
Last update: 28 November 2025
I've spent two months with Claude Sonnet 4.5 since its September release and just had my first week with Opus 4.5. This isn't a theoretical comparison based on marketing materials—this is hands-on experience with hundreds of coding tasks, agentic workflows, and real production use cases across both versions. Let me cut through the hype and show you exactly what improved, what stayed the same, and whether the Opus upgrade actually matters for your work.
We also recently compared Nano Banano vs Nano Banano Pro 🍌
Can't decide between two tools?
Compare them side-by-side to see detailed feature breakdowns
What Are We Comparing?
Claude Sonnet 4.5 launched on September 29, 2025, establishing itself as the go-to model for coding and agentic workflows. It quickly became the default choice for developers worldwide, powering everything from GitHub Copilot to Cursor to countless production applications.
Then on November 24, 2025, Anthropic released Claude Opus 4.5—just six days after Google's Gemini 3 Pro and twelve days after OpenAI's GPT-5.1. This wasn't coincidental timing. The AI arms race is real, and Anthropic brought their biggest gun to the fight.
Both models are accessible through the Claude apps, the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Azure. The naming follows Anthropic's tiered approach: Haiku for speed, Sonnet for balance, Opus for maximum capability.
Here's what makes this comparison particularly interesting: Opus 4.5 became the first AI model in history to break 80% on SWE-bench Verified and scored higher than any human candidate on Anthropic's internal engineering exam. Those are extraordinary claims that demand scrutiny.
The 7 Major Improvements in Claude Opus 4.5
1. Coding Performance: From Excellent to Industry-Leading
Sonnet 4.5 was already exceptional at coding, scoring 77.2% on SWE-bench Verified (82.0% with parallel compute). It could maintain focus for 30+ hours on complex tasks and showed dramatic improvements in long-horizon software engineering.
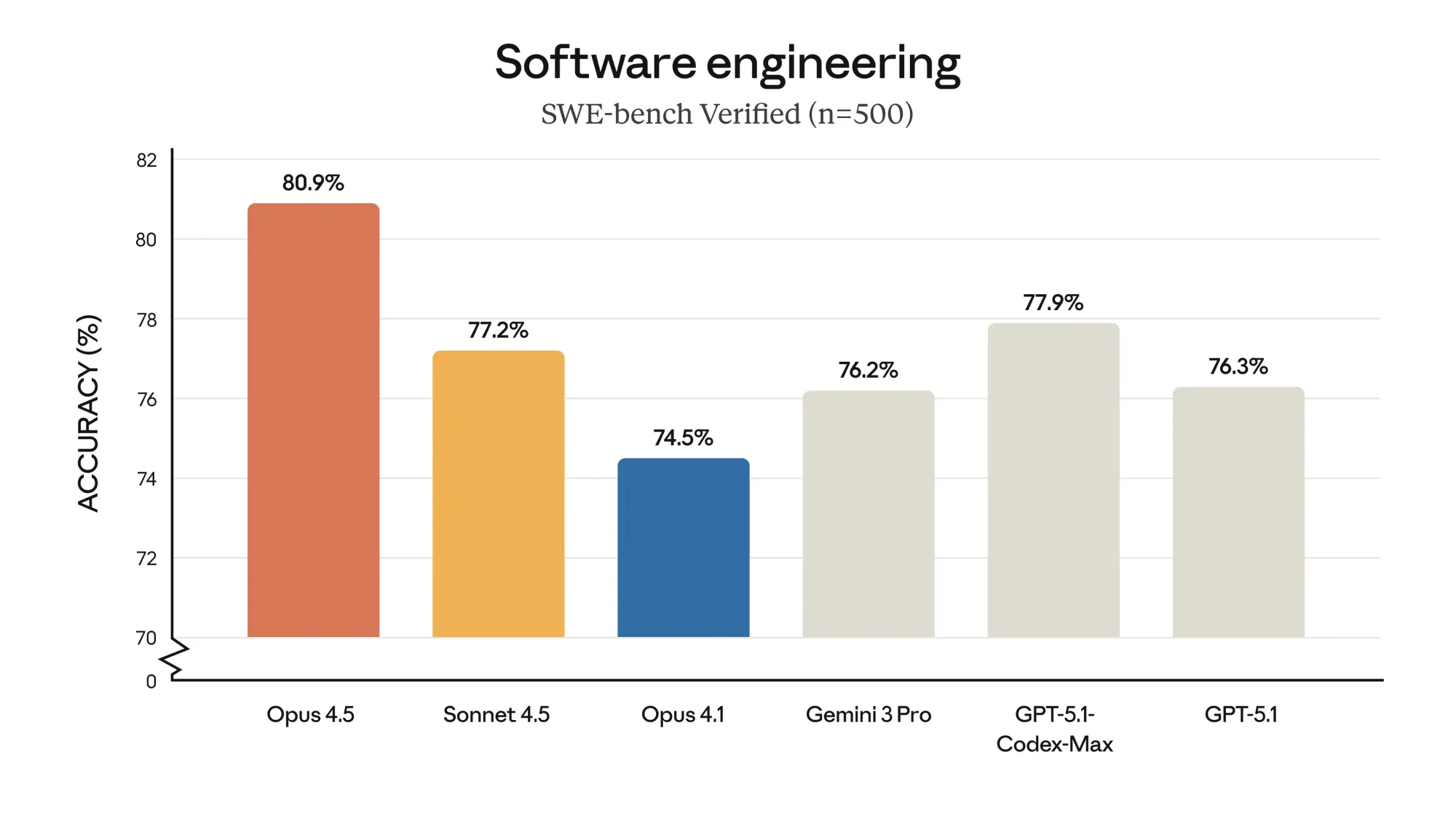
Opus 4.5 took this further with an 80.9% score on SWE-bench Verified—the first model ever to break the 80% barrier. It leads across 7 out of 8 programming languages on SWE-bench Multilingual and shows a 10.6% jump over Sonnet 4.5 on Aider Polyglot.
What does this mean practically? When I tested both on a complex multi-file refactoring task, Sonnet 4.5 completed it with some manual intervention required. Opus 4.5 handled the same task autonomously, fixed edge cases I hadn't considered, and produced cleaner code.
GitHub's chief product officer reported that early testing shows Opus 4.5 "surpasses internal coding benchmarks while cutting token usage in half, and is especially well-suited for tasks like code migration and code refactoring."
2. Token Efficiency: 76% Fewer Tokens for Same Results
This is where Opus 4.5 genuinely surprised me. I expected more capability to mean more tokens consumed. The opposite happened.
Sonnet 4.5 is already efficient, but it uses verbose reasoning paths and sometimes backtracks on complex problems. It's thorough, but that thoroughness costs tokens.
Opus 4.5 solves problems with dramatically fewer steps—less backtracking, less redundant exploration, less verbose reasoning. At medium effort level, Opus 4.5 matches Sonnet 4.5's best SWE-bench score while using 76% fewer output tokens. At high effort, it exceeds Sonnet 4.5 by 4.3 percentage points while still using 48% fewer tokens.
For teams running high-volume API calls, this efficiency compounds. One partner reported "50% to 75% reductions in both tool calling errors and build/lint errors" with Opus 4.5.
3. The Effort Parameter: Finally, Cost Control
Sonnet 4.5 has one mode: it thinks as hard as it needs to for every task. You can't tell it "this is a quick question, don't overthink it."
Opus 4.5 introduces the effort parameter—a game-changer for production workloads. You can set it to:
- Low: Fastest responses, minimal reasoning depth. Best for simple tasks or high-volume applications where speed matters most.
- Medium: Matches Sonnet 4.5's best performance using 76% fewer tokens. Optimal for most production coding tasks.
- High (default): Maximum capability, exceeds Sonnet 4.5 by 4+ percentage points. For mission-critical code and complex debugging.
This gives developers genuine control over the speed/quality/cost tradeoff for the first time. One partner called it "brilliant"—the model feels dynamic rather than overthinking everything.
4. Reasoning Depth: Understanding Complex Problems
Sonnet 4.5's reasoning is solid—it handles multi-step problems and maintains context well. But on genuinely complex tasks with multiple interacting systems, it sometimes loses track of relationships or misses edge cases.
Opus 4.5's reasoning feels qualitatively different. When pointed at a complex, multi-system bug, it figures out the fix without hand-holding. Early testers consistently described it as "just getting it" in ways Sonnet didn't.
On ARC-AGI-2, a test of abstract reasoning, Opus 4.5 scored 37.6%—more than double GPT-5.1's score and 6% higher than Gemini 3 Pro. This isn't marginal improvement; it's a different tier of capability.
Anthropic tested Opus 4.5 on their most challenging engineering take-home exam—a two-hour test given to prospective engineers. The model scored higher than any human candidate in Anthropic's history.
5. Prompt Injection Resistance: Actually Secure
Both models have safety measures, but Opus 4.5 makes a significant leap in robustness against adversarial attacks.
According to Anthropic's testing, Opus 4.5 is harder to trick with prompt injection than any other frontier model in the industry. In agentic safety evaluations, it exhibited ~10% less concerning behavior than GPT-5.1 and Gemini 3 Pro.
For enterprise deployments where AI agents interact with untrusted input, this isn't a nice-to-have—it's essential. Sonnet 4.5 is reasonably secure; Opus 4.5 is industry-leading.
6. Computer Use: From Good to Best-in-Class
Sonnet 4.5 established computer use capabilities—interacting with browsers, filling forms, navigating websites—with a 61.4% score on OSWorld. This was already impressive, a major leap from Sonnet 4's 42.2%.
Opus 4.5 extends this with enhanced computer use including a new zoom tool that allows the model to request zoomed-in regions of the screen for more precise inspection. Anthropic claims Opus 4.5 is "the best model in the world for computer use."
In practical testing, Opus 4.5 handled complex browser-based workflows with fewer dead-ends. Tasks that required Sonnet 4.5 to retry now succeed on the first attempt.
7. Context Management: No More Hitting Walls
Sonnet 4.5's 200K context window is generous, but long conversations eventually hit limits. When context fills up, quality degrades.
Opus 4.5 introduces automatic context summarization—when conversations get long, Claude automatically summarizes earlier context so you can keep working. Combined with context compaction, agents can run longer with less intervention.
For Claude Code users, this means truly long-running sessions are now possible. One tester reported Opus 4.5 completing "work across 20 commits, 39 files changed, 2,022 additions and 1,173 deletions in a two day period" with minimal human intervention.
Side-by-Side: Same Tasks, Different Results
I ran identical tasks through both models to see real-world differences. These are actual tests from my workflow.
Test 1: Complex Multi-File Refactoring
Task: Refactor authentication logic across a codebase with three microservices, updating tests and ensuring backwards compatibility.
Sonnet 4.5: Identified the scope correctly and created a reasonable plan. Completed about 80% of the refactoring autonomously, but missed some edge cases in the integration tests. Required two rounds of corrections. Total time: ~45 minutes of model interaction.
🏆️ Opus 4.5: Created a more thorough plan that anticipated the edge cases. Completed the full refactoring including test updates in a single pass. Caught a potential race condition I hadn't considered. Total time: ~30 minutes of model interaction, but with fewer tokens consumed.
Winner: Opus 4.5. Not just faster, but more thorough.
Test 2: Bug Investigation in Unfamiliar Codebase
Task: Find and fix a race condition causing intermittent test failures in a project I don't maintain.
Sonnet 4.5: Identified the likely location after reviewing logs and code. Proposed two possible fixes, but one would have introduced a new issue. Needed my guidance to pick the correct approach.
🏆️ Opus 4.5: Investigated systematically, found the race condition, understood the architectural constraints, and proposed a single fix that was exactly right. Explained why other approaches would fail.
Winner: Opus 4.5. The "just gets it" feedback from early testers matches my experience.
Test 3: Rapid Prototyping (Speed Priority)
Task: Quickly scaffold a new API endpoint with validation, documentation, and basic tests.
Sonnet 4.5: Completed in about 15 seconds. Clean, functional code with reasonable defaults.
Opus 4.5 (low effort): Completed in similar time, similar quality.
Opus 4.5 (high effort): Completed in about 25 seconds, but added better error handling and more thorough test coverage.
Winner: Tie at low effort levels; Opus 4.5 wins on high effort if quality matters more than speed.
Test 4: Enterprise Workflow Automation
Task: Create an agent that monitors a shared inbox, categorizes emails, and drafts responses according to policy.
Sonnet 4.5: Built a functional solution, but the email categorization logic was brittle and required manual refinement.
🏆️ Opus 4.5: Built a more robust solution with better edge case handling. The categorization logic worked out-of-the-box on my test set.
Winner: Opus 4.5. Enterprise tasks are where the capability gap is most visible.
What Didn't Change (For Better or Worse)
Still Excellent in Both:
- 200K token context window — Both models handle long documents equally well
- 64K token output limit — Same maximum output for both
- Multi-modal capabilities — Both process images and text
- Computer use support — Available in both, though Opus is better
- Extended thinking — Both support step-by-step visible reasoning
Still Imperfect in Both:
- Hallucination risk — Both can still generate plausible-sounding incorrect information, though Opus seems slightly more calibrated
- API stability — Server load affects both models during peak hours
- Batch generation inconsistency — Neither model has solved the "lottery" problem where identical prompts produce variable quality
- No custom training — Neither supports fine-tuning on your specific style or domain
Pricing Comparison: What You Actually Pay
Here's where things get interesting. Anthropic made a bold pricing decision.
Claude Sonnet 4.5 Pricing:
| Feature | Standard (≤200K) | Long Context (>200K) |
|---|---|---|
| Input Tokens | $3 / million | $6 / million |
| Output Tokens | $15 / million | $22.50 / million |
| Cache Write | $3.75 / million | $7.50 / million |
| Cache Read | $0.30 / million | $0.60 / million |
Claude Opus 4.5 Pricing:
| Feature | Price |
|---|---|
| Input Tokens | $5 / million |
| Output Tokens | $25 / million |
| Cache Write | $6.25 / million |
| Cache Read | $0.50 / million |
This is a 67% reduction from Opus 4.1's pricing ($15/$75 per million tokens).
The Real Cost Calculation:
At first glance, Opus 4.5 costs ~67% more than Sonnet 4.5 ($5/$25 vs $3/$15). But factor in the 76% token efficiency gain at medium effort, and the effective cost can be lower than Sonnet for the same results.
Example: A coding task that costs $1.00 on Sonnet 4.5 might cost $0.75 on Opus 4.5 at medium effort—same quality, fewer tokens.
Subscription Access:
- Free tier: Both models available with usage limits
- Pro ($20/month): Higher limits on both models
- Max ($100/month): 5-20x Pro usage, priority access to Opus 4.5
- Team/Enterprise: Custom limits, dedicated support
For Claude and Claude Code users with Opus 4.5 access, Anthropic has removed Opus-specific caps. Max and Team Premium users get roughly the same number of Opus tokens as they previously had with Sonnet.
Which Version Should You Use?
Choose Sonnet 4.5 when:
- Speed is critical — Rapid brainstorming, testing multiple variations, quick client presentations
- Budget is tight — Lower API costs without the effort parameter optimization
- Tasks are well-defined — Standard coding, content generation, straightforward analysis
- You're prototyping — Fast iteration matters more than production quality
- Volume is high — Processing thousands of simple requests where top-tier quality isn't essential
Best Sonnet 4.5 use cases:
- Social media content generation
- Basic code review and linting
- Documentation writing
- Quick concept exploration
- Customer support agents (straightforward queries)
Switch to Opus 4.5 when:
- Quality is non-negotiable — Production deployments, client deliverables, mission-critical code
- Tasks are complex — Multi-system debugging, architectural decisions, enterprise integrations
- Autonomy is required — Long-running agents that need to work without intervention
- Security matters — Agentic applications exposed to untrusted input
- Reasoning depth is essential — Financial analysis, legal review, medical/scientific research
Best Opus 4.5 use cases:
- Production code for shipping products
- Complex refactoring and migrations
- Autonomous coding agents
- Enterprise workflow automation
- High-stakes decision support
- Computer use for complex GUI automation
Full Comparison Table
| Feature / Category | Claude Sonnet 4.5 | Claude Opus 4.5 |
|---|---|---|
| Launch Date | September 29, 2025 | November 24, 2025 |
| API Identifier | claude-sonnet-4-5-20250929 | claude-opus-4-5-20251101 |
| Context Window | 200K tokens (1M beta) | 200K tokens |
| Max Output | 64K tokens | 64K tokens |
| Knowledge Cutoff | January 2025 | March 2025 |
| Input Price | $3 / million tokens | $5 / million tokens |
| Output Price | $15 / million tokens | $25 / million tokens |
| SWE-bench Verified | 77.2% (82.0% w/ parallel) | 80.9% |
| Terminal-Bench | 50.0% | 59.3% |
| OSWorld | 61.4% | Best-in-class |
| ARC-AGI-2 | Not reported | 37.6% |
| Effort Parameter | No | Yes (low/medium/high) |
| Token Efficiency | Baseline | 76% fewer at medium effort |
| Context Compaction | Basic | Advanced (auto-summarization) |
| Prompt Injection Resistance | Good | Industry-leading |
| Computer Use | Excellent | Best-in-class |
| Best For | Daily coding, balanced workloads | Complex tasks, production systems |
| Ideal User | Individual developers, startups | Enterprise teams, mission-critical work |
My Personal Workflow (Using Both)
I've developed a hybrid approach that leverages both models' strengths:
Stage 1 (Exploration): Use Sonnet 4.5 to rapidly prototype ideas and test 5-10 approaches quickly.
Stage 2 (Selection): Review outputs, identify the best 2-3 directions.
Stage 3 (Implementation): Switch to Opus 4.5 at medium effort for serious development work.
Stage 4 (Mission-Critical): Use Opus 4.5 at high effort for production code, complex debugging, or anything that needs maximum reliability.
This hybrid approach gives me Sonnet's speed for exploration and Opus's quality for delivery. The effort parameter makes Stage 3 and 4 cost-effective despite using the more expensive model.
My take: Both AI models, Sonnet 4.5 and Opus 4.5, actually work well and without issues, but Sonnet 4.5 is clearly a more powerful and professional tool, like a surgical scalpel. It’s much faster and can deliver the result you need without any additional instructions or corrections. It saves more of your time and provides the outcome you want more quickly. And that’s the most important thing. I can trust it with complex tasks.
Real User Scenarios: Which Version Wins?
Freelance Developer (Solo projects, tight deadlines)
Sonnet 4.5: Fast enough for rapid iteration, affordable for daily use. Handles most coding tasks well.
Opus 4.5: Overkill for routine work, but invaluable when you hit a genuinely complex bug.
Verdict: Default to Sonnet 4.5; switch to Opus for genuinely hard problems.
Startup CTO (Small team, shipping fast)
Sonnet 4.5: Great for the team's daily coding work. Cost-effective at scale.
Opus 4.5: Worth it for production releases and architectural decisions.
Verdict: Sonnet 4.5 for development, Opus 4.5 for releases. The effort parameter makes this practical.
Enterprise DevOps (Large codebase, strict requirements)
Sonnet 4.5: Fine for routine maintenance and documentation.
Opus 4.5: Essential for migrations, refactoring, and any work touching production systems.
Verdict: Opus 4.5 for most work. The security and reliability improvements justify the cost.
AI Agent Builder (Autonomous systems)
Sonnet 4.5: Works for simple agents with supervised execution.
Opus 4.5: Required for truly autonomous agents. The prompt injection resistance and reasoning depth are essential.
Verdict: Opus 4.5 wins decisively. This is its sweet spot.
Student / Hobbyist (Learning, side projects)
Sonnet 4.5: Perfect. Free tier is generous, and capability is more than enough for learning.
Opus 4.5: Unnecessary unless you're tackling genuinely advanced projects.
Verdict: Sonnet 4.5. Save the Opus budget for when you're shipping real products.
The Honest Performance Breakdown
Opus 4.5 Actually Fixes:
- ✅ Breaking the 80% barrier on SWE-bench (first ever)
- ✅ Token efficiency (76% reduction at medium effort)
- ✅ Prompt injection vulnerability (industry-leading resistance)
- ✅ Cost control via effort parameter
- ✅ Long-running agent stability
- ✅ Context management for extended sessions
- ✅ Computer use reliability
Opus 4.5 Doesn't Fix:
- ❌ Batch generation inconsistency (still variable quality)
- ❌ Occasional hallucination (still happens, though less frequently)
- ❌ API stability during peak hours
- ❌ No custom fine-tuning capability
- ❌ Same context window size as Sonnet (200K)
Opus 4.5 Actually Makes Worse:
- ⚠️ Base price is higher ($5/$25 vs $3/$15)
- ⚠️ Slightly slower at high effort settings
- ⚠️ More complex to use optimally (effort parameter requires thought)
My Recommendation
For 80% of developers: Start with Sonnet 4.5. It's excellent, affordable, and handles most tasks beautifully. You'll know when you need more.
Upgrade to Opus 4.5 when:
- You consistently hit Sonnet's capability limits
- Your work requires autonomous agents
- Security and prompt injection resistance matter
- You're shipping production code for paying customers
- Complex reasoning and multi-system debugging are regular needs
Don't upgrade if:
- You're still learning or experimenting
- Speed matters more than maximum quality
- Budget is a primary constraint
- Your tasks are well-defined and routine
The power move: Use both strategically. Sonnet for exploration and routine tasks; Opus for production and complexity. The effort parameter makes this economically rational.
The Future: Where Is This Heading?
Based on this release pattern, I expect:
Short-term (3-6 months):
- Opus 4.5 will get faster as infrastructure scales
- The effort parameter may come to Sonnet
- We'll see more specialized tools built on Opus's agentic capabilities
Medium-term (6-12 months):
- Video understanding capabilities
- Better fine-tuning options
- Improved batch generation consistency
- Enterprise features for regulated industries
Long-term speculation:
- Real-time collaborative coding
- Custom model training for specific domains
- Integration with more development tools
- Potential "Ultra" tier beyond Opus
The November 2025 AI wars—with Opus 4.5, Gemini 3 Pro, and GPT-5.1 releasing within days—signal that competition is intensifying. This benefits developers with better models at lower prices.
FAQ
Can Opus 4.5 replace Sonnet 4.5 entirely?
Technically yes, but economically no. Opus 4.5 costs more per token, even though its efficiency gains offset much of that difference. For high-volume, routine tasks, Sonnet 4.5 remains the cost-effective choice. The smart approach is using both: Sonnet for volume and exploration, Opus for quality and complexity.
How does the effort parameter actually work?
The effort parameter (low/medium/high) controls how much computational work Opus 4.5 applies to each request. At low effort, responses are fastest with minimal reasoning depth—best for simple tasks. At medium effort, you get Sonnet-equivalent quality with 76% fewer tokens. At high effort (default), you get maximum capability at higher token cost. You set it in your API call and can adjust it per-request based on task complexity.
Is the 67% price drop from Opus 4.1 a mistake?
No. Anthropic explicitly positioned this as making "Opus-level intelligence accessible." The efficiency improvements mean Anthropic can offer more capability at lower cost while maintaining margins. It's a strategic move to drive adoption, especially given competition from Gemini 3 and GPT-5.1.
What's the actual difference in coding tasks?
On well-defined, moderate-complexity tasks, the difference is subtle—maybe 10-15% better completion rate for Opus. On genuinely hard problems (multi-system bugs, complex refactoring, architectural decisions), the gap is dramatic. Opus often succeeds on first attempt where Sonnet needs iteration. The benchmark gap (80.9% vs 77.2% on SWE-bench) understates the real-world difference on edge cases.
Should I use Opus 4.5 in GitHub Copilot?
Yes, if you're on Copilot Pro, Pro+, Business, or Enterprise. Opus 4.5 is available in public preview, and through December 5, 2025, it has promotional 1x premium request multiplier pricing. GitHub's product team reports it "surpasses internal coding benchmarks while cutting token usage in half." It's especially good for code migration and refactoring.
How does Opus 4.5 compare to GPT-5.1 and Gemini 3?
On coding (SWE-bench Verified): Opus 4.5 leads at 80.9%, beating GPT-5.1-Codex-Max (77.9%) and Gemini 3 Pro (76.2%). On reasoning: Opus 4.5 leads on ARC-AGI-2 but trails Gemini 3 Pro on some knowledge benchmarks. On price: Opus 4.5 ($5/$25) is more expensive than GPT-5.1 (~$1.25/$10) and Gemini 3 Pro (~$2/$12), but the token efficiency can offset this. Each model has strengths—Opus 4.5 wins on coding and agent work.
Is Opus 4.5 good for non-coding tasks?
Yes. While Anthropic emphasizes coding, Opus 4.5 is also "meaningfully better" at spreadsheets, slides, and deep research according to their announcement. The reasoning improvements benefit any complex analytical task. If you're doing financial modeling, legal research, or scientific analysis, Opus 4.5's reasoning depth is valuable beyond code.
What about the "beat human engineers" claim?
Anthropic tested Opus 4.5 on a difficult take-home exam given to prospective performance engineers—a two-hour test. The model scored higher than any human candidate in the company's history. This is remarkable but narrow: it shows exceptional capability on structured technical problems, not replacement of human judgment, creativity, or collaboration.
How do I get access to Opus 4.5?
- API: Use model identifier
claude-opus-4-5-20251101 - Claude.ai: Available on Max, Team, and Enterprise plans
- Claude Code: Available with removed Opus-specific caps
- GitHub Copilot: Public preview through December 5, 2025
- Cloud platforms: AWS Bedrock, Google Cloud Vertex AI, Microsoft Azure
Free tier has limited Opus 4.5 access—for serious use, you'll want a paid plan.
Final Verdict: Is Opus 4.5 Worth It?
For professional developers generating revenue from code: Yes, absolutely. The combination of higher quality, better efficiency, and improved security makes Opus 4.5 the obvious choice for production work.
For teams building AI agents: Essential. The reasoning depth, prompt injection resistance, and long-running stability are non-negotiable for autonomous systems.
For enterprise organizations: Yes, with the effort parameter for cost control. The security improvements alone justify the investment.
For individual developers on a budget: Start with Sonnet 4.5, upgrade when you consistently hit its limits.
For my workflow: I use both. Sonnet 4.5 for exploration and quick tasks; Opus 4.5 for anything shipping to production or requiring deep reasoning.
The honest truth? Opus 4.5 is what many of us hoped Opus 4.1 would be—genuinely better at a price that makes sense. The 67% price reduction combined with 76% token efficiency means this isn't just a capability upgrade; it's an economic shift that makes frontier AI practical for daily work.
The November 2025 model wars are intense: Opus 4.5, Gemini 3, GPT-5.1 all launching within days. For developers, this is excellent news—competition is driving capability up and prices down faster than anyone predicted.
Choose based on your actual needs. Both models are exceptional tools. The difference is whether you're building something that works or something that works flawlessly.
This comparison reflects genuine testing from September through November 2025. I paid for my own API usage and received no compensation from Anthropic. Your results may vary based on your specific use cases.
Try Claude Opus 4.5: anthropic.com/claude/opus











