

Jensen Huang has a habit of turning chip launches into cultural events, and his CES 2026 keynote in Las Vegas was no different. Standing in front of a packed room at the Fontainebleau, he declared that AI has entered its "industrial phase" — and then unveiled the hardware he says will power it.
The platform is called Vera Rubin, named after the pioneering American astronomer who discovered evidence for dark matter. It is Nvidia's successor to Blackwell, the current generation of AI chips that sent the company's valuation past $3 trillion and made it, briefly, the most valuable company in the world. And according to the numbers Huang put on stage, it is not a modest upgrade.

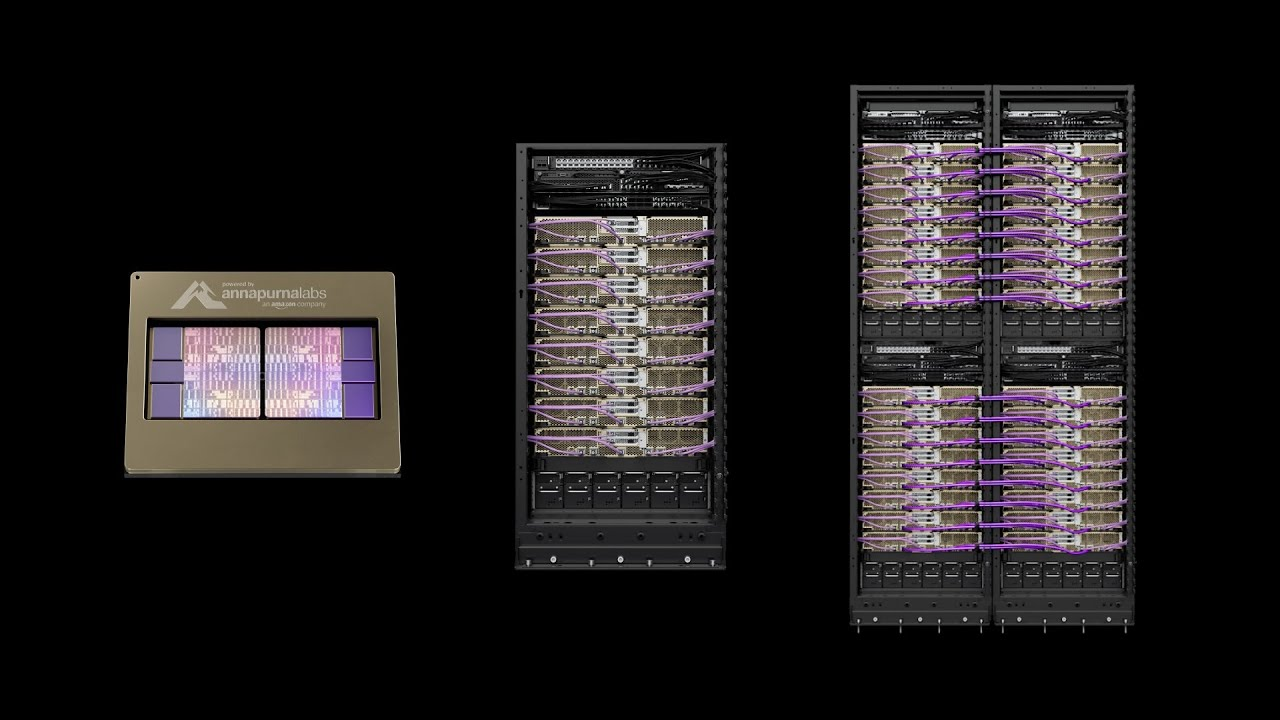
Compared with the Nvidia Blackwell platform, Rubin delivers up to a 10x reduction in inference token cost and a 4x reduction in the number of GPUs needed to train MoE models. A single NVL72 rack packs 72 Rubin GPUs into one liquid-cooled system that Nvidia calls a rack-scale supercomputer.
Those numbers sound impressive in a press release. What they actually mean for the AI products people use every day — and why they matter even if you have no intention of ever buying a data center — is a different and more interesting conversation.
What Vera Rubin Actually Is
Before getting into the implications, it helps to understand what Nvidia has built, because Vera Rubin is not simply a faster GPU. It is a rethinking of what a computing platform means.
It starts with six chips, not one
The Rubin platform is made up of six chips: the Vera CPU, the Rubin GPU, the NVLink 6 Switch, the ConnectX-9 SuperNIC, the BlueField-4 DPU, and the Spectrum-6 Ethernet Switch. Every one of those components was designed in concert with the others — what Nvidia calls "extreme codesign" — rather than optimized independently and bolted together afterward.
The distinction matters more than it sounds. In previous generations, the GPU was the center of gravity and everything else was infrastructure built around it. With Rubin, GPUs, CPUs, networking, security, software, power delivery, and cooling are architected together as a single system, treating the data center — not a single GPU server — as the unit of compute.
The Vera Rubin Superchip
At the heart of the platform is the Vera Rubin Superchip, which combines one Vera CPU and two Rubin GPUs into a single processor package.
The Rubin GPU is listed at 336 billion transistors built from two reticle dies, delivering up to 50 petaflops of NVFP4 inference performance and 35 petaflops of NVFP4 training performance — 5x and 3.5x higher than Blackwell respectively. Each GPU package carries 288GB of HBM4 memory at 22 TB/s of memory bandwidth.
On the CPU side, the Vera CPU is built on custom Arm "Olympus" cores at 227 billion transistors, running 88 cores and 176 threads using Nvidia Spatial Multi-Threading, with up to 1.5TB of LPDDR5x memory and 1.2 TB/s of memory bandwidth.
The NVL72 rack: 72 GPUs as one machine
The flagship system, the Vera Rubin NVL72, combines 72 Rubin GPUs and 36 Vera CPUs connected through NVLink 6, delivering 3.6 exaflops of NVFP4 inference performance, 20.7TB of HBM4 capacity, and 260 TB/s of scale-up bandwidth.
The rack is also 100 percent liquid cooled and features a cable-free modular tray design that Nvidia claims reduces installation time from two hours to five minutes compared to its Blackwell equivalent.

The key specs at a glance
| Metric | Rubin GPU | vs. Blackwell |
|---|---|---|
| Inference performance | 50 petaflops (FP4) | 5x improvement |
| Training performance | 35 petaflops (FP4) | 3.5x improvement |
| HBM4 memory per GPU | 288 GB | 1.5x more capacity |
| Memory bandwidth | 22 TB/s | 2.75x faster |
| GPU-to-GPU fabric | 3.6 TB/s (NVLink 6) | 2x faster |
| Inference token cost | — | 10x lower |
| GPUs to train same MoE | — | 4x fewer needed |
The "Trillion-Parameter" Problem — and Why It Matters
The phrase "trillion-parameter AI" shows up a lot in coverage of Vera Rubin, and it deserves a plain-English explanation, because the reason the chip was built the way it was is directly tied to where AI models are heading.
What parameters actually are
When an AI model is trained, it learns by adjusting billions of numerical values — called parameters — that encode relationships between concepts, words, images, and tasks. More parameters generally means a more capable, nuanced model. GPT-3 had 175 billion parameters. Current frontier models like GPT-4 and Claude 3 Opus are estimated to run in the hundreds of billions. The models being trained and deployed right now are already approaching the trillion-parameter range, and the next generation will push well beyond it.
The problem is that running a trillion-parameter model requires vast amounts of memory bandwidth — the speed at which data can be moved from storage to compute. If the GPU cannot be fed data fast enough, its processing cores sit idle, and money burns for nothing. The standout feature of Rubin's memory architecture is that eight stacks of HBM4 per GPU deliver 22 TB/s of bandwidth — a 2.8x improvement over Blackwell achieved entirely through silicon optimization, not compression or software workarounds.
The MoE shift
There is also a structural change in how cutting-edge AI models are built that Rubin is specifically designed to handle. Most of the largest models now use a "mixture-of-experts" architecture, or MoE, rather than activating every parameter for every query. In a MoE model, the system routes each query to a specialized subset of the model — a relevant "expert" — depending on the nature of the question. This makes it possible to scale up total model size without proportionally scaling up the compute cost of each inference.
But MoE models create a different problem: routing queries between experts requires enormous bandwidth between GPUs. Vera Rubin's NVLink 6 scale-up networking boosts per-GPU fabric bandwidth to 3.6 TB/s bidirectionally, addressing precisely that bottleneck.
What "agentic AI" demands
Nvidia is framing the Rubin platform as ideal for agentic AI, advanced reasoning models, and mixture-of-experts models, which combine a series of "expert" AIs and route queries to the appropriate one depending on the question a user asks.
Agentic AI — systems that take multi-step actions autonomously rather than just responding to a single prompt — represents the direction the industry is heading in 2026. When an AI agent browses the web, writes code, executes it, reads the output, and revises its approach across dozens of steps, it generates enormous amounts of intermediate computation that needs to be stored and retrieved rapidly. Modern AI workloads increasingly rely on reasoning and agentic models that execute multi-step inference over extremely long contexts, simultaneously stressing every layer of the platform: compute performance, GPU-to-GPU communication, interconnect latency, memory bandwidth, utilization efficiency, and power delivery.
Rubin was designed for exactly this workload profile — not the chatbot interactions of 2023, but the persistent, reasoning, multi-step agents that AI companies are racing to deploy right now.
The Cost Equation: Why 10x Cheaper Tokens Changes Everything
The most consequential claim Nvidia made at CES 2026 is not the raw performance numbers. It is the cost figure.
Rubin promises a 10x reduction in the cost per inference token compared to Blackwell. To understand why that matters beyond a data center procurement spreadsheet, you need to understand what inference tokens cost today and what they represent in the broader AI economy.

Tokens are the unit of cost in AI
Every time you send a message to an AI assistant, generate an image, summarize a document, or run any AI-powered feature in any application, the underlying computation is measured in tokens. Tokens represent chunks of text, image data, or video frames that the model processes. Generating tokens costs money — compute time, electricity, hardware amortization — and that cost ultimately determines what AI products can charge, how often users can use them, and which use cases are economically viable to build at all.
When AI companies advertise their API pricing in dollars per million tokens, they are describing the downstream consequence of what their data center hardware costs. Lower hardware cost per token flows through to lower API pricing, which flows through to more applications being built, which flows through to more features reaching end users.
A 10x drop reshapes what is affordable to build
Training a 10-trillion-parameter mixture-of-experts model on 100 trillion tokens would require four times as many Blackwell GPUs as Rubin GPUs to hit the same one-month training window — a 75% reduction in hardware cost, power consumption, and data center footprint for the same outcome. On the inference side, cost per million tokens drops by 10x for reasoning workloads.
For developers building on top of AI APIs, this kind of cost reduction means that features which were previously too expensive to deploy at scale — long-context processing, multi-step reasoning chains, real-time video analysis — start to fall within economically viable territory. For end users, it means AI products that currently limit usage through expensive subscription tiers or aggressive rate limiting have more room to expand access without destroying their unit economics.
This is not a guaranteed outcome — hardware cost savings do not automatically pass through to consumers when the companies buying Rubin hardware also have enormous capital expenditure bills to service. But over time, cheaper infrastructure means cheaper AI, and the compounding effect of successive hardware generations each reducing costs by an order of magnitude is how AI goes from specialized professional tool to ambient utility.
Who Is Actually Getting These Chips
Vera Rubin is in full production as of early 2026, with partner systems — the NVL72 rack and HGX server platforms — expected to be available from cloud providers in the second half of 2026.
The cloud providers lining up
Among the first cloud providers to deploy Vera Rubin-based instances in 2026 will be AWS, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure, as well as Nvidia cloud partners CoreWeave, Lambda, Nebius, and Nscale.
Microsoft's commitment is particularly notable in scale. Microsoft will deploy Nvidia Vera Rubin NVL72 rack-scale systems as part of next-generation AI data centers, including future Fairwater AI superfactory sites, with plans to scale to hundreds of thousands of Nvidia Vera Rubin Superchips.
For most developers and enterprises, access to Rubin will come through cloud APIs rather than direct hardware procurement — the same way Blackwell and Hopper-class GPUs are already available through AWS, Azure, and Google Cloud today.
What Rubin Ultra means for the roadmap
Rubin is not the endpoint. Rubin will be followed by Rubin Ultra in the second half of 2027, which will feature four reticle-sized Rubin Ultra GPUs, 1TB of HBM4e, and will deliver 100 petaflops of FP4 performance.
Nvidia has committed to an annual cadence of new AI hardware generations, and the roadmap beyond Rubin already carries a name: Feynman, after physicist Richard Feynman, tentatively positioned for 2028. The pace of this cadence is itself a competitive strategy — by advancing annually, Nvidia makes it structurally difficult for any competitor to occupy the leading position long enough to erode its ecosystem advantage.
The Competitive Picture: AMD Is Gaining Ground, But the Gap Remains
Nvidia's dominance in AI compute hardware is well-documented, but 2026 is seeing more serious competition than any previous year.
AMD's Helios challenge

AMD also unveiled its Helios rack-scale system at CES 2026, designed to deliver maximum bandwidth and energy efficiency for trillion-parameter training. AMD's MI455X GPU carries 432GB of memory per unit, which exceeds Rubin's 288GB in raw capacity, though it lags on bandwidth and integrated ecosystem support.
The hardware gap between Nvidia and AMD has closed considerably from where it stood two years ago, when the H100 had no credible competition. But AMD still has ground to cover on the software ecosystem front. The company's HIP and ROCm libraries have come a long way since the MI300X debut, but Nvidia's CUDA ecosystem — the software layer that most AI developers write to — remains the dominant target for AI frameworks, libraries, and tooling.
Switching from Nvidia to AMD is not just a hardware decision. It requires rewriting or revalidating software stacks, which creates switching costs that pure hardware spec comparisons do not capture.
The custom silicon wildcard
Google and Amazon have both announced that Anthropic will expand the use of their respective custom processors, which the AI company already uses to power its Claude platform. Google's TPUs and Amazon's Trainium chips are not designed to compete with Nvidia across the full breadth of AI workloads, but for specific inference tasks at hyperscaler scale, they can offer compelling economics. The more these companies develop capable custom silicon, the more selective their Nvidia GPU purchasing becomes.
Nvidia's structural moat
None of this changes the fundamental dynamic in the near term. Nvidia's CUDA ecosystem, combined with the NCCL communication libraries and the full software stack that has accumulated over a decade of AI development, represents a switching cost that no hardware spec sheet can fully account for. Startups in the AI chip space feel the pressure acutely — Rubin's 10x reduction in inference token costs makes it difficult for boutique hardware manufacturers to compete on the economics of scale.
The company also holds something its competitors lack entirely: years of production data from real AI factory deployments at the largest scale in the industry, which feeds directly back into chip design. When Nvidia says Rubin's architecture was informed by real-world Blackwell deployments, that feedback loop is genuine, and it is not something a competitor can replicate quickly.
What This Means for Businesses, Developers, and End Users
The Vera Rubin platform will not affect most people directly — the NVL72 rack sells to hyperscalers and enterprise cloud operators, not individuals. But the downstream effects of the infrastructure Rubin enables are worth thinking through.
For enterprise AI teams
The most immediate impact falls on organizations building AI-powered products and services on top of cloud infrastructure. When Rubin-equipped instances arrive on AWS, Azure, and Google Cloud in the second half of 2026, the economics of running large reasoning models in production will shift meaningfully. Long-context processing — currently expensive enough to push some use cases out of reach — becomes more viable. Agentic workflows that chain multiple AI steps together become cheaper to run at scale. The threshold for what is "too expensive to deploy" moves in the direction that expands the solution space.
For developers and startups
API pricing from the major AI labs reflects, with some delay, the cost of their underlying infrastructure. As Rubin-equipped data centers come online through 2026 and into 2027, there is reasonable expectation that inference costs for frontier models will continue the downward trajectory that has characterized the last three years. For developers building applications on top of those APIs, lower costs mean more experimentation, more generous usage tiers, and more use cases becoming commercially viable that were not before.
For end users of AI products
The everyday user of AI products — whether that is a writing assistant, a coding tool, a customer service chatbot, or a multimodal search interface — will experience the Rubin generation primarily through capability expansions and reduced limitations. The models running on Rubin infrastructure can handle longer documents, more complex reasoning chains, and more sophisticated multi-step tasks, while the economics of serving those capabilities improve. Rate limits loosen. Context windows expand. Responses get faster. The features that currently sit behind premium subscription tiers gradually become baseline.
The Broader Significance: AI Infrastructure as Industrial Capital
It is worth stepping back from the spec sheet to understand what the Vera Rubin announcement represents in a broader context.

Nvidia is no longer presenting itself as a chip company that sells components to system builders. The Rubin platform treats the data center as the unit of compute, designing GPUs, CPUs, networking, security, software, power delivery, and cooling as a single architecture — and selling the whole stack, from silicon to software frameworks to rack-scale deployment blueprints.
This is a fundamentally different business and a fundamentally different competitive position than where Nvidia was even five years ago. The company Jensen Huang described at CES — one that designs AI supercomputers rather than graphics chips, that ships complete software stacks alongside hardware, that prices its systems in terms of cost per intelligence token rather than teraflops — is operating at a layer of the technology stack that has historically been occupied by infrastructure companies like Cisco, Oracle, and IBM in earlier computing eras.
The difference is that those companies built infrastructure for storing and moving data. Nvidia is building infrastructure for generating intelligence, and the demand trajectory for that product does not resemble any previous technology cycle. Huang put it plainly at CES: "Some $10 trillion or so of the last decade of computing is now being modernized to this new way of doing computing."
Whether that framing is exactly right or somewhat inflated almost does not matter. The directional claim — that the entire computing industry is being retooled around AI inference as the primary workload — is broadly supported by the capital expenditure commitments of every major technology company. Microsoft, Google, Amazon, and Meta are collectively spending hundreds of billions of dollars on AI infrastructure, and Vera Rubin is the current-generation hardware they are spending it on.
The Risks Worth Acknowledging
Supply chain and production timelines
Vera Rubin is in full production in Q1 2026, with partner availability still described as the second half of 2026. Nvidia's Blackwell generation experienced supply and thermal design challenges that delayed volume shipments from late 2024 into early 2025. Rubin's all-liquid-cooled, modular tray design addresses some of those manufacturing and deployment challenges, but building the most complex server systems in the history of commercial computing at the scale hyperscalers are demanding is an engineering challenge where delays remain possible.
The power consumption question
More capable chips are, in the near term, also more power-hungry chips. The NVL72 rack is a dense, high-wattage system that requires purpose-built data center infrastructure to deploy. The energy consumption of large-scale AI infrastructure is a genuine externality that is increasingly drawing regulatory and public scrutiny, and that pressure will continue to intensify as AI workloads grow.
Performance claims vs. production reality
Nvidia's stated performance figures are measured under specific benchmark conditions, and real-world production workloads often achieve a fraction of theoretical peak performance. The 10x inference cost reduction relative to Blackwell is a meaningful benchmark — but it applies specifically to mixture-of-experts models under optimized conditions, and generalizing it to all AI workloads would be imprecise.
Wrap up
Vera Rubin will not make headlines in the way that a new iPhone or a viral AI chatbot does. It is data center hardware — invisible infrastructure that most people will never see or touch. But the AI products that define the next few years of computing will run on it, and its capabilities and economics will determine which applications are viable to build, at what cost, and for which users.
The move to trillion-parameter AI is not speculative. It is already underway. The question was never whether models of that scale would be built — it was whether the hardware infrastructure could keep pace with the ambition of the researchers building them, and whether the economics would ever make sense at scale. Vera Rubin is Nvidia's answer to both questions simultaneously, and given the company's track record of delivering on its hardware roadmap, the industry has every reason to take that answer seriously.
What happens when trillion-parameter models run at ten times lower cost on infrastructure that treats an entire rack as a single supercomputer is not a question Nvidia can answer on a CES stage. It is a question that every AI developer, enterprise architect, and product team will spend the next two years finding out in production.
Frequently Asked Questions
What is Nvidia's Vera Rubin chip?
Vera Rubin is Nvidia's next-generation AI computing platform, announced at CES 2026 as the successor to the Blackwell architecture. It combines six co-designed chips — including the Vera CPU and Rubin GPU — into a unified platform optimized for training and running large AI models, including trillion-parameter systems. The platform is in full production and expected to be available through major cloud providers in the second half of 2026.
How does Vera Rubin compare to Nvidia Blackwell?
Rubin delivers 5x greater inference performance and 3.5x greater training performance than Blackwell. Memory bandwidth increases from approximately 8 TB/s to 22 TB/s per GPU. Most significantly, Nvidia claims the platform reduces inference token costs by 10x and requires 4x fewer GPUs to train the same mixture-of-experts models — a substantial improvement in cost efficiency for AI infrastructure operators.
What is a trillion-parameter AI model?
Parameters are the numerical values inside an AI model that encode its knowledge and reasoning capabilities. More parameters generally enable more capable AI. Current frontier models like GPT-4 and Claude 3 are estimated to have hundreds of billions of parameters. Trillion-parameter models represent the next frontier of scale, requiring hardware platforms like Vera Rubin that can handle the memory bandwidth and inter-GPU communication these architectures demand.
When will Vera Rubin be available?
Nvidia confirmed that Vera Rubin is in full production as of early 2026, with partner system availability — through cloud providers including AWS, Google Cloud, Microsoft Azure, and Oracle Cloud — expected in the second half of 2026. Nvidia's Rubin Ultra, a more powerful follow-on, is expected in the second half of 2027.
How does Vera Rubin affect AI pricing for consumers?
Vera Rubin does not directly affect consumer pricing, as it is data center hardware sold to cloud providers and enterprises. However, lower infrastructure costs tend to flow through to cheaper API pricing and more capable AI products over time. The 10x reduction in inference token costs, if passed through to API consumers, would significantly expand the range of AI features and use cases that are economically viable to build and offer at scale.
How does Vera Rubin compare to AMD's competing chips?
AMD unveiled its Helios rack-scale platform at CES 2026 alongside Vera Rubin. AMD's MI455X GPU carries 432GB of memory per unit, exceeding Rubin's 288GB in raw capacity, but trails on memory bandwidth and lacks the integrated ecosystem support of Nvidia's platform. AMD's HIP and ROCm software stack has improved substantially but remains behind Nvidia's CUDA ecosystem in breadth of third-party framework support and developer adoption.
Who is Vera Rubin named after?
Vera Rubin was a pioneering American astronomer whose observations in the 1970s and 1980s provided the first strong evidence for the existence of dark matter. She documented that galaxies rotate in ways that could not be explained by visible mass alone, implying the existence of unseen mass throughout the universe. Nvidia named the platform after her as part of its pattern of naming GPU architectures after physicists and scientists.
What is the Nvidia Rubin NVL72?
The NVL72 is the flagship rack-scale system built around the Vera Rubin platform. It integrates 72 Rubin GPUs and 36 Vera CPUs into a single liquid-cooled system connected through NVLink 6 fabric, delivering 3.6 exaflops of FP4 inference performance and 260 TB/s of internal bandwidth. Nvidia describes it as operating as a single supercomputer rather than a collection of individual servers, and it is the primary system that hyperscalers like Microsoft, Google, and Amazon are procuring.
Related Articles












