

What if you could ask three of the world's most powerful AI models the same question at the same time and get a single answer that shows where they agree and where they disagree?
That's exactly what Perplexity just shipped. On February 5, 2026, the company launched Model Council, a feature that runs your query through GPT-5.2, Claude Opus 4.6, and Gemini 3.0 in parallel, then synthesizes their responses into one coherent answer. The system highlights points of consensus while flagging areas where the models reach different conclusions.
The idea addresses a fundamental problem with AI research: every model has blind spots. It might overlook context, lean toward certain perspectives, or fill gaps with confident guesses. For decisions that actually matter, that's a serious risk. Model Council turns model variability from a bug into a feature by letting you see where the frontier models converge and where they diverge.
How Model Council Actually Works
The mechanics are straightforward. When you select Model Council in Perplexity's interface, your query gets dispatched simultaneously to three frontier AI models. Each model generates its response independently, using Perplexity's integrated tools like web search and code execution where applicable.

Once all three responses come back, a "synthesizer model" (currently Claude Opus 4.5 by default) reviews the outputs. But this isn't a simple merge. The synthesizer identifies areas of agreement, highlights points of disagreement, surfaces unique insights from individual models, and evaluates the strength of evidence each model presents.
The final response arrives as a synthesized answer with structured indicators showing where models converge or diverge. When all three models reach similar conclusions, you can move forward with higher confidence. When they disagree, you know the question might be more complex than it appears and warrants deeper investigation.
The Case for Multi-Model Research
The approach reflects a growing reality in AI: there is no single best model for everything. GPT-5.2 might excel at certain reasoning tasks while Claude Opus 4.6 handles nuanced analysis better. Gemini 3.0 brings different training data and architectural choices that lead to different conclusions on the same inputs.
Until now, getting multiple perspectives meant copying your question across different platforms and manually comparing results. Model Council automates this process and, more importantly, structures the comparison in a useful way.
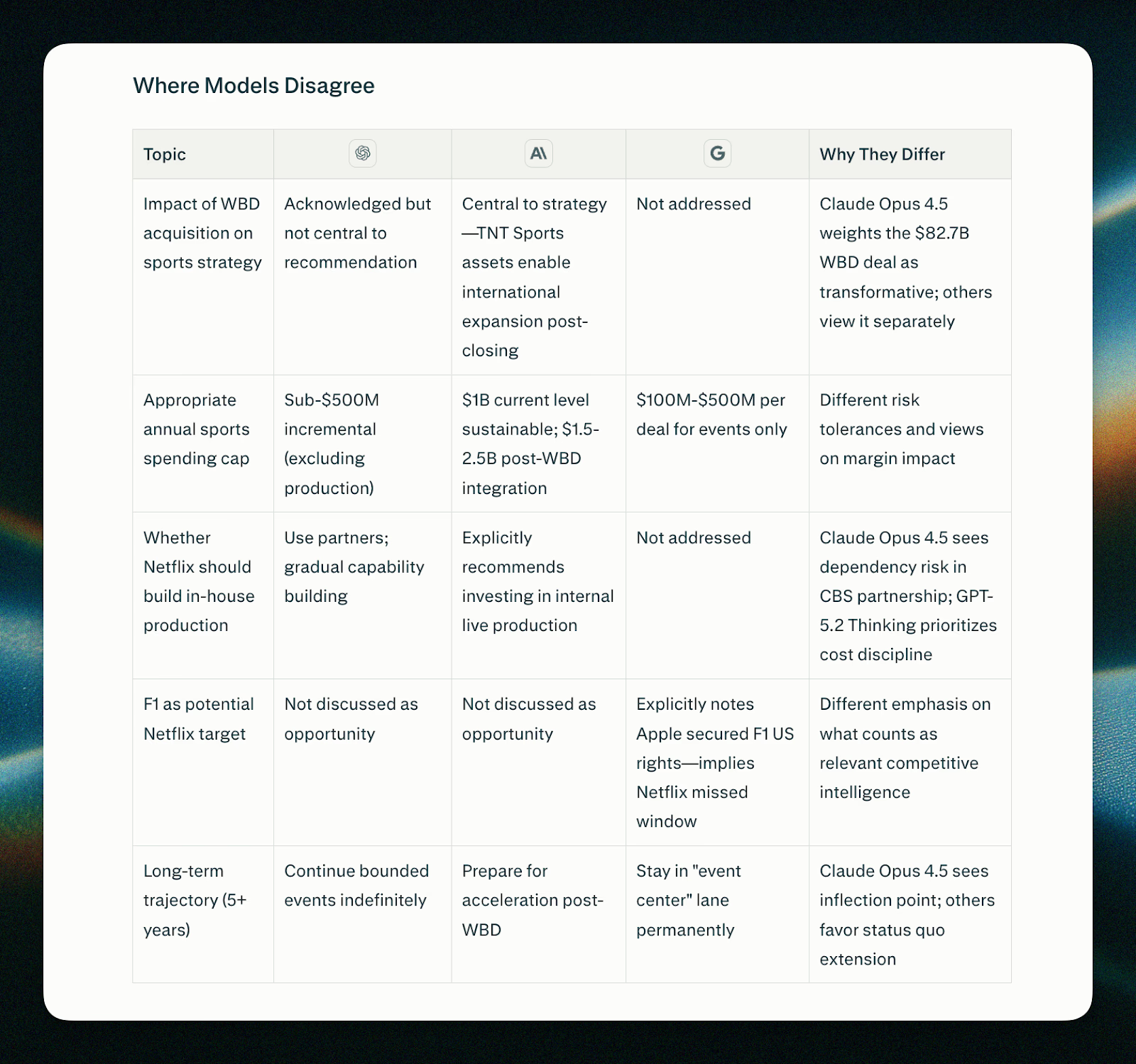
Consider the difference between convergence and divergence as signals. If 3 independently trained frontier models, each with billions of parameters and different training approaches, arrive at the same conclusion, that convergence suggests higher reliability. The answer isn't guaranteed correct, but multiple strong models independently reaching similar conclusions is meaningful evidence.
Divergence works as an early warning system. If GPT says one thing while Claude contradicts it, the synthesizer flags that disagreement rather than papering over it. This transparency matters because it changes how users should interpret the response. A confident single-model answer feels authoritative even when the model might be wrong. A response that explicitly shows disagreement among frontier models tells you to verify further before acting.
Multi-model systems have already demonstrated their value in benchmarks. In past submissions to challenges like ARC-AGI, multi-model setups have outperformed many single-model runs. Running the same task through multiple models in parallel and comparing results appears to improve overall accuracy, particularly on complex reasoning tasks.
Where Model Council Adds Value
Perplexity positions Model Council for high-stakes scenarios where accuracy and perspective diversity matter most. The company highlights several use cases.
- Investment research benefits from balanced views on stocks, markets, and financial decisions where model bias could prove costly. If you're researching whether to invest in a particular sector, getting three independent AI perspectives and seeing where they align or conflict provides better input for your decision than trusting any single model.
- Strategic planning and business analysis similarly benefit from multiple angles. Complex business problems rarely have single correct answers, and different models might emphasize different factors or risks. Model Council surfaces those varying perspectives rather than collapsing them into artificial consensus.
- Fact-checking and verification become more robust when multiple models can corroborate or challenge claims. If you're trying to verify a specific piece of information, three models agreeing provides stronger evidence than one model's confident assertion.
- Comparative analysis and research that requires weighing different viewpoints works naturally with the multi-model approach. Rather than getting a single model's synthesis of competing perspectives, you get three independent syntheses that the system then compares.
The common thread across these use cases is that they're situations where being wrong carries real consequences. For casual questions, a single model response is usually fine. For decisions involving money, strategy, or published research, the additional verification layer Model Council provides becomes valuable.
What Model Council Doesn't Do
- Model Council is slower than standard queries because it runs 3 models in parallel and then synthesizes results. If speed matters more than verification depth, the feature adds unnecessary latency.
- The synthesizer model faces a genuinely difficult task: resolving conflicts between frontier models without simply picking a winner or hiding disagreement. How well this works in practice across different query types remains to be seen. Perplexity's success here depends on the synthesizer accurately representing where models agree versus where it's smoothing over meaningful differences.
- Model Council also doesn't replace human judgment. It's designed to support verification and deeper analysis, not to make final decisions. The feature gives you better information about what AI models think, but you still need to evaluate that information in the context of your specific situation.
Access is currently limited to Perplexity Max and Enterprise Max subscribers using the web version. The feature isn't available on free tiers or mobile apps at launch.
The Competitive Landscape
Model Council positions Perplexity distinctively in a crowded AI market. While OpenAI, Anthropic, and Google each push their own models as the best option, Perplexity takes a model-agnostic stance. The company's CEO has emphasized that Perplexity doesn't favor any particular company's model:
"We simply want to take the best parts of every frontier model available at that specific moment."
This neutrality becomes a selling point. Users paying for Perplexity Max get access to multiple frontier models in one subscription rather than paying separately for ChatGPT Plus, Claude Pro, and Gemini Advanced. Model Council extends that value proposition by letting users leverage all those models simultaneously for a single query.

The approach also differentiates Perplexity from single-model platforms like Anthropic Console or OpenAI's offerings. Those platforms optimize for their own models; Perplexity optimizes for giving users the best answer regardless of which model produces it.
Whether this model-agnostic positioning represents a sustainable competitive advantage depends on how users value verification versus the deep integration and specialized features that single-model platforms can offer. For research-heavy use cases where accuracy matters most, Model Council makes a compelling case for the multi-model approach.
The Bigger Picture
Model Council represents a philosophical shift in how we think about AI research tools. The traditional framing treats AI models as oracles: you ask a question, you get an answer, you trust the answer (or you don't). Model Council reframes AI responses as perspectives to be compared and evaluated.
This shift matters because it aligns with how researchers and analysts already work. Good research involves consulting multiple sources, identifying where they agree, and investigating where they conflict. Model Council embeds that methodology directly into the interface rather than requiring users to implement it manually.
The feature also acknowledges something the AI industry has been slow to admit publicly: no single model is consistently best. Performance varies by task, by question, by domain. Users benefit from access to multiple models and transparency about how their outputs compare.
Whether Model Council proves genuinely useful will depend on execution details: how well the synthesizer handles disagreement, whether the convergence and divergence signals actually improve decision-making, and whether users find the slower response times acceptable for the added verification.
But the direction seems right. As AI models become more capable and more integrated into important decisions, tools that help users evaluate and verify AI outputs become increasingly valuable. Model Council is Perplexity's bet that the future of AI research isn't a single authoritative voice but a council of perspectives where reliability comes from comparison, synthesis, and transparent variance.
FAQ
What is Perplexity Model Council?
Model Council is a multi-model research feature launched by Perplexity on February 5, 2026. It runs your query through three frontier AI models simultaneously, such as GPT-5.2, Claude Opus 4.6, and Gemini 3.0, then synthesizes their responses into a single answer that shows where models agree and where they disagree.
How does Model Council work?
When you select Model Council, your query is sent to three AI models in parallel. Each generates an independent response. A synthesizer model (currently Claude Opus 4.5) then reviews all outputs, resolves conflicts where possible, identifies areas of agreement and disagreement, and produces a unified answer with structured indicators showing convergence and divergence.
Which AI models does Model Council use?
Model Council can use frontier models available on Perplexity, including GPT-5.2 from OpenAI, Claude Opus 4.6 from Anthropic, and Gemini 3.0 from Google. The specific models may vary based on availability and user selection.
Who can access Model Council?
Model Council is available only to Perplexity Max and Enterprise Max subscribers using the web version. It is not currently available on free tiers or mobile applications.
How much does Model Council cost?
Model Council is included with Perplexity Max subscriptions, which cost $20 per month. There is no additional charge for using Model Council beyond the existing subscription fee.
Is Model Council faster than regular Perplexity searches?
No. Model Council is typically slower than standard queries because it runs three models in parallel and then synthesizes the results. The feature prioritizes verification depth over speed.
What is Model Council best used for?
Model Council is designed for high-stakes research where accuracy matters: investment research, strategic planning, fact-checking, comparative analysis, and any scenario where model bias could lead to costly mistakes. It's less suited for casual questions where speed matters more than verification.
How does Model Council reduce AI hallucinations?
By querying multiple models independently and comparing their outputs, Model Council can identify when models disagree on factual claims. If three frontier models converge on the same answer, it provides higher confidence. If they diverge, the disagreement signals that the information should be verified further before acting on it.
Can I choose which models Model Council uses?
Users can select from available frontier models on Perplexity. The specific combination may include options like Claude Opus 4.5 or 4.6, GPT-5.2, and Gemini 3.0 or Gemini 3 Pro, depending on current availability.
How is Model Council different from switching between models manually?
Previously, getting multiple AI perspectives required copying your question into different platforms and manually comparing results. Model Council automates this process, runs models simultaneously rather than sequentially, and structures the comparison by explicitly showing where models agree and disagree rather than leaving users to identify differences themselves.
Related Articles













