fallen significantly. As of early 2026, you can access Llama 3.3 70B for as little as $0.60 per million tokens through some providers.
The multi-provider availability for Llama gives you negotiating leverage and protection against vendor lock-in, which is a genuine business advantage.
Licensing
Open-source licensing can be a minefield. Let me break down what you need to know.
Qwen 2.5 uses a tiered licensing approach. Most model sizes (0.5B, 1.5B, 7B, 14B, 32B) are released under Apache 2.0, which is about as permissive as licenses get — use it for anything, commercial or otherwise. The 3B and 72B models have more restrictive terms under Alibaba's Qwen License, which still permits commercial use but includes additional conditions.
Llama 3.3 uses Meta's custom "Llama License," which allows commercial use but has some important restrictions. If your product or service has more than 700 million monthly active users, you need a separate license from Meta. The license also prohibits using Llama outputs to train competing language models.
For most companies, both licenses are perfectly workable. But if you're building something intended for massive scale or planning to train your own models, read the full license documents carefully.
Use Case Recommendations
After months of testing and deployment, here's my practical guidance on when to choose each model.
Choose Qwen 2.5 When...
- Building multilingual applications, especially those serving Asian markets. Qwen's 29+ language support and superior performance on languages like Chinese, Japanese, and Korean makes it the obvious choice for international products.
- Working with structured data like JSON, tables, forms, or APIs. Qwen consistently produces better-formatted structured outputs with fewer errors.
- Building mathematical or analytical applications. Whether you're creating financial tools, scientific calculators, or data analysis pipelines, Qwen's enhanced math capabilities provide measurable advantages.
- You need model size flexibility. The Qwen family spans from 0.5B (runs on phones) to 72B (maximum capability), letting you match deployment constraints to your specific hardware. Want to run something on an edge device? Qwen 2.5-3B delivers surprisingly good performance. Need maximum capability? Scale up to 72B.
- Generating long-form content. Qwen's training specifically improved coherence over extended outputs, making it well-suited for report generation, article writing, or documentation tasks.
Choose Llama 3.3 When...
- Building English-first applications where instruction following precision matters. Llama's 92.1 IFEval score means it does what you tell it to do, consistently.
- Deploying on optimized infrastructure. If you're using Groq, SambaNova, or other specialized AI hardware, Llama models often have better optimization support and faster inference.
- You want maximum ecosystem support. Llama has been around longer and has the largest open-source ecosystem. More tutorials, more fine-tuning recipes, more community-built tools, more everything.
- Working with multiple API providers and wanting to avoid vendor lock-in. Llama's availability across dozens of providers gives you options.
- Building coding assistants for English-language documentation and comments. Llama often produces cleaner, more readable code documentation.
- Your team has experience with Meta's tooling. If you've deployed Llama 2 or earlier Llama 3 versions, the upgrade path to 3.3 is straightforward.
When Either Model Works Well
- Customer support chatbots – both models handle conversational AI capably.
- Document summarization – both can process long documents and produce coherent summaries.
- General Q&A systems – knowledge quality is similar across both models.
- Code generation for common tasks – both produce functional code in popular languages.
- Content moderation and classification – both can be fine-tuned for these tasks effectively.
How to Get Started: Practical First Steps
If you're ready to start experimenting, here's my recommended path for each model.
Getting Started with Qwen 2.5
The fastest way to test Qwen is through Alibaba's ModelScope platform or directly via Hugging Face. For local deployment, I recommend starting with Ollama:
ollama pull qwen2.5:7b
ollama run qwen2.5:7b
This gives you the 7B model, which is a good balance between capability and resource requirements for initial testing. Scale up to larger variants once you've validated your use case.
For production API access, check out DashScope (Alibaba's API platform) or providers like Together.ai and Novita AI that offer Qwen hosting.
Getting Started with Llama 3.3
Similarly, Ollama is the easiest entry point:
ollama pull llama3.3:70b
ollama run llama3.3:70b
For the full 70B model, you'll need substantial hardware. Start with a quantized version if you're on consumer-grade equipment:
ollama pull llama3.3:70b-q4_0
API access is available through Amazon Bedrock, Azure AI, Groq, Fireworks, Together.ai, and numerous other providers. Groq is particularly impressive for Llama inference speed.
Testing Methodology
Here's how I recommend evaluating these models for your specific use case:
First, create a test suite of 20-50 prompts that represent your actual use case. Don't use generic benchmarks — use your real data, your real questions, your real formatting requirements.
Second, run both models against your test suite and blindly evaluate the outputs. Have team members score responses without knowing which model produced them.
Third, measure what matters for your deployment: response latency, token usage (affects costs), output consistency across runs, error rates on structured outputs.
Finally, run a small pilot with real users before committing to either model at scale. User feedback often surfaces issues that automated testing misses.
The Specialized Variants
Both Qwen and Llama have specialized variants worth knowing about.
Qwen's Specialist Models
Qwen2.5-Coder is specifically trained for programming tasks. If you're building developer tools, code assistants, or anything that requires heavy code generation, this variant delivers measurably better results than the base model. It supports over 300 programming languages and achieves state-of-the-art performance on coding benchmarks.
Qwen2.5-Math focuses on mathematical reasoning. For applications in education, finance, scientific computing, or anywhere else that requires precise mathematical work, this specialist model is worth evaluating.
Qwen2.5-VL adds vision capabilities, allowing the model to understand images alongside text. Document understanding, chart analysis, and UI interpretation become possible with this multimodal variant.
Llama's Extended Family
While Llama 3.3 itself is text-only, the broader Llama 3.2 family includes vision-capable variants at 11B and 90B parameter sizes. If you need multimodal capabilities within the Llama ecosystem, these are your options.
Meta has also indicated continued development toward larger models and expanded multimodal capabilities, so watch this space.
What's Coming Next
The open-source LLM landscape moves fast. Here's what's on the horizon that might affect your decision.
Alibaba has already released Qwen 3 (launched April 2026), which pushes capabilities even further with models up to 235B parameters using Mixture of Experts architecture. If you invest in Qwen 2.5 infrastructure now, upgrading to Qwen 3 should be relatively seamless.
Meta continues to develop larger and more capable Llama models. The recently released Llama 4 variants (Scout and Maverick) push context lengths up to 10 million tokens and introduce native multimodal capabilities.
The broader trend is clear: open-source models are closing the gap with proprietary alternatives rapidly. The model you choose today will likely be superseded by something better within 12-18 months. This argues for building flexible infrastructure that can swap models as needed, rather than building deep dependencies on any single model family.
Cost Analysis
Let me share some actual deployment cost data to help you plan.
Self-Hosted Scenario
Running either model on 4x A100 80GB GPUs (a common configuration):
Cloud GPU costs: approximately $12-15/hour through major cloud providers, working out to roughly $8,700-11,000 per month for 24/7 operation.
At moderate utilization (around 400 requests per second handling 300 tokens each), your effective cost per 1,000 tokens falls to roughly $0.01-0.02 — dramatically cheaper than API access at scale.
API-Based Scenario
For Llama 3.3 70B through providers like Groq or Together.ai, expect pricing around $0.60-0.90 per million tokens for input and $0.80-1.20 per million tokens for output.
Qwen pricing through DashScope is competitive, with Qwen-Turbo priced to compete with GPT-4o-mini.
Breakeven Analysis
The math typically works like this: if you're processing more than 2-3 million tokens per day consistently, self-hosting starts making financial sense. Below that threshold, API access is usually more economical when you factor in operational overhead.
But don't forget the non-monetary factors: self-hosting gives you data privacy (nothing leaves your infrastructure), customization capability (fine-tune freely), and independence from provider outages or policy changes.
Common Mistakes to Avoid
I've seen teams make these mistakes repeatedly. Learn from their pain:
Mistake 1: Choosing based solely on benchmarks. Benchmark scores are useful, but they don't capture everything that matters in production. A model that scores 2% lower on MMLU but follows your specific instructions better is often the right choice.
Mistake 2: Ignoring quantization options. Many teams assume they need full-precision models, then struggle with hardware costs. Modern quantization techniques preserve most model quality while dramatically reducing requirements.
Mistake 3: Not testing with real data. Generic test prompts don't reveal how the model handles your specific domain, terminology, or edge cases. Always build a custom evaluation suite.
Mistake 4: Forgetting about inference optimization. Raw model capability doesn't matter if your deployment is slow or expensive. Invest time in frameworks like vLLM or TensorRT-LLM that optimize inference performance.
Mistake 5: Locking in too early. The landscape changes rapidly. Build your systems to swap models without major rewrites, because what's best today might not be best in six months.
Fine-Tuning and Customization: Taking It Further
One of the major advantages of open-source models is the ability to fine-tune them for your specific use case. Let me walk you through what that looks like for both models.
Fine-Tuning Llama 3.3
The Llama ecosystem has the most mature fine-tuning tooling available. Libraries like Hugging Face's TRL, Axolotl, and LLaMA-Factory provide straightforward paths to customization.
For most use cases, I recommend starting with LoRA (Low-Rank Adaptation) fine-tuning. This approach modifies only a small subset of model parameters, dramatically reducing computational requirements. You can fine-tune Llama 3.3 70B using LoRA on a single A100 80GB GPU, which would be impossible with full fine-tuning.
The general workflow looks like this: prepare your training data in conversation format, configure your LoRA parameters (rank, alpha, target modules), run training for typically 1-3 epochs, merge the adapter weights with the base model, and deploy.
Teams I've worked with have achieved excellent results fine-tuning Llama for domain-specific applications with as few as 1,000-5,000 high-quality examples. Quality matters more than quantity for fine-tuning data.
Fine-Tuning Qwen 2.5
Qwen fine-tuning follows similar principles but has some unique considerations. Alibaba provides official fine-tuning guides optimized for their model architecture.
Qwen works particularly well with supervised fine-tuning (SFT) on instruction-following datasets. The model's architecture responds well to task-specific training, especially for structured output generation.
One approach I've seen work well is using Qwen's specialized variants (Coder, Math) as starting points for domain-specific fine-tuning. Instead of fine-tuning base Qwen for a coding application, starting from Qwen2.5-Coder can reduce the amount of training needed significantly.
The Qwen team has also released extensive documentation on using DPO (Direct Preference Optimization) and RLHF techniques with their models, which can help align model behavior with specific preferences.
When to Fine-Tune vs. Prompt Engineering
This is a question I get constantly. Here's my decision framework:
Consider prompt engineering first if you need quick iteration, have limited training data (under 500 examples), or want to maintain maximum flexibility. Good prompt engineering can achieve remarkable results without any model modification.
Move to fine-tuning when prompt engineering hits a ceiling, you have consistent formatting or style requirements, you need to inject domain-specific knowledge, or you want to optimize for inference efficiency by removing repetitive prompt instructions.
Many successful production systems use both: a fine-tuned model that has learned domain basics, combined with dynamic prompt engineering for specific query variations.
Security and Safety Considerations
Open-source models give you control, but that control comes with responsibility.
Data Privacy
With self-hosted models, your data never leaves your infrastructure. This is a massive advantage for applications handling sensitive information — healthcare, finance, legal, personal data.
However, you need to implement your own data handling policies. Consider:
- How long do you retain prompt/response logs?
- Who has access to the model and its outputs?
- How do you handle personally identifiable information in prompts?
- What safeguards prevent unauthorized model access?
Both Qwen and Llama can be deployed in air-gapped environments with zero external network access. This is impossible with cloud-based proprietary models.
Content Safety
Neither model comes with built-in content moderation at the level of commercial APIs. You're responsible for implementing appropriate safeguards.
Meta provides Llama Guard, a separate model specifically designed to classify inputs and outputs for safety. It can flag potentially harmful content, allowing you to filter before and after generation.
For Qwen, Alibaba provides guidelines for implementing content filters, though the tooling is less mature than Meta's offerings.
If you're building public-facing applications, budget time and resources for safety implementation. This is not optional — it's essential.
Model Security
Once you deploy a model, consider:
- Access control: Who can query the model?
- Rate limiting: Prevent abuse and denial-of-service
- Input validation: Screen for injection attacks
- Output monitoring: Log and review outputs for anomalies
- Model integrity: Ensure the model weights haven't been tampered with
Both model families have been extensively audited by the security research community, which is one advantage of open development.
Frequently Asked Questions
Which model is better for coding, Qwen 2.5 or Llama 3.3?
Both are excellent for coding. Llama 3.3 slightly edges out on HumanEval benchmarks and tends to produce cleaner code comments and documentation. Qwen 2.5, especially with the Qwen2.5-Coder variant, excels at complex multi-file refactoring tasks and structured data manipulation. For pure code generation in English, they're very close. For code involving multiple languages or heavy JSON/API work, I'd lean toward Qwen.
Can I run Qwen 2.5-72B or Llama 3.3 70B on my local machine?
It depends on your hardware. For full-precision inference, you need serious GPU power — think 4x A100 40GB or equivalent. With 4-bit quantization, a single high-end consumer GPU like the RTX 4090 (24GB VRAM) can run these models, though at reduced speed. For the 7B variants of either model, most modern GPUs with 8GB+ VRAM can handle quantized versions comfortably.
Which model has better multilingual support?
Qwen 2.5 supports over 29 languages with particularly strong performance in Asian languages including Chinese, Japanese, and Korean. Llama 3.3 officially supports 8 languages (English, German, French, Italian, Portuguese, Hindi, Spanish, Thai) with excellent performance. If you need Asian language support, Qwen is the clear winner. For European languages, both perform well.
What's the cost difference between Qwen 2.5 and Llama 3.3?
For API access, both are priced competitively — typically $0.60-1.00 per million tokens through various providers. For self-hosting, costs are similar since both have comparable hardware requirements. Llama has slightly better optimization support which can reduce inference costs marginally, but the difference isn't dramatic.
Is Qwen 2.5 or Llama 3.3 better for enterprise use?
Both are enterprise-ready. Llama 3.3's strength lies in its extensive ecosystem support, numerous hosting options, and strong instruction-following capability. Qwen 2.5 offers advantages in multilingual deployment, structured data handling, and mathematical applications. Your choice should depend on specific enterprise requirements rather than abstract "enterprise readiness."
Can I fine-tune Qwen 2.5 and Llama 3.3?
Yes, both models support fine-tuning. The open-source community has developed extensive fine-tuning tools for both model families, including efficient methods like LoRA and QLoRA that reduce computational requirements significantly. Llama has more mature fine-tuning tooling due to its longer presence in the market, but Qwen fine-tuning support has improved substantially.
Which model is faster for inference?
Llama 3.3 generally achieves faster inference on optimized hardware, with independent benchmarks showing around 276 tokens per second on Groq hardware — about 25 tokens/second faster than Llama 3.1 70B. Qwen 2.5 is competitive but doesn't quite match Llama's optimized performance on most configurations. For latency-critical applications, Llama has a slight edge.
What's the context window limit for both models?
Both Qwen 2.5 and Llama 3.3 support 128K token context windows, which is approximately 96,000 words. This is sufficient for most practical applications including long document analysis, extensive codebases, and complex multi-turn conversations.
Should I choose based on the company behind the model (Meta vs Alibaba)?
While geopolitical considerations exist for some organizations, both companies have committed to open-source development and have large communities using their models. For most users, the technical capabilities of the models matter more than corporate provenance. However, if your organization has specific policies about technology sourcing, consult with your compliance team.
Which model is more likely to continue receiving updates?
Both companies are heavily invested in their respective model families. Meta continues releasing Llama iterations (Llama 3.1, 3.2, 3.3, and now Llama 4). Alibaba maintains active development with Qwen 2, 2.5, and now Qwen 3. Both ecosystems appear healthy and growing. Building model-agnostic infrastructure that can adapt to updates from either family is the wisest approach.
How do Qwen 2.5 and Llama 3.3 compare to GPT-4 or Claude?
Honestly, the gap has narrowed dramatically. For many tasks, these open-source models perform comparably to GPT-4. Where proprietary models still have an edge tends to be in areas like nuanced instruction following, complex multi-step reasoning, and graceful handling of ambiguous queries. However, for the majority of practical business applications, either Qwen 2.5 or Llama 3.3 will deliver satisfactory results at a fraction of the cost.
Can I use both models together in the same application?
Absolutely, and many teams do exactly this. You might route simple queries to a smaller, faster model (like Qwen 2.5-7B or Llama 3.2-3B), use Llama 3.3 for tasks requiring precise instruction following, and use Qwen 2.5-72B for complex analytical tasks or multilingual work. This "model routing" approach can optimize both cost and quality. Just make sure your infrastructure supports multiple model backends.
What about smaller models in each family for resource-constrained deployments?
Both families offer excellent smaller variants. Qwen 2.5 has models at 0.5B, 1.5B, 3B, 7B, 14B, and 32B parameters. Llama 3.2 includes 1B and 3B variants designed for mobile and edge deployment. For many applications, the 7B or 14B models provide an excellent balance of capability and efficiency. I've seen teams achieve impressive results with Qwen 2.5-7B for tasks that don't require maximum capability.
How do I handle model updates when new versions are released?
Build your systems with abstraction layers between your application logic and the model interface. Use frameworks like LangChain or LlamaIndex that provide model-agnostic APIs. Maintain comprehensive evaluation test suites so you can quickly verify new model versions against your requirements. Consider running parallel deployments during transition periods to compare real-world performance before fully switching.
Is there a performance difference when running these models on AMD vs NVIDIA GPUs?
NVIDIA GPUs currently have better software support for both models, with optimized kernels in frameworks like TensorRT-LLM. AMD GPUs work via ROCm and can run these models, but typically with 10-30% performance penalty compared to equivalent NVIDIA hardware. If you're committed to AMD for cost reasons, both models will work — just factor in the performance difference when sizing your infrastructure.
Wrap up
If you've read this far, you understand that there's no universally "better" choice between Qwen 2.5 and Llama 3.3. Both are remarkable achievements that would have seemed impossible just a few years ago.
My honest recommendation is this: if you have the resources, test both models with your actual use case before committing. Spend a week running your real prompts through both systems and measuring what matters for your specific application.
If you need to make a quick decision without extensive testing, here's my simplified guidance:
Choose Llama 3.3 if you prioritize instruction following precision, need maximum ecosystem support, primarily work in English and European languages, or want the fastest inference on optimized hardware.
Choose Qwen 2.5 if you need strong multilingual support (especially Asian languages), work heavily with structured data and JSON, require mathematical reasoning, or want flexibility in model sizes from mobile-ready to maximum capability.
The beautiful thing about open-source AI is that your choice isn't permanent. Build your systems with modularity in mind, and you can adapt as both model families continue to improve. The winner in 2026 might not be the winner in 2027 and that's exactly how healthy competition should work.
Related Articles