

The AI industry is holding its breath. After sending shockwaves through global markets in January 2025 with DeepSeek-R1, the Chinese AI startup is preparing what could be its most ambitious release yet. DeepSeek V4, rumored to launch around mid-February 2026, isn't just another incremental update—according to insiders, it represents a fundamental reimagining of how large language models handle code.
If the claims hold up, V4 could do to coding what R1 did to the broader AI landscape: prove that you don't need billions of dollars and the most advanced chips to build world-class artificial intelligence.
But here's what makes this release particularly interesting for American developers and businesses: despite mounting government restrictions on DeepSeek's consumer app, the open-source nature of their models means V4's underlying technology will be accessible to anyone willing to run it locally. That's a proposition that has significant implications for enterprise development, data sovereignty, and the future direction of AI competition.
Let's break down everything we know about DeepSeek V4, what the technical papers suggest about its capabilities, and what it means for developers who've been watching this space closely.
When Is DeepSeek V4 Coming Out?
According to a report from The Information published in January 2026, citing people with direct knowledge of the project, DeepSeek is targeting a mid-February 2026 release for V4. The specific date being discussed internally is around February 17, which coincides with the Lunar New Year celebrations.

This timing isn't accidental. DeepSeek has a pattern of leveraging major holidays for maximum visibility. Their R1 launch in late January 2025 came just before the Lunar New Year period and proceeded to dominate headlines, briefly becoming the most downloaded app on the iOS App Store in the United States and triggering an $600 billion single-day drop in Nvidia's stock price – the largest single-company decline in U.S. stock market history.
Looking at DeepSeek's release history reveals a roughly seven-month cycle for flagship models. V1 arrived in October 2023, V2 followed in May 2024, and V3 launched in December 2024. V4 in February 2026 fits this established rhythm, though it represents a slightly longer gap—likely reflecting the more ambitious architectural changes involved.
DeepSeek hasn't officially confirmed any of this. The company maintains its characteristic operational silence, letting technical papers and eventual releases speak for themselves. Founder Liang Wenfeng has declined to comment on specific timing, and the company's only public-facing work in recent months has been a series of research papers that industry observers have immediately connected to V4's architecture.
The bottom line: if past patterns hold and the reporting is accurate, expect DeepSeek V4 to appear sometime in the second half of February 2026. Whether it's February 17 or a few days on either side, the window is narrow enough that anyone interested should be preparing now.
What Makes DeepSeek V4 Different?
This isn't a minor version bump. Based on recently published research papers and insider information, V4 represents a significant architectural departure from previous models. Three technical innovations appear to form its foundation.
Engram: The Conditional Memory Revolution
On January 12, 2026, DeepSeek published a research paper that immediately caught the attention of the AI research community. Titled "Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models," it introduced Engram – a module that fundamentally rethinks how language models handle knowledge retrieval.
Here's the problem Engram solves. When current language models need to recall a static fact – say, "the capital of France is Paris" — they can't simply look it up. Instead, they simulate retrieval through expensive computation, using multiple layers of attention and feed-forward networks to reconstruct patterns that could be handled by simple lookup. This wastes valuable computational depth on trivial operations that could otherwise be allocated to complex reasoning.
Engram separates static memory retrieval from dynamic reasoning. It uses deterministic hash-based lookups for static patterns with O(1) complexity—meaning constant time regardless of how much knowledge is stored—while reserving computational resources for genuine reasoning tasks. The paper describes it as "conditional memory," complementing the "conditional computation" already provided by Mixture-of-Experts architectures.
For coding applications, this translates to better understanding of project structure, naming conventions, and patterns across entire repositories. Instead of recalculating attention for every token in a 100,000-line codebase, Engram uses a lookup table to instantly find relevant code snippets.
mHC: Stable Training at Massive Scale
Published on December 31, 2025, DeepSeek's paper on "Manifold-Constrained Hyper-Connections" addresses a different but equally important problem: training stability at massive scale.
Traditional deep neural networks suffer from degradation as they get deeper. Information tends to get lost or distorted as it passes through many layers. Residual connections – the standard solution for the past decade—help, but they have their own limitations at extreme scales.
mHC creates new pathways for information to flow across layers more effectively. The paper describes how standard hyperconnections suffer from broken identity mapping, catastrophic signal amplification, and training instability beyond 60 layers. mHC constrains these connections mathematically to maintain desired properties while still allowing the flexibility that makes hyperconnections useful.
The result is a model that can be trained with "aggressive parameter expansion" by bypassing GPU memory constraints. Co-authored by founder Liang Wenfeng himself, the paper enables training larger models on the same hardware that would otherwise limit capacity.
DeepSeek Sparse Attention
Building on work from earlier in 2025, DeepSeek Sparse Attention (DSA) enables context windows exceeding 1 million tokens while reducing computational costs by approximately 50% compared to standard attention mechanisms.
For developers, this means V4 can theoretically process entire large codebases in a single pass. Multi-file reasoning becomes possible in ways that current models struggle with understanding how a change in one file affects dependencies in another, tracing execution paths across modules, maintaining consistency during large-scale refactoring.
The combination of these three innovations suggests V4 isn't trying to compete by simply being bigger. It's trying to be architecturally smarter—a philosophy that has defined DeepSeek's approach since its founding.
The Coding Focus: Why V4 Is Targeting Developers
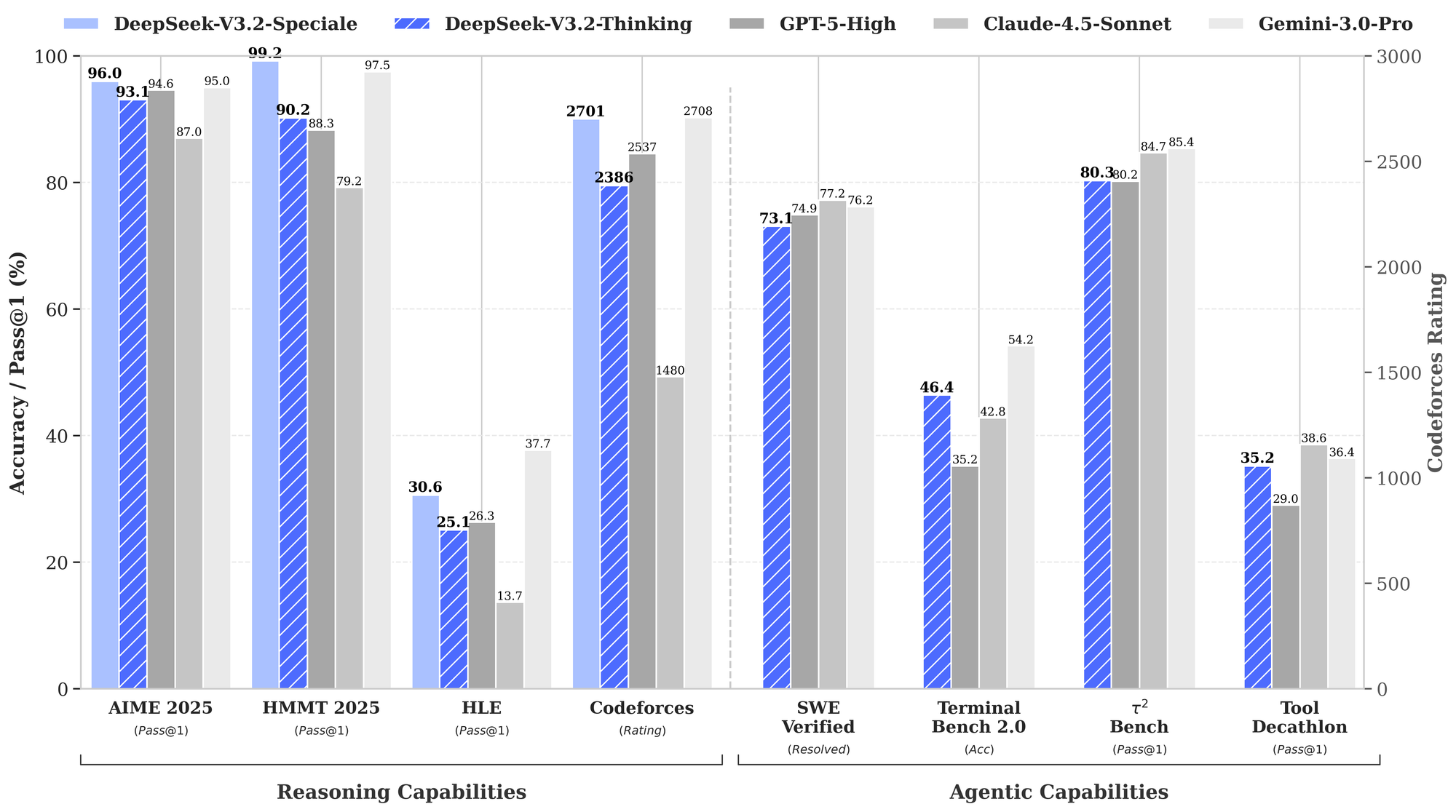
Internal testing reportedly shows V4 outperforming Anthropic's Claude 3.5 Sonnet and OpenAI's GPT-4o on coding benchmarks. While these claims remain unverified by independent testing, they align with DeepSeek's strategic focus.
The company isn't trying to build the best general-purpose chatbot. It's targeting the most commercially valuable segment of the AI market: enterprise developers. High-precision code generation capabilities translate directly into revenue, and organizations are willing to pay premium prices for tools that genuinely accelerate software development.
The benchmark everyone will be watching is SWE-bench Verified, where Claude Opus 4.5 currently leads with an 80.9% solve rate. For context, DeepSeek's V3.1 achieved 66% on this benchmark – impressive, but clearly behind the frontier. For V4 to claim the "coding crown," it needs to exceed 80.9%, which represents a significant jump.
What makes the claims more plausible is the specific capability being emphasized: repository-level reasoning. Current AI coding assistants excel at writing individual functions or explaining small code snippets. They struggle when problems span multiple files, when a bug in one module cascades through dependencies, or when a refactoring task requires understanding how dozens of files interact.
Internal reports describe V4 solving complex repository-level bugs that cause other models to "hallucinate or get stuck in loops." This would represent a genuine capability advancement rather than just incremental benchmark improvement.
Hardware Requirements: Can You Actually Run It?
One of the most anticipated aspects of V4 is its accessibility. DeepSeek has consistently released open-weight models that can run on consumer hardware—a stark contrast to the proprietary, API-only approach of OpenAI and Anthropic.
Early reports suggest V4 will continue this tradition with two deployment tiers. For consumer-grade hardware, dual NVIDIA RTX 4090s or a single RTX 5090 should be sufficient. Enterprise deployments can use standard data center GPU configurations.
If DeepSeek follows the V3 architecture pattern – 671 billion total parameters with approximately 37 billion activated at any given time – V4 will require significant VRAM, but quantization techniques (FP8 or INT4) should keep it accessible to serious hobbyists and small teams.
This matters because running models locally solves problems that cloud APIs can't. Organizations with strict data governance requirements can keep sensitive code entirely within their own infrastructure. Development teams in secure facilities can leverage AI capabilities without network connectivity. Self-hosting at scale can be significantly more economical than per-token API pricing.
The open-weight release will also enable fine-tuning for specific programming languages, frameworks, or organizational coding conventions. A V4 model tuned specifically for your company's tech stack could outperform generic alternatives by a substantial margin.
What We Know About Pricing
DeepSeek has earned a reputation for aggressive pricing that significantly undercuts American competitors. Their current API pricing—approximately $0.55 per million input tokens and $2.19 per million output tokens—is dramatically cheaper than alternatives. For comparison, Claude 3.5 Sonnet costs $3.00 per million input tokens and $15.00 per million output tokens.
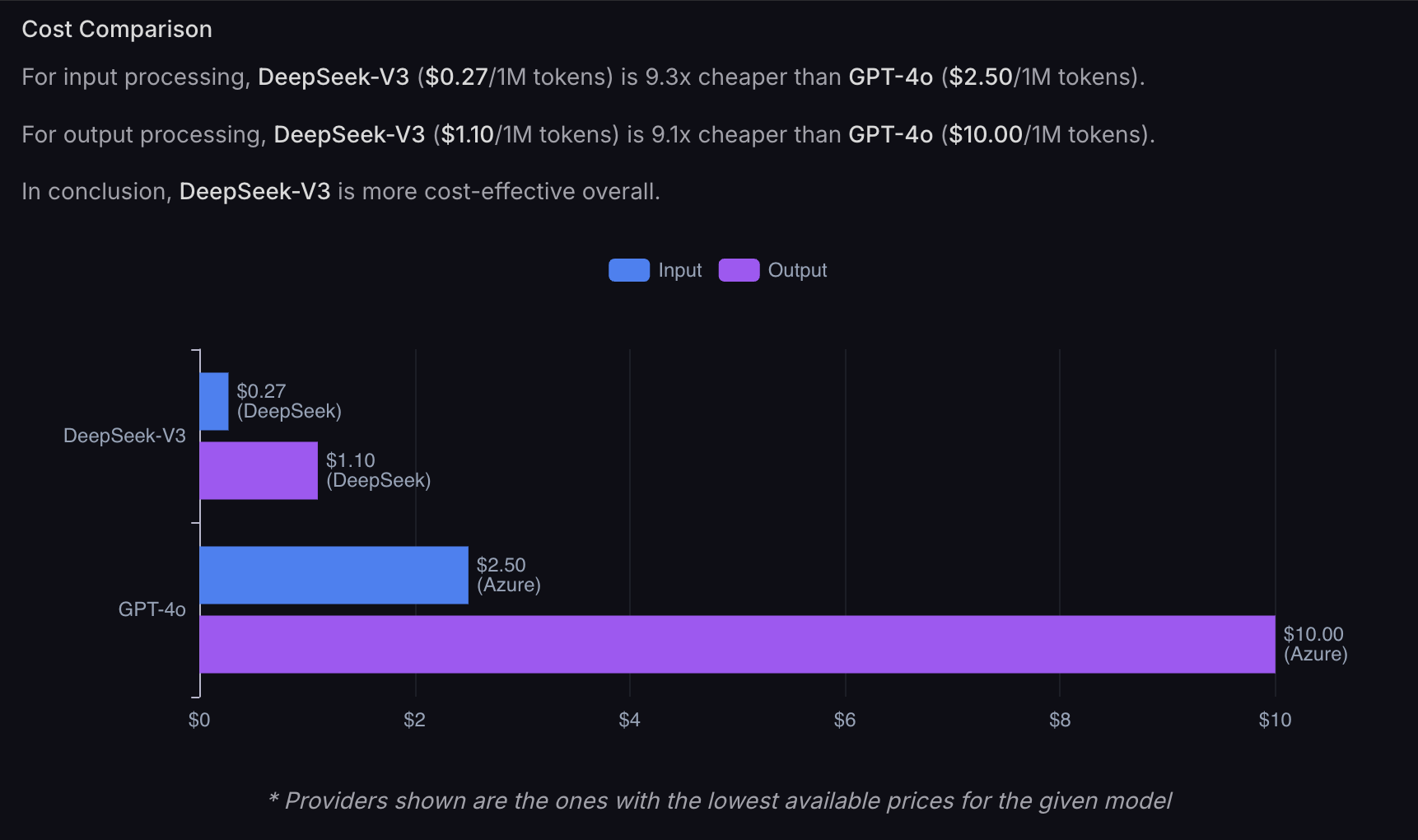
While V4's official pricing hasn't been announced, the expectation based on DeepSeek's history is that API costs will remain significantly lower than U.S.-based competitors. The company's hardware optimizations and efficiency focus make this economically sustainable rather than a loss-leader strategy.
For organizations currently paying substantial sums for AI API access, V4 represents a potential opportunity to dramatically reduce costs—assuming the performance claims hold up and the regulatory environment permits usage.
Security and Regulatory Concerns
No discussion of DeepSeek is complete without addressing the significant concerns raised by U.S. federal and state governments.
Since DeepSeek's R1 launch captured mainstream attention, the regulatory response has been swift and bipartisan. The U.S. House of Representatives banned DeepSeek from official devices in late January 2025. Representatives Josh Gottheimer (D-NJ) and Darin LaHood (R-IL) introduced the "No DeepSeek on Government Devices Act" in early February 2025.

More than a dozen states have now banned DeepSeek from government devices, including Texas, New York, Virginia, Iowa, Florida, and others. The concerns center on data privacy, the potential for user data to be shared with Chinese government entities under China's National Intelligence Law, and code reportedly linked to China Mobile — a state-owned telecommunications company already banned by the FCC.
For individual developers and private companies, the situation is more nuanced. The consumer app and cloud API raise legitimate data sovereignty questions. However, running open-weight models locally eliminates data transmission concerns entirely. Your prompts never leave your hardware.
This distinction matters for V4's potential adoption. Organizations prohibited from using DeepSeek's cloud services might still deploy V4 locally, subject to their own IT security reviews. The open-source community is already actively running DeepSeek models through platforms like Ollama and vLLM without relying on DeepSeek's infrastructure.
The bottom line for American users: understand your organization's policies, consider the difference between cloud APIs and local deployment, and make informed decisions based on your specific use case and risk tolerance.
What to Expect After Launch
If DeepSeek follows its established pattern, V4's release will include several components. Open weights released under a permissive license—likely MIT, as with previous models will allow anyone to download and run the model. A technical paper will detail the architecture, training methodology, and benchmark results. API access through DeepSeek's platform will offer a cloud-based option for those who don't want to manage infrastructure.
The open-source community will rapidly create quantized versions for various hardware configurations. Expect Hugging Face uploads within hours of release, followed by optimized versions for platforms like Ollama, vLLM, and others.
Benchmark comparisons will flood social media and AI forums. The key tests to watch include SWE-bench Verified for software engineering tasks, HumanEval for code generation, MATH-500 for mathematical reasoning, and LiveCodeBench for competitive programming.
Independent researchers will stress-test the claims about repository-level reasoning, long-context stability, and edge cases. The gap between marketing and reality typically becomes clear within the first week or two of community experimentation.
For developers planning to evaluate V4 for production use, the recommendation is straightforward: wait for independent benchmarks, test on your specific use cases, and don't commit to infrastructure changes until you've validated performance on problems that matter to you.
How V4 Fits Into the Broader AI Landscape
DeepSeek V4 arrives at an inflection point in the AI industry. The assumption that frontier capabilities require frontier budgets is being challenged not just by DeepSeek, but by a broader trend toward efficiency-focused research.
OpenAI's o3-mini, released in early 2026, reflects this shift—a smaller, cheaper model aimed at competing on efficiency rather than just capability. Google has repeatedly reduced Gemini API costs throughout 2024 and 2025 in response to competitive pressure. The era of unlimited AI infrastructure spending may be giving way to more disciplined economics.
V4's success or failure will influence this trajectory. If the model delivers on its claims, it validates the thesis that architectural innovation can outperform resource accumulation. If it falls short, it suggests that DeepSeek's advantages have limits that scale can eventually overcome.
Either outcome matters for American developers. A successful V4 means more competition, lower prices, and potentially new approaches to problems that current models can't solve. An unsuccessful V4 suggests that the existing leaders have more breathing room than the hype implies.
The most likely outcome is somewhere in between: V4 will excel in specific areas, particularly coding, while falling short in others. Like every AI model, it will have strengths and weaknesses that emerge through real-world use.
Preparing for V4: Practical Steps
For developers and organizations interested in evaluating V4, several practical steps make sense before the release.
- Ensure your hardware is ready if you plan to run locally. Dual RTX 4090s or equivalent VRAM capacity should suffice for consumer-tier deployment. Verify that your Ollama, vLLM, or preferred inference platform is updated to versions that can handle new model architectures.
- Prepare evaluation criteria specific to your use cases. Generic benchmarks matter less than performance on your actual problems. Document the coding tasks where your current AI tools struggle, and plan to test V4 against those specific challenges.
- Understand your organization's policies regarding Chinese AI software. If you're in government, defense, or regulated industries, consult with your compliance team about local deployment versus cloud API distinctions.
- Follow the technical papers. DeepSeek's Engram and mHC research is publicly available on arXiv. Understanding the underlying architecture will help you predict where V4 will excel and where it might struggle.
- Maintain realistic expectations. No model is perfect, and first-release versions often have rough edges that improve over subsequent updates. V4 will likely be impressive in some areas and disappointing in others.
The Bottom Line
DeepSeek V4 represents the most anticipated AI model release since... well, since DeepSeek R1 a year ago. The company has established a pattern of exceeding expectations while challenging assumptions about what's possible with limited resources.
If the mid-February 2026 timing holds and the reported capabilities prove accurate, V4 will force every organization using AI for software development to reconsider their options. The combination of strong coding performance, open weights, and dramatically lower costs is difficult to ignore—regardless of one's views on the geopolitical complications.
For American developers watching this space, the recommendation is simple: pay attention, prepare to evaluate, and let the benchmarks speak for themselves. The AI landscape is shifting, and V4 may be another significant step in that ongoing transformation.
Frequently Asked Questions
When is the DeepSeek V4 release date?
Based on reports from The Information citing sources with direct knowledge of the project, DeepSeek V4 is expected to launch in mid-February 2026, potentially around February 17 to coincide with the Lunar New Year. DeepSeek has not officially confirmed this timeline, and the company maintains operational silence about specific release dates.
How much will DeepSeek V4 cost?
Official pricing hasn't been announced. However, DeepSeek has consistently offered significantly lower API pricing than American competitors. Current DeepSeek models cost approximately $0.55 per million input tokens compared to $3.00 for Claude 3.5 Sonnet. Expect V4 pricing to remain competitive with this pattern. Additionally, V4 will likely be released as an open-weight model, allowing free local deployment.
What hardware do I need to run DeepSeek V4 locally?
Early reports suggest V4 can run on consumer-tier hardware including dual NVIDIA RTX 4090s or a single RTX 5090. The model will likely follow the Mixture-of-Experts architecture of previous versions, with approximately 37 billion parameters activated at any time despite a much larger total parameter count. Quantized versions will reduce requirements further.
Is DeepSeek V4 better than ChatGPT and Claude for coding?
Internal testing reportedly shows V4 outperforming Claude 3.5 Sonnet and GPT-4o on coding benchmarks, with particular strength in repository-level reasoning and long-context code handling. However, these claims haven't been independently verified. The key benchmark to watch is SWE-bench Verified, where Claude Opus 4.5 currently leads with 80.9% accuracy.
Is DeepSeek V4 safe to use in the United States?
DeepSeek's consumer app and cloud API have been banned from U.S. government devices due to data privacy concerns. For private use, the situation is more nuanced. Running open-weight models locally eliminates data transmission to DeepSeek's servers entirely. Organizations should evaluate their specific risk tolerance and compliance requirements before adopting any deployment approach.
What is Engram in DeepSeek V4?
Engram is a conditional memory module that DeepSeek introduced in a January 2026 research paper. It separates static knowledge retrieval from dynamic reasoning, using O(1) hash-based lookups for factual recall while preserving computational resources for complex reasoning. This approach improves benchmark performance by 3-5 points across knowledge, reasoning, and coding tasks.
Will DeepSeek V4 be open source?
Based on DeepSeek's consistent pattern with previous models, V4 is expected to be released with open weights under a permissive license. Both V3 and R1 were released under the MIT License, allowing commercial use, modification, and redistribution. The company has stated that open-sourcing is core to their strategy rather than a charitable decision.
How does DeepSeek V4 compare to DeepSeek V3?
V4 represents a significant architectural upgrade rather than an incremental improvement. Key differences include Engram conditional memory for efficient knowledge retrieval, mHC (manifold-constrained Hyperconnections) for stable training at massive scale, and DeepSeek Sparse Attention for handling contexts exceeding 1 million tokens. V4 also focuses specifically on coding capabilities that V3's architecture couldn't fully address.
What is the context window for DeepSeek V4?
V4 is reportedly optimized for extremely long contexts, likely exceeding 1 million tokens through DeepSeek Sparse Attention technology. This would enable processing entire large codebases in a single pass. For comparison, V3 had a 128K token context window, though effective handling of long contexts varied by task.
Will DeepSeek V4 work with existing tools like Ollama and vLLM?
Previous DeepSeek models have been quickly adapted for popular inference platforms, and V4 should follow the same pattern. Expect the open-source community to release compatible versions within hours or days of the official launch. Quantized versions for various hardware configurations typically appear on Hugging Face shortly after release.
Related Articles












