

One year after DeepSeek R1 triggered a $593 billion single-day wipeout of Nvidia's market cap, the Chinese AI lab is preparing to do it again. This time, the leaked benchmark numbers are even more alarming for Silicon Valley.
Internal testing data and code repository leaks suggest DeepSeek V4 will launch around February 17, 2026, coinciding with Lunar New Year. According to sources cited by The Information and technical analysis of DeepSeek's GitHub repositories:
If these numbers hold up under independent verification, V4 won't just be another incremental update. It will be proof that a Chinese startup can build frontier-class AI at a fraction of the cost while making it available to anyone with the right hardware.
The GitHub Leak That Started the Frenzy
The speculation around V4 shifted from rumor to something more concrete on January 20, 2026. Developers scanning DeepSeek's FlashMLA repository noticed something unusual: 28 references to an unknown identifier called "MODEL1" scattered across 114 files.
The code logic revealed that MODEL1 exists as a completely separate architecture from DeepSeek-V3.2 (codenamed "V32" in the repository). The differences weren't cosmetic. Developers identified changes in key-value cache layout, sparsity handling, and FP8 data format decoding, indicating a fundamental restructuring for memory optimization and computational efficiency.
The timing of the discovery felt deliberate. It landed on the one-year anniversary of DeepSeek R1's release, the model that sent shockwaves through global markets and forced Western AI labs to reconsider their assumptions about the relationship between compute spending and model capability.
Within hours, developers on Reddit's r/LocalLLaMA and r/Singularity communities were dissecting every commit. The analysis revealed compatibility with NVIDIA's forthcoming Blackwell architecture (SM100) alongside current Hopper GPUs, suggesting DeepSeek had been preparing MODEL1 for next-generation hardware that most Western labs were still waiting to receive.
DeepSeek has not officially commented on MODEL1 or confirmed any connection to V4. The company maintains its characteristic operational silence, a pattern it established before the R1 launch when it let the eventual release speak for itself.
What the Benchmark Leaks Actually Claim
The leaked performance data centers on coding, the capability with perhaps the clearest path to massive economic value. Here's what industry sources and internal testing reportedly show.
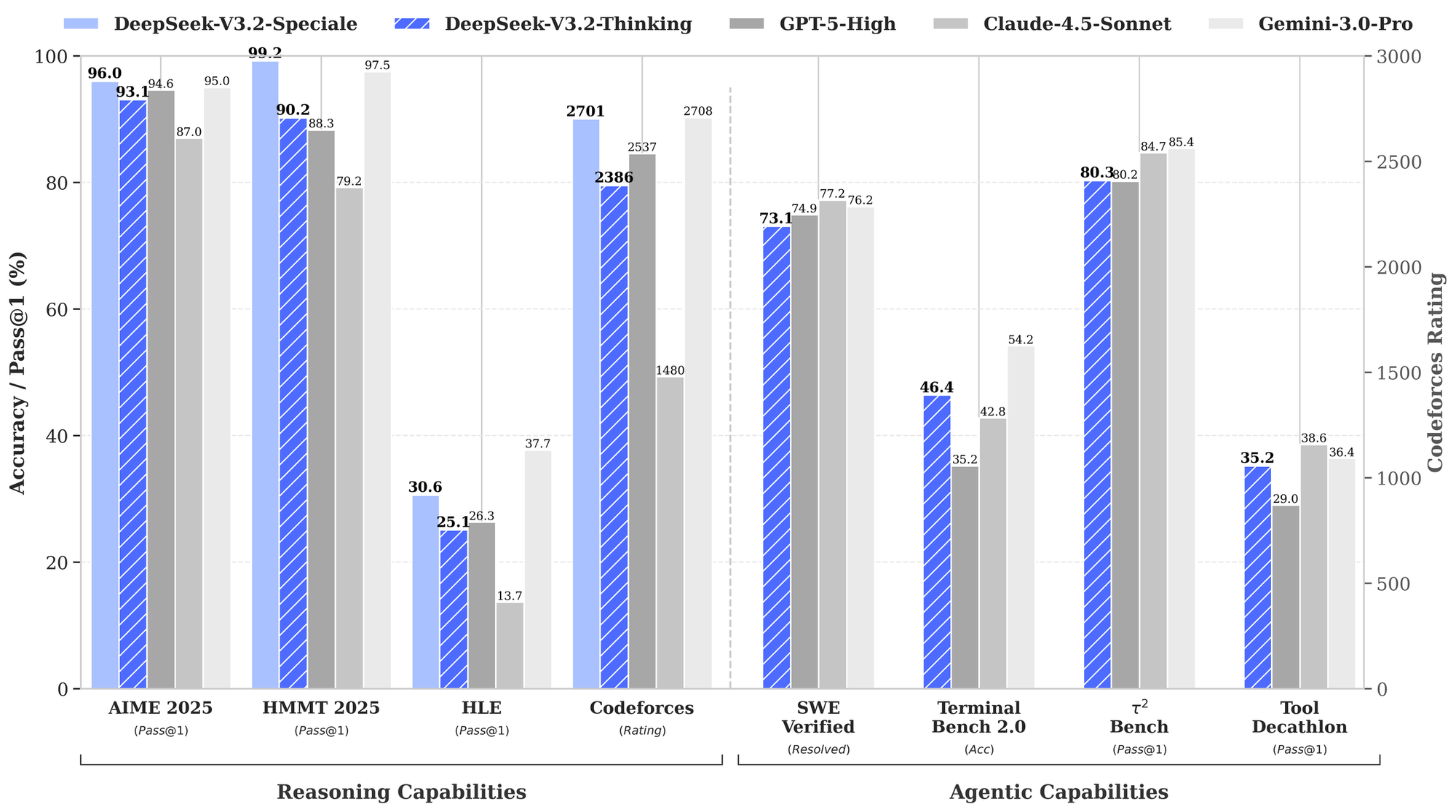
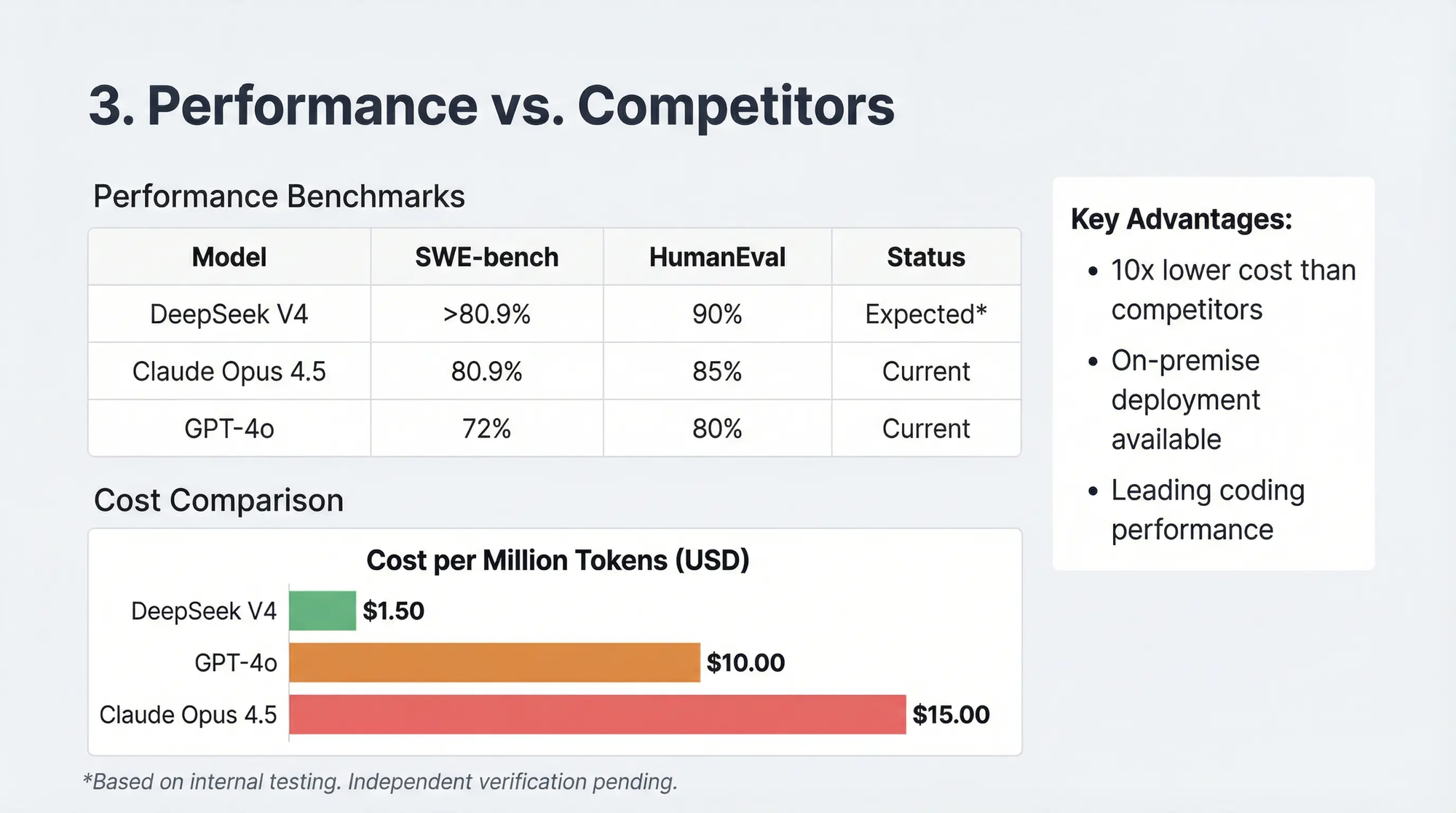
The more significant claim involves SWE-bench Verified. This benchmark presents models with 500 real GitHub issues from popular open-source projects and asks them to generate patches that actually fix the bugs. Claude Opus 4.5 currently leads with 80.9%, the first model to crack the 80% barrier. Internal sources claim V4 exceeds this threshold, though the exact number hasn't leaked.
Beyond raw benchmark scores, the architectural innovations matter. V4 reportedly supports a context window exceeding 1 million tokens, enough to process entire enterprise codebases in a single pass. This enables what developers call "repo-level reasoning," where the model understands relationships between components, traces dependencies across dozens of files, and maintains consistency during large-scale refactoring operations.
Early testers claim V4 can ingest a medium-sized codebase, understand the intricate import-export relationships across files, and perform autonomous refactoring that previously required a senior human engineer. If true, this moves AI coding assistance from "helpful autocomplete" toward genuine software engineering collaboration.
The Technical Architecture Behind the Claims
Two research papers published by DeepSeek in January 2026 provide the theoretical foundation for V4's reported capabilities.
The first, released January 1, introduces Manifold-Constrained Hyper-Connections (mHC). Traditional large language models lose signal as they get deeper with more layers. Information degrades as it passes through hundreds of transformer blocks. mHC creates connections that allow information to flow across layers more effectively, enabling models to learn faster and reason better without simply adding more parameters.
The second paper, submitted January 13, describes Engram, a conditional memory system that addresses what some researchers call the "Two Jobs Problem." Standard transformers use the same expensive computational resources for two conflicting tasks: recalling static facts (like Python syntax or API documentation) and performing dynamic reasoning (like debugging logic or architectural decisions). Using a massive H100 GPU to "remember" that import numpy as np is standard boilerplate wastes compute that could be used for actual problem-solving.
Engram separates these functions. It creates a massive, read-only external memory that sits between transformer layers. The system hashes input text and performs O(1) lookups in a table stored in system RAM rather than GPU VRAM. Static knowledge gets retrieved almost instantly, preserving precious GPU capacity for complex reasoning.
The reported result: a 100-billion-parameter embedding table entirely offloaded to host DRAM with throughput penalties below 3%. This allows V4 to "know" millions of static facts and code snippets without using GPU capacity, while maintaining the flexibility to reason through novel problems.
The FlashMLA leak suggests V4 combines these innovations with DeepSeek Sparse Attention (DSA), which reportedly reduces computational overhead by 50% compared to standard transformers while supporting the million-token context window.
The Cost Advantage That Keeps Western Labs Worried
DeepSeek's disruption has never been purely about performance. It's about achieving comparable performance at dramatically lower cost.
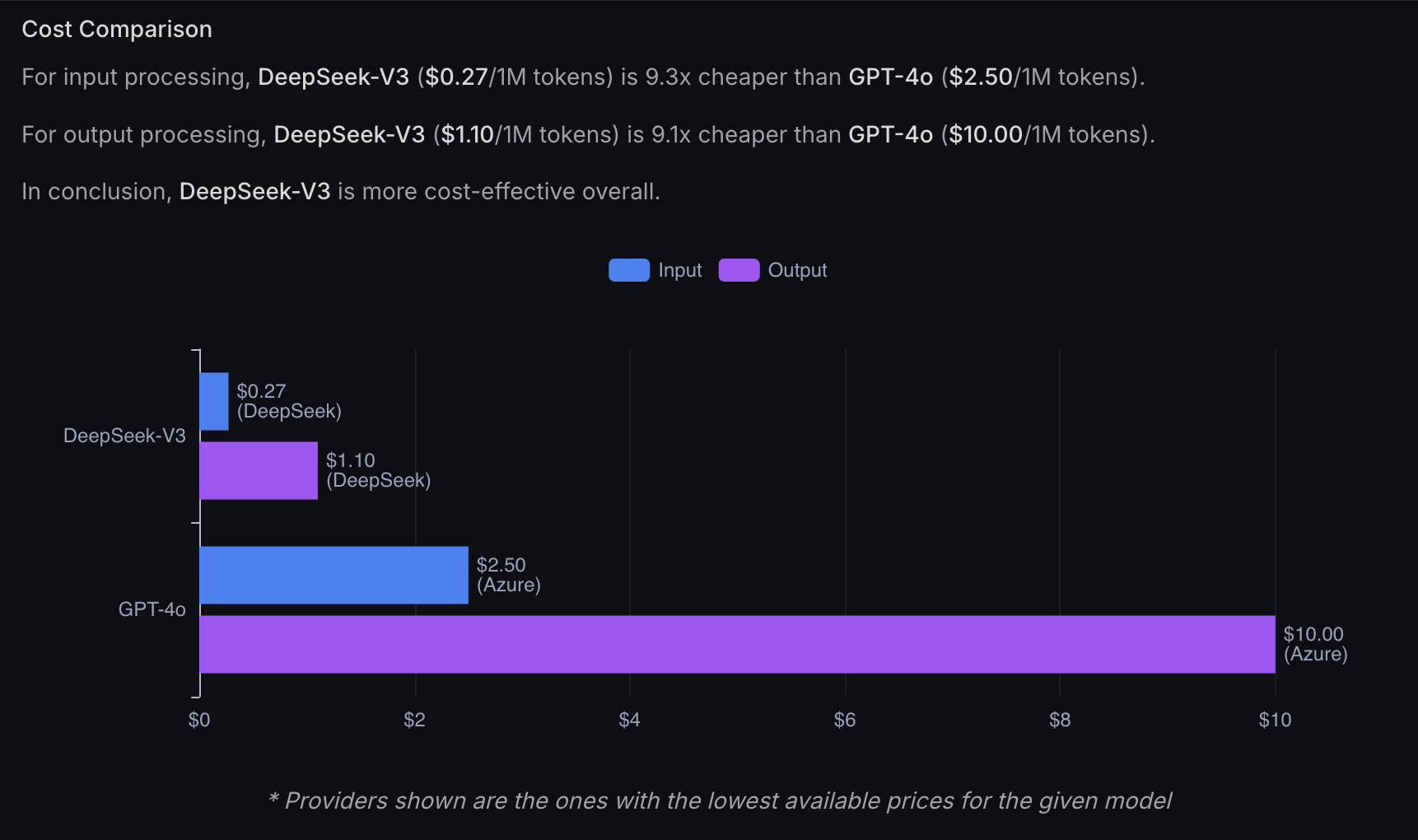
The company trained V3 for approximately $6 million, compared to estimates exceeding $100 million for GPT-4. DeepSeek uses around 2,000 GPUs instead of the 10,000 or more that Western labs deploy, achieving similar capabilities with a fraction of the infrastructure. API pricing runs 20 to 40 times cheaper than OpenAI's equivalent offerings.
V4 appears to continue this efficiency focus. The Mixture-of-Experts (MoE) architecture reportedly uses 1 trillion parameters total but only activates approximately 32 billion for any given token. This "Top-16" routing strategy maintains the specialized knowledge of a massive model without the crippling latency or hardware requirements usually associated with trillion-parameter systems.
For developers, the cost implications are significant. The open-weights release model that DeepSeek has followed with previous versions means organizations can run V4 entirely within their own infrastructure. For industries like finance, healthcare, and defense, this eliminates concerns about sending proprietary code to external APIs. Development teams in secure facilities can leverage frontier capabilities without network connectivity.
Consumer-grade hardware can run quantized versions. Dual NVIDIA RTX 4090s or a single RTX 5090 can reportedly handle the model, making "GPT-5 class" intelligence accessible to individual developers and small teams.
The Security
DeepSeek's technical achievements exist in a complicated geopolitical context. The company's consumer app and cloud API have been banned from U.S. government devices across multiple federal agencies and states including Texas, New York, and Virginia.

The concerns center on data storage. DeepSeek's privacy policy acknowledges that all user data is stored on servers in China, where the 2017 National Intelligence Law requires organizations to "support, assist, and cooperate with national intelligence efforts." Chinese authorities can legally compel DeepSeek to hand over user data upon request, with no requirement to notify affected users.
Cybersecurity firm Feroot Security discovered hidden code in DeepSeek's web platform capable of transmitting user data to China Mobile's authentication registry. Congress has advanced the bipartisan "No DeepSeek on Government Devices Act" to formalize restrictions.
For private users and enterprises, the situation is more nuanced. Running open-weight models locally eliminates data transmission to DeepSeek's servers entirely. The code is open source under an MIT license, meaning anyone can inspect it, modify it, and deploy it in air-gapped environments with no external connectivity.
This creates an interesting split. Enterprise adoption of DeepSeek's cloud services faces legitimate security barriers. But the open-weights models themselves can be downloaded, verified, and run locally without any data ever reaching Chinese servers. Organizations must evaluate their specific risk tolerance and compliance requirements, but local deployment effectively sidesteps the data sovereignty concerns that drive government bans.
What This Means for the AI Coding Market
The AI coding assistant market has matured rapidly. By 2026, 91% of engineering organizations use AI coding tools. GitHub Copilot leads with 42% market share and runs in 90% of Fortune 100 companies. Cursor has captured 18% with $1 billion in annual recurring revenue. Claude Code claims 53% overall adoption in enterprise contexts.
Developers aren't asking whether to use AI. They're debating which tool delivers the best token efficiency, context management, and first-pass accuracy. Productivity data shows developers self-report 10-30% gains and save an average of 3.6 hours per week. GitHub Copilot users complete 126% more projects weekly.
V4 enters this mature landscape with a distinctive value proposition: potentially superior coding performance at dramatically lower cost, with local deployment options that eliminate both API fees and data sovereignty concerns.
The challenge for DeepSeek isn't just benchmark wins. GitHub Copilot's dominance comes partly from seamless integration with existing developer workflows. Enterprise customers value integration ecosystems, SLAs, and regulatory compliance alongside raw model capability.
But if V4 delivers what the leaks suggest, the economic math becomes hard to ignore. Why pay for subscription-based closed-source models when an open-weights alternative performs equally well or better and can run on hardware you already own?
The Verification Problem
All of this comes with a critical caveat: no public benchmarks exist yet. The numbers circulating come from internal testing and leaked code analysis, not independent verification.
The AI industry has learned to demand receipts. Insider claims mean nothing until the model ships and independent testers can reproduce results. DeepSeek hasn't even officially confirmed V4's existence, let alone its performance characteristics.
The key tests to watch when V4 launches include SWE-bench Verified for software engineering tasks, HumanEval for code generation, MATH-500 for mathematical reasoning, and LiveCodeBench for competitive programming. Community evaluations will flood social media and AI forums within hours of release. Expect quantized versions for platforms like Ollama and vLLM within days.
The benchmark comparisons will be contentious. Model performance increasingly depends on specific evaluation setups, prompt engineering, and tool configurations. A model might score higher on one benchmark while performing worse on tasks that matter to your specific use case.
For developers planning to evaluate V4 for production use, the recommendation is straightforward: wait for independent benchmarks, test on your specific use cases, and don't commit to infrastructure changes until you've validated performance on problems that matter to you.
Wrap up
DeepSeek V4 arrives at an inflection point in the AI industry. The assumption that frontier capabilities require frontier budgets is being challenged not just by DeepSeek, but by a broader trend toward efficiency-focused research.
OpenAI's o3-mini, released in early 2026, reflects this shift, a smaller, cheaper model aimed at competing on efficiency rather than just capability. Google has repeatedly reduced Gemini API costs throughout 2024 and 2025 in response to competitive pressure. The era of unlimited AI infrastructure spending may be giving way to more disciplined economics.
DeepSeek's consistent pattern of exceeding expectations while challenging assumptions about what's possible with limited resources has already reshaped industry dynamics once. If the mid-February 2026 timing holds and the reported capabilities prove accurate, V4 will force every organization using AI for software development to reconsider their options.
The combination of strong coding performance, open weights, and dramatically lower costs is difficult to ignore, regardless of one's views on the geopolitical complications. For American developers watching this space, the recommendation is simple: pay attention, prepare to evaluate, and let the benchmarks speak for themselves.
FAQ
What is DeepSeek V4?
DeepSeek V4 is the upcoming flagship large language model from the Chinese AI lab DeepSeek, expected to launch around mid-February 2026. According to leaked information and internal testing data, V4 focuses heavily on code generation capabilities and represents a fundamental architectural redesign rather than an incremental update to previous models.
When will DeepSeek V4 be released?
Based on reports from The Information and analysis of DeepSeek's development patterns, V4 is expected to launch around February 17, 2026, coinciding with the Lunar New Year. This timing mirrors DeepSeek's R1 launch strategy from January 2025. DeepSeek has not officially confirmed any release date.
What do the leaked benchmarks show?
Leaked internal testing reportedly shows V4 achieving 90% on HumanEval coding benchmarks (compared to Claude's 88% and GPT-4's 82%) and exceeding 80% on SWE-bench Verified, the current industry-leading score held by Claude Opus 4.5 at 80.9%. These numbers have not been independently verified.
What is the MODEL1 GitHub leak?
On January 20, 2026, developers discovered 28 references to an identifier called "MODEL1" across 114 files in DeepSeek's FlashMLA repository. Analysis revealed MODEL1 as a completely separate architecture from DeepSeek V3.2, with changes to memory handling, sparsity processing, and next-generation GPU support. Industry observers believe MODEL1 is the internal codename for V4.
What is Engram and why does it matter?
Engram is a conditional memory system described in a DeepSeek research paper from January 2026. It separates static knowledge retrieval (like syntax and API documentation) from dynamic reasoning, using O(1) hash-based lookups stored in system RAM rather than expensive GPU memory. This allows the model to "remember" millions of facts without consuming computational resources needed for actual problem-solving.
Can DeepSeek V4 run locally?
Based on DeepSeek's pattern with previous releases, V4 is expected to be released with open weights under an MIT license. The Mixture-of-Experts architecture reportedly allows the model to run on consumer-grade hardware including dual RTX 4090s or a single RTX 5090 for quantized versions. Local deployment eliminates data transmission to external servers.
Is DeepSeek banned in the United States?
DeepSeek's consumer app and cloud API have been banned from U.S. government devices across multiple federal agencies and states including Texas, New York, and Virginia due to data privacy and national security concerns. Private users can still access DeepSeek, and open-weight models that run locally are not affected by these restrictions since no data is transmitted to DeepSeek's servers.
How does DeepSeek V4 compare to Claude Opus 4.5 and GPT-5.2?
According to leaked benchmarks, V4 reportedly outperforms both Claude and GPT models on coding-specific tasks like HumanEval and SWE-bench. Claude may retain advantages in conversational nuance and general reasoning, while GPT-5.2 excels at general-purpose tasks. The key differentiator for V4 is the combination of competitive performance at dramatically lower cost with local deployment options.
How much does DeepSeek V4 cost?
DeepSeek's API pricing historically runs 20 to 40 times cheaper than OpenAI's equivalent offerings. For organizations that deploy the open-weights model locally, the only costs are hardware and electricity. This represents a potential 90%+ savings compared to subscription-based closed-source alternatives for teams with appropriate infrastructure.
What should developers do to prepare for DeepSeek V4?
Monitor the Hugging Face leaderboard and AI forums starting mid-February for independent benchmark results. Prepare Ollama or vLLM instances for testing. Evaluate your specific use cases rather than relying solely on benchmark scores. Consider your organization's data governance requirements and whether local deployment is appropriate. Wait for independent verification before committing to infrastructure changes.
Related Articles













