

Two weeks after releasing Opus 4.6, Anthropic has pushed out another update. Claude Sonnet 4.6 is now live, and it is immediately taking over as the default model for both Free and Pro plan users on Claude.ai. That means the majority of people interacting with Claude on a daily basis are now running on the new version, whether they asked for it or not.
That kind of deployment speed is worth paying attention to. Anthropic has been running on a roughly four-month update cycle for its Sonnet line, and this release lands right on schedule. But the version number alone undersells what changed. The headline feature is a context window that has doubled to 1 million tokens in beta, a jump that moves Claude Sonnet from a capable mid-tier model into territory that was previously reserved for specialized research or enterprise tooling.
For developers building on the API and for everyday Pro users who have ever run into the frustrating limits of a 128K or 200K window, this is a meaningful shift. And it arrives alongside benchmark numbers that are harder to dismiss than most.
What Anthropic Announced
Anthropic's announcement focused on three core areas of improvement: coding, instruction-following, and computer use. These are not new priority areas for the company, but the degree of advancement in Sonnet 4.6 is what distinguishes this release from a routine maintenance update.
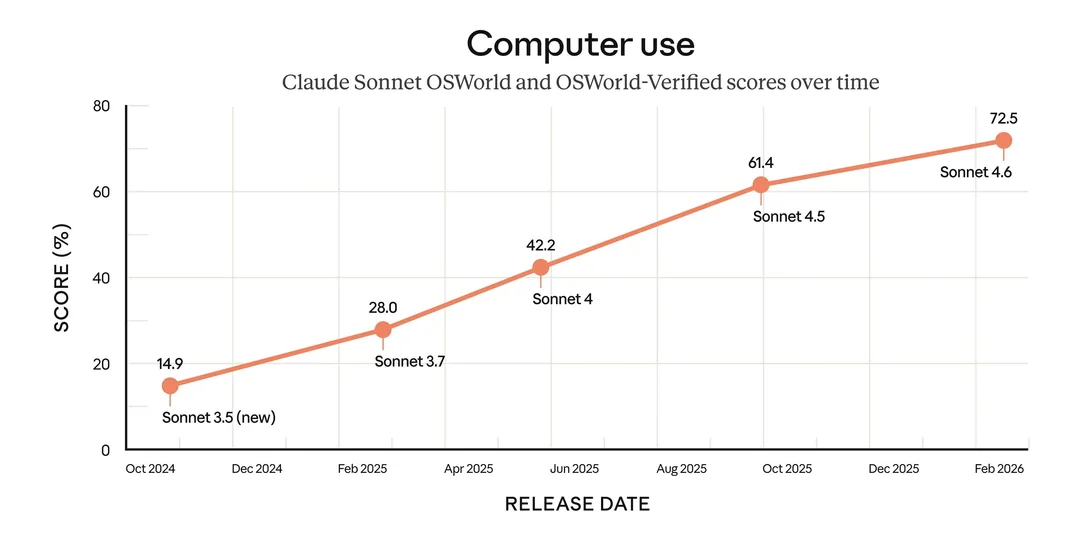
On SWE-Bench, the widely used software engineering benchmark that tests a model's ability to resolve real GitHub issues, Sonnet 4.6 posted a new record. On OSWorld, the benchmark designed to evaluate how well a model can operate a computer autonomously, including navigating interfaces and executing multi-step tasks, the model also turned in a leading score.
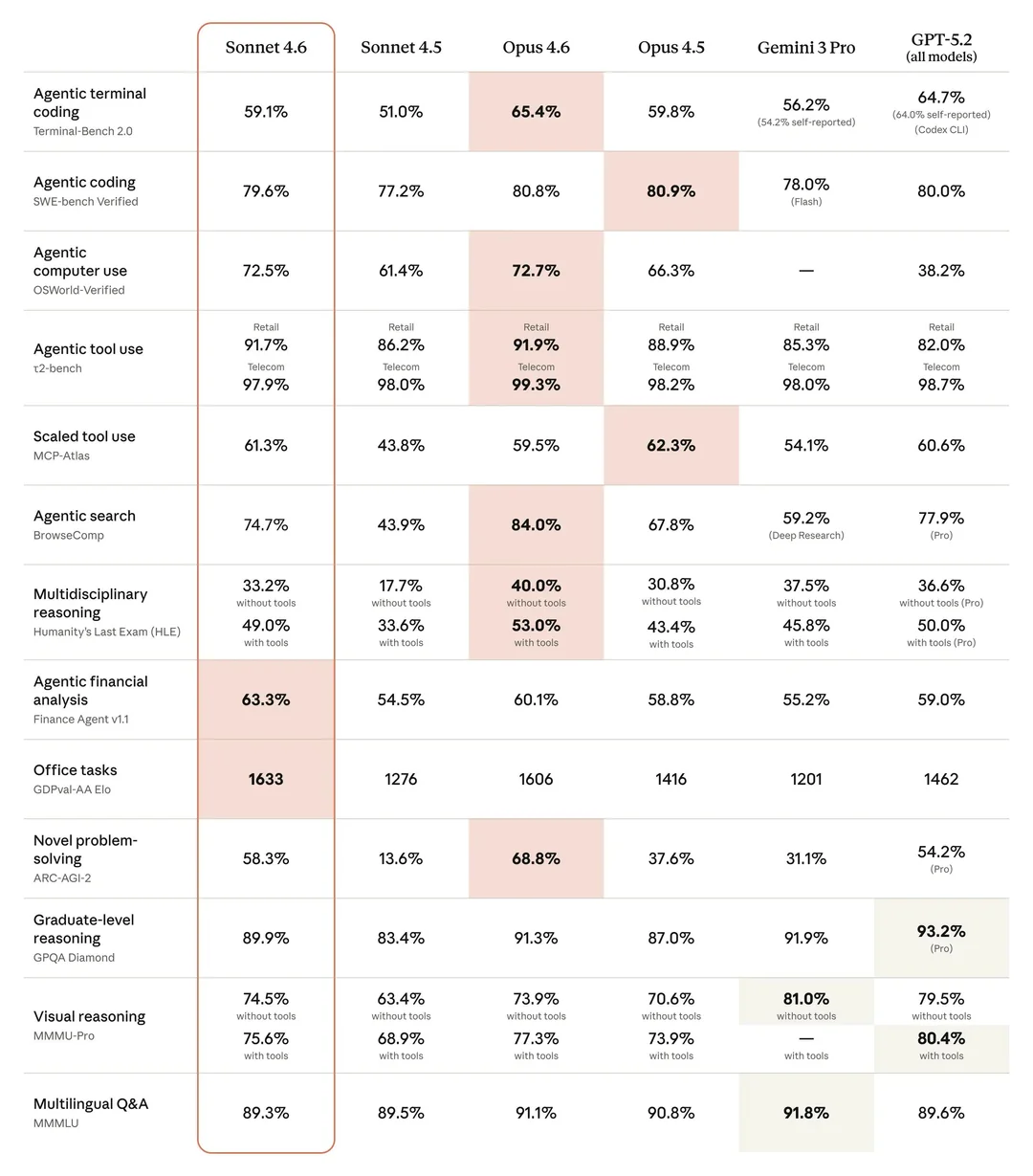
The number generating the most conversation, though, is the 60.4% score on ARC-AGI-2. That benchmark is designed specifically to measure reasoning skills that are thought to be uniquely human, things like novel pattern recognition, abstract inference, and tasks that resist rote memorization or training data saturation. A score above 60% from a mid-tier model puts Sonnet 4.6 ahead of most comparable systems in its class. It still trails Opus 4.6, Gemini 3 Deep Think, and at least one version of GPT 5.2, but the gap is narrower than most would have expected from Anthropic's workhorse model rather than its flagship.
The 1 million token context window is currently in beta. Anthropic described it as sufficient to hold entire codebases, lengthy contracts, or dozens of research papers in a single request. That description is accurate but also undersells the practical implications, which are significant enough to warrant their own discussion.
How the 1 Million Token Context Window Actually Changes Things

Context windows are one of those features that sound technical but have immediate real-world impact. When a model's context window is small, users have to work around it, chunking documents, summarizing earlier parts of a conversation, or running multiple separate queries to get a complete answer. Every workaround adds friction and introduces the possibility that the model is missing relevant information.
At 1 million tokens, Sonnet 4.6 can hold roughly 750,000 words of text in a single session. To put that in perspective, a typical software codebase with several hundred files, or a legal contract with dozens of amendments and exhibits, or the transcript of a full day of congressional hearings, fits comfortably within that window. The model does not need to be reminded of what it read on page one when it is working on page 400.
This matters most for a few specific use cases.
- Software developers can now drop an entire repository into a conversation and ask the model to trace a bug, explain how modules interact, or write tests for previously untested functions, without losing context halfway through.
- Lawyers and compliance professionals can analyze entire contracts without pasting sections manually.
- Researchers can feed multiple papers simultaneously and ask the model to synthesize findings across all of them at once.
The caveat is that 1 million token context is still in beta. Processing that much text takes longer, and the compute costs of running very long contexts are real. It remains to be seen how the feature performs at scale and what pricing structure Anthropic applies to extended context usage through the API.
Why the ARC-AGI-2 Score Is Worth Taking Seriously
Not all benchmarks are created equal, and the AI industry has a long history of models gaming evaluations that were not designed to be gamed. ARC-AGI-2 is different in a few important ways.
The benchmark, developed by researcher Francois Chollet and the ARC Prize team, focuses explicitly on tasks that require fluid reasoning. Unlike benchmarks that test recall or pattern matching against training data, ARC-AGI-2 presents novel visual and logical puzzles that cannot be solved through memorization. A model that scores well on it is demonstrating something closer to on-the-fly problem-solving than database retrieval.
Sonnet 4.6 scoring 60.4% puts it in competitive territory on a benchmark that has historically humbled language models. The models that score higher, including Opus 4.6 and Gemini 3 Deep Think, are significantly more expensive to run and are positioned as flagship or research-grade systems. Hitting this level of performance at a mid-tier price point is where Anthropic appears to be finding its competitive edge with the Sonnet line.
It is worth noting that ARC-AGI-2 scores are not a direct measure of whether a model is generally intelligent or capable of everything a human can do. Chollet himself has cautioned against overinterpreting the scores. But as a proxy for reasoning quality under novel conditions, the benchmark is one of the more rigorous options currently available, and Sonnet 4.6's score on it is legitimately notable.
The Competitive Landscape
Anthropic is not operating in a vacuum. The last several months have been unusually active in the frontier model space, with OpenAI, Google, and Meta all shipping significant updates.
OpenAI's GPT 5.2, depending on the version and configuration, remains above Sonnet 4.6 on ARC-AGI-2. Google's Gemini 3 Deep Think similarly outperforms on that specific benchmark. But both of those systems are positioned toward the premium end of the market. The more relevant comparison for Sonnet 4.6 may be GPT-4o or Gemini Flash, where Anthropic is trying to establish that its mid-tier model is meaningfully stronger on reasoning tasks.
On computer use and coding, the picture is somewhat different. Sonnet 4.6's OSWorld performance is a direct challenge to OpenAI's Operator and Google's Project Mariner, two agentic systems built specifically around the ability to control a computer. Anthropic has been building toward agentic capabilities for several release cycles, and Sonnet 4.6 represents another step in that direction.
For developers choosing between APIs, the combination of coding performance, instruction-following, and the 1 million token context window gives Sonnet 4.6 a plausible claim to being the best mid-tier option currently available for certain workloads. That is not a universal verdict, and individual results will vary by use case, but it is a credible competitive position.
Limitations and Open Questions
The 1 million token context window is described as a beta feature, which means its behavior, availability, and pricing structure are all subject to change. Developers building products that depend on extended context should treat the current state as preliminary.
The ARC-AGI-2 score is impressive relative to comparable models, but the field is moving fast. Scores that represent a leading position today can look less impressive within a quarter if competitors ship aggressively. Anthropic's score also trails the top performers by a meaningful margin, which suggests the reasoning capabilities of the most advanced models are still developing in ways that the mid-tier has not yet fully captured.
On computer use, real-world performance in agentic tasks tends to diverge from benchmark results in ways that are hard to predict in advance. OSWorld is a strong benchmark, but enterprise deployments of computer-use AI involve edge cases, security constraints, and workflow complexity that controlled benchmarks do not replicate. Developers building on Claude's computer use capabilities should expect some iteration.
Finally, the announcement does not include detailed information about pricing changes for the extended context tier. For high-volume API users, that number matters considerably.
What This Means for Developers and Businesses
For developers already building on Claude's API, Sonnet 4.6 is an upgrade worth testing immediately, particularly for coding and long-document workloads. The improvements in instruction-following are relevant for any application where precision matters, including legal tools, compliance software, customer-facing assistants, and data extraction pipelines.
The 1 million token context window opens up application categories that were previously difficult to serve well. Full-codebase agents, contract analysis tools, and research synthesis applications are all more tractable with this kind of capacity. Developers who had been waiting for context limits to expand before investing in certain product directions now have a reason to revisit those plans.
For businesses evaluating AI vendors, the question is less about this specific release and more about trajectory. Anthropic has now shipped meaningful updates to its full model lineup in quick succession. The company's emphasis on safety research has historically been paired with claims that safety and capability are not in tension, and the benchmark results from Sonnet 4.6 are a concrete piece of evidence in favor of that argument.
For Free plan users who have been running on an older default model, Sonnet 4.6 represents a tangible upgrade in quality with no action required on their part.
What Comes Next
Anthropic has signaled that an updated Haiku model is likely coming in the near term. Haiku sits at the bottom of the lineup in terms of price and size, optimized for speed and cost rather than raw capability. An updated version would presumably carry some of the architectural improvements from Sonnet and Opus into that tier, which matters a great deal for high-volume, latency-sensitive applications.

Beyond the model lineup, the continued development of Claude's agentic capabilities is the longer-term story. Computer use, extended context, and improved instruction-following are individually useful features, but together they point toward a model that can handle more of the cognitive work in complex, multi-step workflows. That is where the commercial opportunity is largest, and where the competition is most intense.
Sonnet 4.6 is not a revolutionary release in isolation. But it is another well-executed step in a direction Anthropic has been moving consistently: making a capable, safety-conscious model that can stand up against the best alternatives at its price point.
Frequently Asked Questions
What is Claude Sonnet 4.6 and who is it for? Claude Sonnet 4.6 is Anthropic's latest mid-tier language model, designed for everyday use by individuals and developers. It is now the default model for both Free and Pro plan users on Claude.ai, and it is available through Anthropic's API for developers building applications. It is positioned between the more affordable Haiku model and the more powerful Opus model.
What is the context window size for Claude Sonnet 4.6? Claude Sonnet 4.6 includes a 1 million token context window in beta, which is double the largest context window previously available for the Sonnet line. This is large enough to hold entire codebases, lengthy contracts, or multiple research papers in a single request.
How does Claude Sonnet 4.6 perform on benchmarks? Sonnet 4.6 achieved record scores on OSWorld for computer use and SWE-Bench for software engineering. On ARC-AGI-2, a benchmark measuring reasoning skills specific to human intelligence, it scored 60.4%, putting it above most models in its class. It trails Opus 4.6, Gemini 3 Deep Think, and certain versions of GPT 5.2 on that specific benchmark.
Is Claude Sonnet 4.6 better at coding? Yes, Anthropic cited improvements in coding as one of the primary focus areas for this release. The model posted a new record on SWE-Bench, which tests a model's ability to resolve real-world software engineering problems from GitHub repositories. Developers working on code generation, debugging, and repository analysis should find the new version meaningfully more capable.
What is ARC-AGI-2 and why does Sonnet 4.6's score matter? ARC-AGI-2 is a benchmark designed to test reasoning abilities that are considered uniquely human, including novel pattern recognition and abstract inference. Unlike many benchmarks, it is specifically built to resist memorization. A 60.4% score from a mid-tier model is notable because it suggests meaningful reasoning capability, not just recall of training data.
Will Sonnet 4.6 replace older versions of Claude automatically? For Free and Pro plan users on Claude.ai, Sonnet 4.6 becomes the new default model immediately. Developers using the API can continue specifying older model versions until those are deprecated, but new API integrations will access Sonnet 4.6 when requesting the latest Sonnet.
What comes after Sonnet 4.6 in Anthropic's release roadmap? Anthropic has indicated that an updated Haiku model is likely coming soon. Haiku is the smallest and fastest model in the Claude lineup, optimized for high-volume and latency-sensitive use cases. Beyond that, Anthropic has not provided a specific public roadmap.
How does Claude Sonnet 4.6 compare to GPT-4o and Gemini Flash? Sonnet 4.6 is competitive with GPT-4o and Gemini Flash on most measures, with particular strengths in coding, instruction-following, and computer use. Its 1 million token context window in beta is larger than what is available from comparable-tier models from OpenAI and Google. Benchmark comparisons vary by task, and independent third-party evaluations will provide a clearer picture over time.
Related Articles













