
Last Updated: December 1 2025
Looking for an in-depth Claude Opus 4.5 review? You've come to the right place. On November 24, 2025, Anthropic released Claude Opus 4.5 — and it immediately became the talk of the AI community. Whether you're wondering "Is Claude Opus 4.5 better than GPT-5.1?" or searching for "Claude Opus 4.5 vs Gemini 3 Pro comparison," this comprehensive guide covers everything you need to know about Anthropic's most powerful AI model yet.
What is Claude Opus 4.5?
Claude Opus 4.5 is Anthropic's flagship large language model (LLM), released on November 24, 2025. It represents the pinnacle of the Claude 4.5 model family and is specifically engineered for advanced software development, autonomous AI agents, and complex task automation.
Claude Opus 4.5
If you've been asking yourself "What's the best AI for coding in 2025?" — Claude Opus 4.5 is currently the answer. It's the first AI model to score above 80% on SWE-bench Verified, the gold standard benchmark for real-world software engineering tasks.
TL;DR: Claude Opus 4.5 is the most capable AI coding assistant available today, beating both GPT-5.1 and Gemini 3 Pro on software engineering benchmarks while offering competitive pricing at $5 per million input tokens.
Key Takeaways
| Feature | Details |
|---|---|
| Model Name | Claude Opus 4.5 (claude-opus-4-5-20251101) |
| Release Date | November 24, 2025 |
| Developer | Anthropic |
| Primary Strengths | Coding, autonomous agents, computer use, long-term planning |
| SWE-bench Score | 80.9% (industry-leading) |
| Pricing | $5/million input tokens, $25/million output tokens |
| Best For | Software engineering, enterprise automation, agentic workflows |
| Availability | Claude.ai, API, AWS Bedrock, Google Cloud Vertex AI |
Claude Opus 4.5 vs GPT-5.1 vs Gemini 3 Pro: Head-to-Head Comparison
One of the most common questions we see is "How does Claude Opus 4.5 compare to ChatGPT?" or "Claude vs GPT-5.1 — which is better for coding?" Here's the definitive comparison:
Overall Ranking: Best AI Models for Coding (2025)
| Rank | Model | Best For | SWE-bench Verified | Price (per million tokens) | Rating |
|---|---|---|---|---|---|
| 🥇 1 | Anthropic Claude Opus 4.5 | Autonomous coding, agent coordination, long-term planning | 80.9% | $5 input / $25 output | ⭐⭐⭐⭐⭐ |
| 🥈 2 | OpenAI GPT-5.1 Codex-Max | Advanced reasoning, general AI tasks | 77.9% | Varies | ⭐⭐⭐⭐ |
| 🥉 3 | Google Gemini 3 Pro | Multimodal understanding, Google integration | 76.2% | Varies | ⭐⭐⭐⭐ |
Detailed Benchmark Comparison
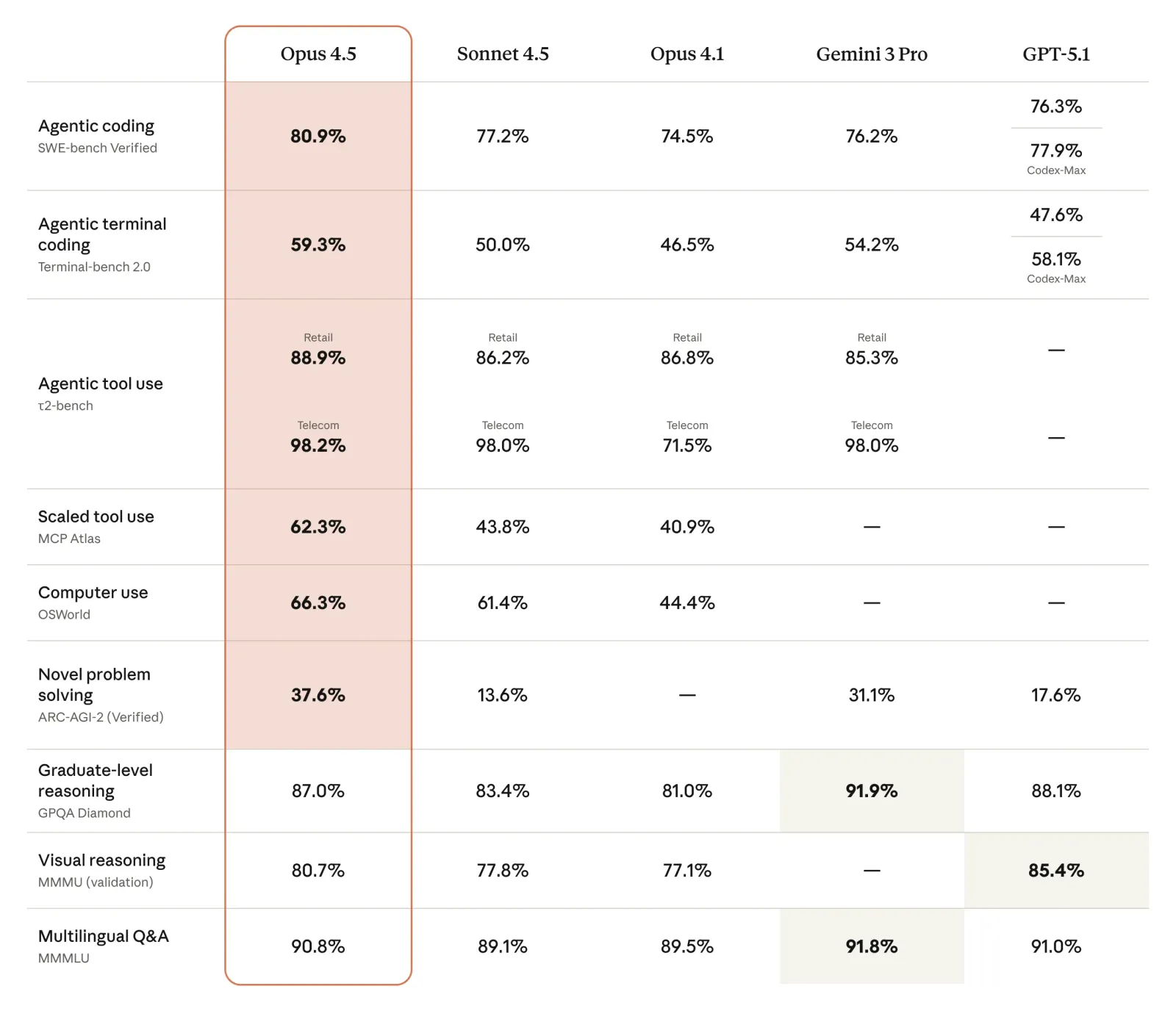
| Benchmark | Claude Opus 4.5 | GPT-5.1 | Gemini 3 Pro | What It Measures |
|---|---|---|---|---|
| SWE-bench Verified | 80.9% | 77.9% | 76.2% | Real-world bug fixing |
| Terminal-bench 2.0 | 59.3% | 58.1% | 54.2% | Command-line coding tasks |
| ARC-AGI-2 | 37.6% | 17.6% | 31.1% | Novel problem-solving |
| GPQA Diamond | 87.0% | — | 91.9% | Graduate-level reasoning |
| OSWorld | 66.3% | <40% | — | Computer use capability |
| MCP Atlas | 62.3% | — | — | Scaled tool use |
Bottom line: If you're looking for the best LLM for software development, Claude Opus 4.5 leads in coding-specific benchmarks. However, Gemini 3 Pro edges ahead in pure reasoning tasks like GPQA Diamond.
Claude Opus 4.5 Benchmark Results: The Numbers That Matter
SWE-bench Verified: First Model Above 80%
The SWE-bench Verified benchmark is considered the ultimate test for AI coding ability. It requires models to fix real bugs in actual GitHub repositories — not synthetic problems, but genuine issues from popular open-source projects.
Claude Opus 4.5 scored 80.9% — making it the first AI model ever to cross the 80% threshold. This is significant because:
- It represents a 3.7% improvement over Sonnet 4.5 (77.2%)
- It beats GPT-5.1 Codex-Max by 3 percentage points
- It outperforms Gemini 3 Pro by 4.7 percentage points
Terminal-bench 2.0: Command-Line Mastery
For developers who spend significant time in terminal environments, Terminal-bench 2.0 measures the ability to solve coding tasks in a simulated shell environment.
- Claude Opus 4.5: 59.3%
- GPT-5.1 Codex-Max: 58.1%
- Gemini 3 Pro: 54.2%
- Sonnet 4.5: 50.0%
ARC-AGI-2: Abstract Reasoning
The ARC-AGI-2 benchmark tests fluid intelligence and novel problem-solving — tasks that can't simply be memorized from training data.
- Claude Opus 4.5: 37.6%
- Gemini 3 Pro: 31.1%
- GPT-5.1: 17.6%
This is a remarkable result — Opus 4.5 more than doubles GPT-5.1's score on this challenging benchmark.
Outperforming Human Engineers
Perhaps the most striking result: Anthropic tested Claude Opus 4.5 on their internal engineering take-home exam — the same test they give to prospective software engineering candidates.
Result: Claude Opus 4.5 scored higher than any human candidate in Anthropic's history, completing the 2-hour exam with superior accuracy.
This doesn't mean AI will replace engineers overnight, but it does signal a fundamental shift in what's possible with AI-assisted development.
Claude Opus 4.5 Pricing: How Much Does It Cost?
One of the most searched questions is "How much does Claude Opus 4.5 cost?" Good news: Anthropic slashed prices by 66% compared to the previous Opus generation.
Claude Opus 4.5 API Pricing
| Tier | Input Tokens | Output Tokens |
|---|---|---|
| Standard | $5 / million | $25 / million |
| Batch Processing | $2.50 / million | $12.50 / million |
| Prompt Caching (reads) | $0.50 / million | — |
| Prompt Caching (writes) | $6.25 / million | — |
Price Comparison: Opus 4.5 vs Previous Generation
| Model | Input Price | Output Price | Savings |
|---|---|---|---|
| Claude Opus 4.5 | $5/M | $25/M | — |
| Claude Opus 4.1 | $15/M | $75/M | 66% cheaper |
Is Claude Opus 4.5 Worth the Cost?
For comparison:
- Claude Opus 4.5 costs approximately 40% more than GPT-5.1 per token
- However, Opus 4.5 achieves 3% higher accuracy on SWE-bench
- For enterprise and complex coding tasks, the accuracy improvement often justifies the cost
Pro tip: Use the effort parameter (explained below) to reduce costs on simpler tasks while maintaining Opus-tier capability.
New Features in Claude Opus 4.5
1. Effort Parameter: Control Speed vs. Depth
The effort parameter is a game-changer for developers. It allows you to control how much "thinking time" Claude spends on a problem.
| Effort Level | Best For | Token Usage | Speed |
|---|---|---|---|
| Low | Boilerplate code, simple questions | Minimal | Fast |
| Medium | Standard development tasks | Balanced | Moderate |
| High | Complex debugging, architecture design | Maximum | Slower |
Key insight: At medium effort, Opus 4.5 matches Sonnet 4.5's best SWE-bench score while using 76% fewer output tokens.
2. Tool Search: 85% Token Reduction
Traditional AI models load all tool definitions upfront, consuming ~55,000 tokens before processing your request. Claude Opus 4.5 introduces Tool Search:
"Instead of loading all tool definitions upfront, the Tool Search Tool discovers tools on-demand. Claude only sees the tools it actually needs for the current task."
Result: 85% reduction in token usage while maintaining access to your full tool library.
3. Infinite Chat (Context Compaction)
Paid Claude users can now enjoy endless conversations without hitting context window limits. When the model approaches its context limit, it automatically compresses earlier context without interrupting the conversation.
4. Claude for Chrome
A browser extension that enables Claude to:
- Take actions across browser tabs
- Navigate multi-step web workflows
- Fill forms automatically
- Gather data from multiple sources
Availability: All Max subscribers
5. Claude for Excel
Direct integration with Microsoft Excel for:
- Data analysis
- Formula creation
- Report generation
- Spreadsheet automation
Availability: Max, Team, and Enterprise subscribers
6. Improved Prompt Injection Safety
Anthropic claims Claude Opus 4.5 is:
"The most robustly aligned model we have released to date and, we suspect, the best-aligned frontier model by any developer."
"Opus 4.5 is harder to trick with prompt injection than any other frontier model in the industry."
This is critical for enterprise deployments where security is paramount.
Autonomous Agents and Computer Use
Why Claude Opus 4.5 is the Best Model for AI Agents
If you're building AI agents or interested in autonomous AI coding, Claude Opus 4.5 offers significant advantages:
| Capability | Claude Opus 4.5 | Sonnet 4.5 | Opus 4.1 |
|---|---|---|---|
| MCP Atlas (scaled tool use) | 62.3% | 43.8% | 40.9% |
| OSWorld (computer use) | 66.3% | 61.4% | 44.4% |
| τ²-bench Retail | 88.9% | — | — |
| τ²-bench Telecom | 98.2% | — | — |
What These Benchmarks Mean
- MCP Atlas: Measures ability to orchestrate complex workflows using multiple tools and API interactions simultaneously
- OSWorld: Tests actual computer operation — navigating interfaces, managing files, executing tasks across desktop applications
- τ²-bench: Evaluates multi-turn agent performance in real-world scenarios (retail customer service, telecom support)
Multi-Agent Orchestration
Claude Opus 4.5 excels at acting as a lead agent coordinating multiple sub-agents. Anthropic's architecture enables:
- Opus 4.5 as the orchestrator/planner
- Haiku 4.5 models as specialized sub-agents
- Efficient task delegation and result synthesis
This is particularly powerful for enterprise workflows requiring sustained reasoning and multi-step execution.
Real-World Use Cases
Use Case 1: Agile Software Development Team
Profile: 10-person team developing a complex SaaS application
Stack: Claude Opus 4.5 + GitHub + Jira + CI/CD pipeline
Monthly Cost: ~$500-1,000
Results:
- ✅ 30% of critical bugs fixed autonomously
- ✅ 15% reduction in development cycles
- ✅ Automated code reviews and refactoring suggestions
Use Case 2: Enterprise IT Department
Profile: Large enterprise managing legacy systems and cloud-native applications
Stack: Claude Opus 4.5 + enterprise security tools + internal knowledge bases
Monthly Cost: ~$2,000-5,000
Results:
- ✅ Automated routine maintenance and patch management
- ✅ Intelligent incident diagnosis and response
- ✅ Legacy code analysis for migration planning
Use Case 3: Solo Developer / Indie Hacker
Profile: Individual developer building an MVP
Stack: Claude Opus 4.5 + Vercel + GitHub
Monthly Cost: ~$50-200
Results:
- ✅ Rapid prototyping with substantial code generation
- ✅ Comprehensive test suite creation
- ✅ Automatic API documentation
How to Access Claude Opus 4.5
Option 1: Claude.ai (Consumer)
Available to:
- Max subscribers: Full access
- Team subscribers: Full access
- Enterprise subscribers: Full access
Option 2: API Access
Model ID: claude-opus-4-5-20251101
Platforms:
- Anthropic API (direct)
- AWS Bedrock
- Google Cloud Vertex AI
Option 3: GitHub Copilot
Claude Opus 4.5 is available in public preview through GitHub Copilot.
Note: Promotional pricing (1x premium request multiplier) runs through December 5, 2025.
Option 4: Claude Code
For developers who prefer command-line workflows, Claude Code provides direct terminal access to Opus 4.5.
Advanced Techniques for Claude Opus 4.5
Technique 1: Effort Scaling for Cost Optimization
# Start with medium effort for planning
effort: medium → Get high-level architecture
# Increase for critical implementation
effort: high → Generate core business logic
# Decrease for boilerplate
effort: low → Generate standard CRUD operations
Technique 2: Multi-Agent Orchestration
Break large projects into interconnected tasks:
- Define specialized agents (API_Agent, DB_Agent, Frontend_Agent)
- Use Opus 4.5 to coordinate their actions
- Let sub-agents (Haiku 4.5) handle individual tasks
Technique 3: Test-Driven Development with Self-Correction
- Provide feature requirements
- Instruct Claude to write comprehensive tests first
- Then write code that passes those tests
- If tests fail, Claude debugs and corrects automatically
Technique 4: Proactive Security Auditing
Feed Claude sections of your codebase along with OWASP Top 10 patterns. Request:
- Vulnerability identification
- Patch proposals
- Security-hardening recommendations
Claude Opus 4.5 vs Claude Sonnet 4.5: Which Should You Choose?
| Factor | Choose Opus 4.5 | Choose Sonnet 4.5 |
|---|---|---|
| Task Complexity | Complex, multi-file changes | Single-file edits |
| Budget | Flexible | Constrained |
| Autonomy Required | High (agent workflows) | Moderate (assisted coding) |
| Token Efficiency | Use effort parameter | Default efficiency |
| Use Case | Enterprise, production | Development, prototyping |
Rule of thumb: If you need the best possible results and can afford the premium, choose Opus 4.5. For everyday coding assistance with good-enough quality, Sonnet 4.5 offers better value.
Common Myths About Claude Opus 4.5
Myth 1: "AI will replace software engineers"
Reality: Claude Opus 4.5 is a force multiplier, not a replacement. Engineers will shift focus from routine coding to architecture, design, and creative problem-solving.
Myth 2: "AI-generated code is less secure"
Reality: With improved prompt injection safety and adherence to best practices, AI can actually reduce human error. However, human oversight remains essential.
Myth 3: "You don't need to understand AI-generated code"
Reality: Understanding why code was generated and how to debug it remains critical. AI is a tool; proficiency requires understanding the output.
Myth 4: "AI can handle any task autonomously"
Reality: Novel problems, ambiguous requirements, and creative architectural decisions still require significant human input.
Frequently Asked Questions
What is Claude Opus 4.5?
Claude Opus 4.5 is Anthropic's most advanced AI model, released November 24, 2025. It's the first model to score above 80% on SWE-bench Verified, making it the leading AI for software engineering tasks.
How much does Claude Opus 4.5 cost?
Claude Opus 4.5 costs $5 per million input tokens and $25 per million output tokens. Batch processing is available at 50% discount ($2.50/$12.50).
Is Claude Opus 4.5 better than GPT-5.1 for coding?
Yes, for most coding tasks. Claude Opus 4.5 scores 80.9% on SWE-bench Verified compared to GPT-5.1's 77.9%. However, GPT-5.1 costs approximately 40% less per token.
Is Claude Opus 4.5 better than Gemini 3 Pro?
For coding and agentic tasks, yes. Claude Opus 4.5 leads on SWE-bench (80.9% vs 76.2%), Terminal-bench, and tool-use benchmarks. However, Gemini 3 Pro excels at graduate-level reasoning (GPQA Diamond).
What is the effort parameter in Claude Opus 4.5?
The effort parameter lets you control the balance between speed/cost and depth of analysis. Low effort = faster, cheaper responses. High effort = more thorough analysis for complex problems.
Can Claude Opus 4.5 use a computer?
Yes. Claude Opus 4.5 achieves 66.3% on OSWorld, demonstrating strong capability in navigating interfaces, managing files, and executing tasks across desktop applications.
When was Claude Opus 4.5 released?
Claude Opus 4.5 was released on November 24, 2025.
What is the Claude Opus 4.5 API model ID?
The model ID is claude-opus-4-5-20251101.
Does Claude Opus 4.5 support long conversations?
Yes. The new "Infinite Chat" feature allows conversations to continue without interruption by automatically compressing earlier context when approaching the context window limit.
Is Claude Opus 4.5 safe to use for enterprise applications?
Yes. Anthropic states that Opus 4.5 is "the most robustly aligned model we have released" and "harder to trick with prompt injection than any other frontier model in the industry."
Conclusion: Is Claude Opus 4.5 Worth It?
Claude Opus 4.5 represents a significant milestone in AI development. With its industry-leading 80.9% score on SWE-bench Verified, superior agentic capabilities, and improved safety features, it's currently the best AI model for software engineering.
Who Should Use Claude Opus 4.5?
✅ Enterprises needing reliable, secure AI for production workflows
✅ Development teams looking to accelerate coding cycles
✅ AI agent builders requiring sophisticated tool use and computer interaction
✅ Solo developers who want the best possible coding assistance
Who Might Consider Alternatives?
⚠️ Budget-constrained users — Sonnet 4.5 offers ~95% of the capability at lower cost
⚠️ Simple use cases — Haiku 4.5 may be sufficient for basic tasks
⚠️ Non-coding workloads — Gemini 3 Pro may edge ahead on pure reasoning
Final Verdict
If you're serious about leveraging AI for software development in 2025, Claude Opus 4.5 is the model to beat. The 66% price reduction makes it more accessible than ever, and features like the effort parameter help optimize costs without sacrificing capability.
Rating: ⭐⭐⭐⭐⭐ (5/5)
Related Searches
People also search for:
- Claude Opus 4.5 vs ChatGPT comparison
- Best AI coding assistant 2025
- Anthropic Claude pricing
- How to use Claude API
- Claude vs Copilot for coding
- AI agent frameworks 2025
- SWE-bench leaderboard
- Claude Opus 4.5 release notes
- Claude for enterprise
- Best LLM for developers
Did you find this Claude Opus 4.5 review helpful? Share it with your team or bookmark it for future reference. We update this guide as new information becomes available.










