On February 19, 2026, Demis Hassabis posted a brief announcement to X that set off the usual round of breathless coverage: Gemini 3.1 Pro had launched, and its headline claim was a 77.1% score on ARC-AGI-2, described as more than double the reasoning performance of its predecessor.
Tech Twitter lit up. Commentators reached for familiar language about AGI milestones. The word "breakthrough" appeared in more headlines than any single benchmark score has earned since GPT-4.
Most of that coverage missed the more interesting story, which is not whether the number is impressive — it is — but what it actually means, why the benchmark exists, how the scoring works in practice, and why the gap between 77% and genuine general intelligence is wider than a simple percentage comparison suggests.
To understand what Gemini 3.1 Pro actually accomplished, you first need to understand what ARC-AGI-2 is actually measuring. And that requires going back to a 2019 paper that most people covering AI have never read.
The Problem With Every Benchmark Before ARC
François Chollet, the creator of Keras and a researcher at Google, published a paper in 2019 titled "On the Measure of Intelligence." The central argument was that the AI field had developed a systematic blind spot: it was measuring the wrong thing.
Most AI benchmarks, Chollet argued, measure crystallized intelligence, the accumulation of learned knowledge and trained skills that a system has absorbed from its training data. MMLU, for instance, tests whether a model can answer questions about things it has presumably encountered before. Math Olympiad benchmarks test whether a model can apply techniques it has been trained on. Even many coding benchmarks, in practice, reward memorization of common patterns more than genuine problem-solving.
None of that is worthless, but none of it captures what Chollet was after. His paper defined intelligence not as accumulated knowledge but as the efficiency of skill acquisition on unknown tasks. The operative question is not "what do you know?" but "how quickly can you learn something new?"
That distinction led directly to the Abstraction and Reasoning Corpus, later formalized as ARC-AGI. The benchmark presents visual grid puzzles that require understanding a novel transformation rule from just a few examples, then applying that rule to a new case. The puzzles use only the most primitive cognitive building blocks — object persistence, basic counting, simple geometric concepts like symmetry and connectivity — to ensure that performance cannot be explained by domain-specific knowledge or training data overlap.
ARC-AGI focuses on fluid intelligence, the ability to reason, solve novel problems, and adapt to new situations, rather than crystallized intelligence, which relies on accumulated knowledge and skills. That distinction is critical because crystallized intelligence includes cultural knowledge and learned information, which would provide an unfair advantage.
The original benchmark held for years. Early LLMs scored near zero, because the puzzle format ruthlessly exposed the difference between pattern-matching at scale and genuine abstract reasoning. The benchmark was, by design, "easy for humans, hard for AI."
Why ARC-AGI-2 Exists
The original ARC-AGI was eventually compromised by the very thing it was built to resist.
As AI systems became more powerful and the benchmark gained prominence, the gap between human and AI performance began to close — but not always for the right reasons. Brute-force program search could solve many puzzles through exhaustive enumeration rather than genuine understanding. The dataset became widely used in pretraining, introducing contamination risk. High compute budgets allowed systems to effectively guess their way to high scores by generating thousands of candidate solutions and selecting the one that matched the expected output.
When OpenAI's o3 cleared 85% on ARC-AGI-1 in late 2024 under high-compute conditions, it was a genuine milestone. But it also signaled that the benchmark needed to evolve.
ARC-AGI-2 aims to resist overfitting and memorization, focusing instead purely on general fluid intelligence. It should not be possible to prepare for any of the tasks in advance. Every task in the dataset is unique.
Specifically, ARC-AGI-2 introduced several structural improvements over its predecessor. Puzzles are selected adversarially to defeat large-scale sampling or search, meaning that throwing compute at the problem is less effective. The benchmark includes semi-private and private test sets held out from all public training data and procedurally generated to reduce contamination risk. Tasks are calibrated against human performance data gathered in a controlled, first-party study rather than inferred from historical records.
ARC-AGI-2 is an AI benchmark designed to measure general fluid intelligence, not memorized skills — a set of never-seen-before tasks that humans find easy, but current AI struggles with. There's a lot more focus on probing abilities that are still missing from frontier reasoning systems, like on-the-fly symbol interpretation, multi-step compositional reasoning, and context-dependent rules.
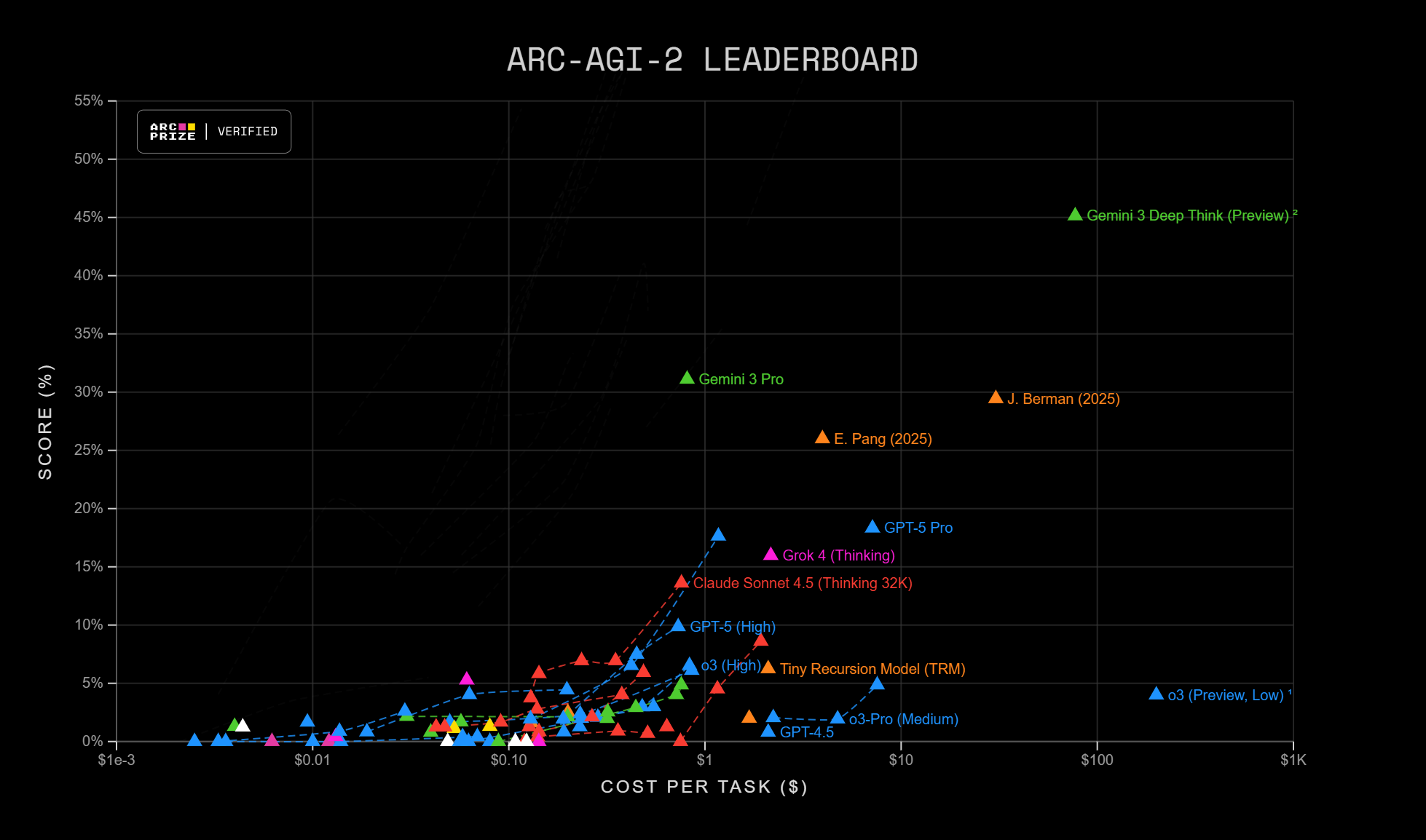
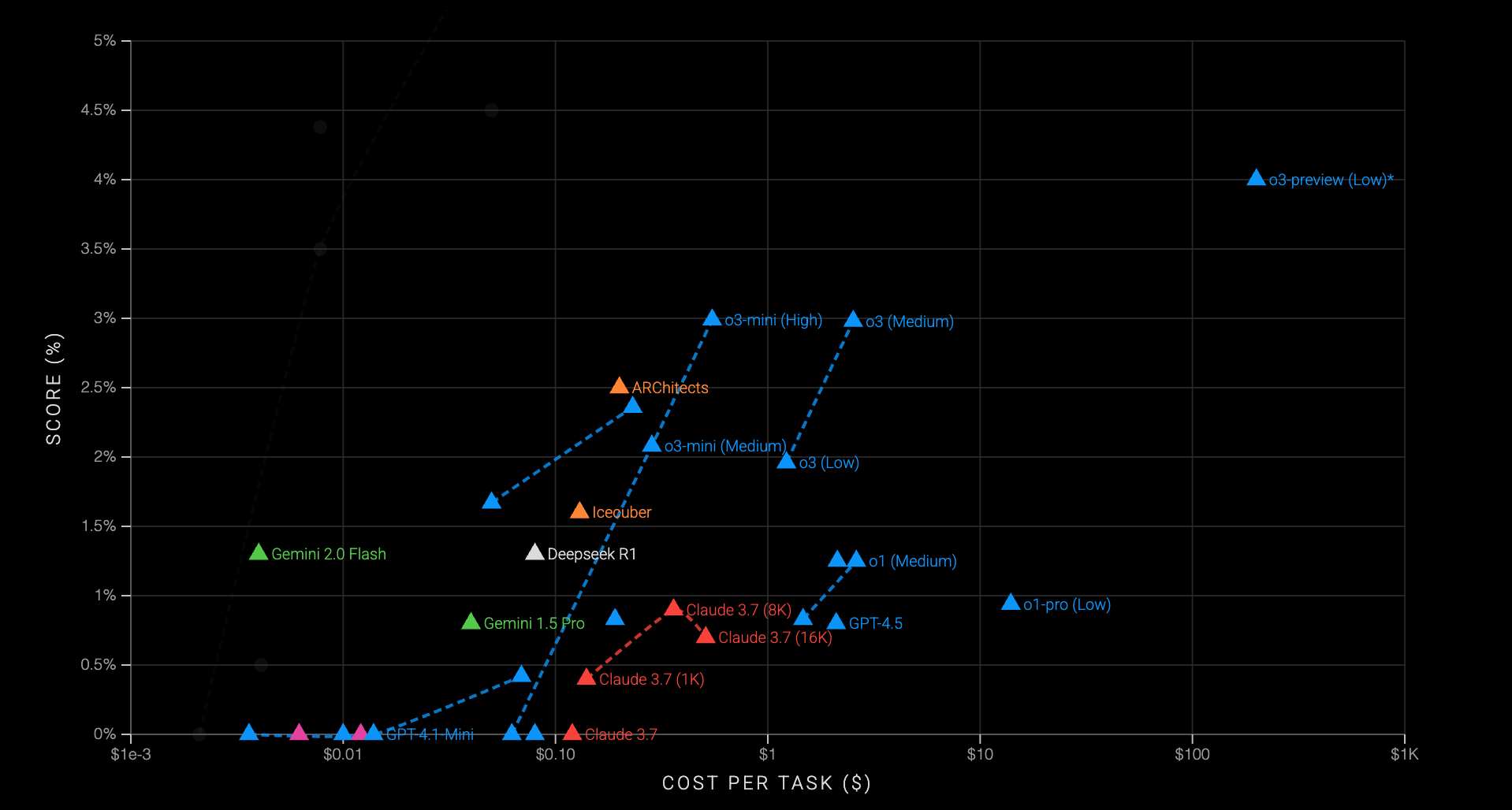
When ARC-AGI-2 launched in March 2025, frontier models crashed. Hard.
OpenAI o1-pro scored 1% with a cost per task of $200. OpenAI o3-mini-high scored 0.0%. DeepSeek-R1 scored 0.3%. Anthropic Claude 3.7 scored 0.0%. Google Gemini 2.0 Flash scored 1.3%. The average score for a panel of humans off the street was 60%.
The benchmark had done exactly what it was designed to do: expose a gap that had been partially papered over by compute and memorization.
The Leaderboard Progression That Puts 77% in Context
What happened between March 2025 and February 2026 is, in some ways, more interesting than Gemini 3.1 Pro's headline number.
The early months of ARC-AGI-2 produced a period that the ARC Prize Foundation described as idea-constrained. Throwing more compute at the problem helped modestly but hit diminishing returns quickly. The models that started to break through were not simply larger or given more inference budget; they used structured refinement loops, iterative verification, and application-layer engineering to push past raw model limitations.
Poetiq, an AI lab operating without its own frontier model, built a meta-system that wraps existing models in learned test-time reasoning. In November 2025, their system became the first to break the 50% barrier on the semi-private test set, reaching 54% at $30.57 per problem using Gemini 3 Pro, compared to Gemini 3 Deep Think's previous 45% at $77.16 per problem.
The ARC Prize Foundation added a new category to the leaderboard called Model Refinements and verified a new Gemini 3 Pro refinement, open-sourced by Poetiq, which improves performance on ARC-AGI-2 from baseline 31%, $0.81 per task up to 54%, $31 per task.
Then, in mid-to-late 2025, model improvements from the frontier labs began arriving on top of the application-layer progress. Gemini 3 Deep Think hit 45% as a base model, then 84.6% in the final weeks of 2025, validated by the ARC Prize Foundation. By early 2026, the leaderboard had advanced dramatically from where it stood when the benchmark launched.
At the beginning of 2026, the highest-scoring model was GPT 5.2 Pro with a success rate of 54.2%. At the time of writing, merely two and a half months later, the best-performing model is Gemini 3 Deep Think, with a success rate of 84.6%.
Against that backdrop, Gemini 3.1 Pro's 77.1% score lands with more context. It is a strong result for a model without extended deep thinking mode. It is not the highest score on the board. And the Imbue research team using a code evolution approach was able to push Gemini 3.1 Pro further, from 88.1% with the base API to 95.1% using their evolutionary harness, at an average cost of $8.71 per task.
What the Number Actually Measures — And What It Doesn't
The honest analysis of Gemini 3.1 Pro's ARC-AGI-2 score requires separating several distinct claims that tend to get conflated in coverage.
What a high ARC-AGI-2 score does tell you
ARC-AGI-2 is a meaningful and genuinely hard test of a specific class of reasoning ability. Scoring 77% on tasks that were designed to defeat memorization and brute-force search, calibrated against human baseline performance, is a substantive result. It reflects genuine improvement in abstract pattern recognition, multi-step compositional reasoning, and the ability to infer novel rules from minimal examples. The jump from Gemini 3 Pro's 31.1% to 77.1% on Gemini 3.1 Pro, achieved without the extended compute budget of Deep Think mode, is a meaningful capability advancement.
For developers building systems that need strong abstract reasoning, the score is practically relevant. Tasks that require inferring novel transformation rules from few examples, solving puzzles with context-dependent logic, or applying compositional reasoning across modalities should benefit from these improvements.
What a high ARC-AGI-2 score doesn't tell you
The benchmark measures one specific dimension of intelligence, and a particularly abstract one at that. High ARC-AGI-2 performance does not predict performance on tasks requiring deep domain knowledge, sustained long-context reasoning, nuanced judgment, or the kind of open-ended problem-solving that characterizes most professional work.
The benchmark's own technical report is explicit on this point. Current frontier AI reasoning performance remains fundamentally constrained to knowledge coverage, giving rise to new forms of benchmark contamination. AI reasoning systems still exhibit numerous flaws and inefficiencies necessary to overcome in order to reach AGI. We still need new ideas, such as methods to separate knowledge and reasoning, among other challenges.
The score also does not directly map to the AGI question that headlines tend to imply. Gemini 3.1 Pro is a remarkable model. It is not artificial general intelligence, and its 77.1% ARC-AGI-2 score does not claim to be evidence that it is.
The human baseline deserves scrutiny
A critical detail that most coverage elides: the human baseline on ARC-AGI-2 is 60%, not 100%. That means Gemini 3.1 Pro at 77.1% is technically performing above the average human baseline on this specific set of tasks.
That sounds more dramatic than it is, for a few reasons.
The 60% figure represents average general-public participants tested in a 90-minute session, compensated $5 per correct task plus a base show-up fee, working without prior familiarity with the task format. The human baseline is so low primarily due to tricky tasks that a competent human doesn't automatically solve with enough thought — where a sort of luck in terms of idiosyncratic experience or idea is needed to reach the solution. A panel of ten humans tested together achieves close to 100% because different people happen to have the intuitions needed for different puzzles. And humans at the higher end of the distribution, those who spend more time with the puzzles and approach them systematically, score substantially higher.
The comparison between model performance and human performance is also complicated by the efficiency dimension. Starting with ARC-AGI-2, all ARC-AGI reporting comes with an efficiency metric. Intelligence is not solely defined by the ability to solve problems or achieve high scores. The efficiency with which those capabilities are acquired and deployed is a crucial, defining component. Models spending hundreds of dollars per task to achieve high scores are not demonstrating the same kind of intelligence efficiency as a human who solves tasks in under three minutes at human labor costs.
The Competitive Landscape Right Now
Gemini 3.1 Pro's 77.1% positions it clearly in the top tier of frontier models on ARC-AGI-2, but the leaderboard is moving fast enough that any specific ranking has a short shelf life.
| Model | ARC-AGI-2 Score | Notes |
|---|---|---|
| Gemini 3 Deep Think | 84.6% | With extended reasoning |
| Gemini 3.1 Pro | 77.1% | Standard mode |
| Claude Opus 4.6 | 68.8% | Anthropic flagship |
| GPT-5.2 Pro | 54.2% | As of early 2026 |
| Gemini 3 Pro (Poetiq harness) | 54% | Application-layer refinement |
| Gemini 3 Pro (baseline) | 31.1% | Gemini 3.1 Pro predecessor |
The table makes the pace of progress visible. From sub-5% for all frontier models in March 2025 to scores approaching 90% within a year is not a routine benchmark cycle. Something has genuinely changed in how these systems handle novel pattern inference.
Notably, the best results are coming from a combination of improved base models and application-layer engineering rather than either alone. The ARC Prize Foundation's conclusion from the 2025 competition was pointed: For the ARC-AGI-1 and ARC-AGI-2 format, the Grand Prize accuracy gap is now primarily bottlenecked by engineering, while the efficiency gap remains bottlenecked by fundamental science and new ideas.
That distinction matters. The "can you solve it" question is increasingly being answered by engineering effort. The "can you solve it efficiently and cheaply" question, which is what the efficiency column on the leaderboard actually measures, remains a genuine research problem.
What ARC-AGI-3 Signals About Where the Field Is Going
The ARC Prize Foundation is not treating 77% or even 84.6% as a solved problem. They have already announced ARC-AGI-3 for early 2026, and its design represents a more fundamental shift than the previous iteration.
While the first 2 versions challenged static reasoning, version 3 is designed to challenge interactive reasoning and requires new AI capabilities to succeed. The ARC-AGI-3 scoring metric will give us a formal comparison of human versus AI action efficiency for the first time.
Interactive reasoning is a harder problem than static reasoning in a specific and important way. ARC-AGI-2 presents a complete puzzle and asks for a solution. ARC-AGI-3 will involve exploring an environment, forming a hypothesis, testing it, revising it, and reaching a solution through a sequence of actions. That is closer to how humans actually solve novel problems, and it is a dimension where current AI systems are considerably less capable than their static benchmark scores suggest.
The capabilities ARC-AGI-3 targets, including exploration, planning, memory, goal acquisition, and alignment, map closely to what would be required for truly autonomous agentic systems. The ARC Prize Foundation is, in effect, building the measurement infrastructure for the next meaningful capability threshold before it becomes commercially relevant.
The Signal Worth Taking From This
For developers and technical leaders evaluating frontier models, the practical takeaway from Gemini 3.1 Pro's ARC-AGI-2 performance is straightforward: abstract reasoning capabilities have advanced materially in the past twelve months, and Gemini 3.1 Pro is currently the strongest model without extended thinking mode for tasks that require inferring novel transformation rules, compositional logic, and generalization from sparse examples.
For anyone trying to track AI progress more broadly, the ARC-AGI-2 trajectory tells a story worth understanding. A benchmark designed to be immune to brute force and memorization went from sub-5% frontier performance in early 2025 to scores approaching 90% within a year, driven by a combination of model improvements and application-layer engineering. That pace of progress is unusual by historical standards, and it is happening on a benchmark specifically designed to resist the tricks that usually inflate scores.
That progress does not translate directly into general intelligence. The benchmark's own creators are clear on that. The efficiency gap, between what models can do given unlimited compute and what they can do efficiently under realistic constraints, remains a fundamental research problem. And ARC-AGI-3's shift toward interactive reasoning will almost certainly expose limitations that the current numbers do not reveal.
What it does demonstrate is that the gap between human-level performance on novel abstract reasoning tasks and frontier AI performance is closing faster than most observers expected when this benchmark was introduced. Whether that pace is a reason for optimism or caution depends considerably on what you think comes next.
Frequently Asked Questions
Q: What is ARC-AGI-2 and why does it matter?
ARC-AGI-2 is an AI benchmark designed to measure fluid intelligence, specifically the ability to infer novel abstract rules from a few examples and apply them to new cases. Unlike benchmarks that test domain knowledge or trained skills, it is designed to resist memorization and brute-force pattern matching. It matters because it attempts to measure something closer to genuine reasoning ability rather than accumulated knowledge, making it one of the few benchmarks that cannot easily be gamed by training on more data.
Q: What did Gemini 3.1 Pro actually score on ARC-AGI-2?
Gemini 3.1 Pro scored 77.1% on ARC-AGI-2, verified by Google DeepMind and released on February 19, 2026. This is more than double the 31.1% score of its predecessor, Gemini 3 Pro, and the highest score among frontier models operating without extended deep thinking mode. Gemini 3 Deep Think holds a higher score of 84.6% using extended reasoning compute.
Q: What is the human baseline on ARC-AGI-2?
The average score for general-public participants tested in a controlled first-party study was 60%, with a cost equivalent of $17 per task based on human labor costs. A panel of ten humans working together approaches 100%, because different people bring different intuitions to different puzzles. Gemini 3.1 Pro at 77.1% technically exceeds the average human baseline, but the comparison is complicated by efficiency differences and the conditions under which the human baseline was measured.
Q: Does Gemini 3.1 Pro's score mean we are close to AGI?
No. The ARC Prize Foundation's own technical report states clearly that current frontier AI reasoning systems still exhibit numerous flaws and inefficiencies necessary to overcome to reach AGI. ARC-AGI-2 measures one specific dimension of reasoning ability in a controlled setting. High performance on abstract grid puzzles does not directly predict performance on the full breadth of tasks that would define AGI: sustained reasoning across domains, autonomous planning and exploration, and efficient generalization in open-ended environments.
Q: How has ARC-AGI-2 performance changed since the benchmark launched?
When ARC-AGI-2 launched in March 2025, all frontier models scored below 5%, while the average human baseline was 60%. By late 2025, Poetiq's refinement harness had broken the 50% barrier. By early 2026, scores ranging from 54% to 84.6% were being achieved by top frontier models. The pace of progress over a single year was faster than most observers anticipated and reflects a combination of genuine model improvement and application-layer engineering advances.
Q: What is ARC-AGI-3 and how is it different?
ARC-AGI-3 is the next iteration of the benchmark, planned for release in early 2026. It represents the first major format change since ARC was introduced in 2019. While ARC-AGI-1 and ARC-AGI-2 test static reasoning, ARC-AGI-3 will test interactive reasoning: exploration, planning, memory, goal acquisition, and the ability to learn through sequential actions in an environment rather than from a presented puzzle. For the first time, it will also provide a formal comparison of human versus AI action efficiency.
Q: What does Gemini 3.1 Pro's ARC-AGI-2 score mean for developers building AI applications?
For applications requiring abstract reasoning, novel pattern inference, compositional logic, or few-shot generalization to new task structures, Gemini 3.1 Pro represents a meaningful improvement over previous generations. The score is a reliable signal of capability in those specific areas. It does not directly predict performance on agentic workflows, sustained multi-step reasoning in real environments, or tasks requiring deep domain knowledge — all areas where ARC-AGI-2 performance does not generalize straightforwardly.
Related Articles