

Brian Chesky, the CEO of Airbnb, did not intend to ignite a geopolitical debate when he mentioned in passing that his company had switched its customer service chatbot to Alibaba's Qwen because it was, in his words, "fast and cheap."
Chamath Palihapitiya was similarly matter-of-fact when he announced he had redirected his company's AI workloads from Amazon's infrastructure to Moonshot's Kimi K2 because it was "way more performant."
These were operational decisions, made the way startups and executives have always made them — by looking at cost, speed, and capability, in roughly that order. But the accumulation of decisions like these across hundreds and then thousands of companies tells a story that goes well beyond any individual product choice.
The numbers are hard to ignore:
- A recent MIT study found Chinese open-source AI models have surpassed US models in total global downloads
- On Hugging Face, Alibaba's Qwen has overtaken Meta's Llama as the most downloaded model series
- By August 2025, Qwen-derived models accounted for more than 40% of all new language model derivatives on the platform
- Llama — the previous default — had fallen to around 15%
Qwen has become, in the language of the developer ecosystem, the default base model for all the remixes.
The question that follows is the one Western policymakers, national security analysts, and technology executives are currently trying to answer: should the fact that a large and rapidly growing share of global AI infrastructure is being built on Chinese foundations be treated as a competitive inconvenience, a structural dependency risk, or something closer to a national security threat?
The honest answer is that it is probably all three, in different proportions and for different stakeholders — and that the Western response so far has been slow, fragmented, and in some cases counterproductive.
How Chinese Models Went From Lagging to Leading
For most of AI's recent history, the question of which open-source models developers would reach for was barely a question at all.
Meta's Llama family was the obvious default. US closed-source models from OpenAI and Anthropic vastly outperformed open alternatives, meaning that any developer who needed serious capability simply paid for API access to GPT-4 or Claude. Even well-resourced in-house open-source efforts had trouble keeping up — Bloomberg built BloombergGPT on open-source models trained on its own financial data, only to see it trail OpenAI's closed models on the very benchmarks it was designed to dominate.
Then DeepSeek happened.

January 2025: The Moment That Changed the Equation
When DeepSeek released its R1 reasoning model in January 2025, the market reaction was immediate and severe:
- The app briefly surpassed ChatGPT as the most downloaded free application in the US App Store
- Nvidia's stock dropped close to 20% in the days that followed
- Roughly $593 billion in market value was wiped from Nvidia's market cap in a single day
What DeepSeek had demonstrated was not merely that a Chinese lab could build a capable model. It was that a Chinese lab operating under US chip export restrictions, using constrained hardware, had built a reasoning model that matched or exceeded leading Western proprietary systems at a fraction of the training cost — and then released it openly, under a permissive MIT license that allowed anyone to download, inspect, modify, and deploy it.
Nathan Lambert, an open-source AI researcher who has tracked this space closely, called DeepSeek R1 "a major reset" — the first time since ChatGPT's emergence that the field had a genuinely frontier-capable model that was open-weight, commercially friendly, and without restrictions on downstream use.
That combination — frontier performance, open weights, permissive licensing, low deployment cost — is what turned a Chinese lab's release into a global infrastructure shift.
The Ecosystem That Followed
DeepSeek's breakthrough was not a one-off. It was the catalyst for a wave.
Alibaba's Qwen, which had already accumulated 600 million downloads before DeepSeek's emergence, accelerated sharply — surpassing 700 million total downloads on Hugging Face by January 2026, making it the world's most widely used open-source AI system. The Qwen team has built what functions as a complete product line of free models covering language, vision, coding, multimodal tasks, and embedding across a range of sizes from lightweight consumer hardware models to large parameter systems competitive with the best proprietary alternatives available.

Beyond Alibaba and DeepSeek, the field has widened considerably. Companies including Z.ai, MiniMax, Tencent, Moonshot AI, and Baidu have all shifted toward open releases. Moonshot's Kimi K2.5 benchmarked close to Anthropic's Claude Opus on several early evaluations — at approximately one-seventh the price.
By November 2025, generative AI from Chinese companies accounted for approximately 15% of global market share — up from around 1% a year earlier. (Nikkei)
Capabilities that once took months to reach the open-source community now emerge within weeks, sometimes days.
Why Developers Keep Reaching for Chinese Models
The competitive pressure that Chinese models exert is not a mystery once you look at the actual economics from a developer's perspective.
The Cost Gap Is Real
Running large language models at production scale through closed-source APIs compounds quickly when a feature runs on every user interaction.
One developer building a productivity app told NBC News that paying for his users' closed-model usage was costing Dayflow up to $1,000 per person — a unit economics problem that makes building a sustainable business extremely difficult. The same developer found that a smaller version of Qwen could perform comparably for his specific use case at a cost that was, effectively, near zero.
"To an average startup, what really matters is the speed and quality of the results, and if you're doing things on scale, how cheap that is. Chinese models that are coming out in the market have consistently performed really well in terms of balancing those three factors."
— Aman Sharma, co-founder of Lamatic
This is not a niche observation from cost-cutting developers. It is being echoed at the executive level by people running companies with real reputations to protect.
Open Weights Enable Things Closed APIs Cannot
For a certain category of application, open-weight models are not just cheaper — they are the only viable option:
- Sensitive data applications where user data cannot legally be sent to a third-party cloud
- Air-gapped environments where API connectivity is not available
- Deep customization use cases that require fine-tuning on proprietary data
- Latency-sensitive products where round-trips to a remote API are prohibitive
As OpenAI, Anthropic, and Google have faced pressure to restrict their most powerful open releases, Chinese developers have filled the resulting gap with models explicitly optimized for local deployment, quantization, and commodity hardware. Research mapping 175,000 exposed AI deployments across 130 countries found Qwen appearing on 52% of systems running multiple AI models — suggesting it has become the default alternative to Llama among developers who run models locally.
Western Labs Are Being Forced to Respond
The pressure has not gone unacknowledged.
In August 2025, OpenAI released its first open-weight models in over five years — a move Sam Altman framed as a strategic recalibration after admitting the company had been "on the wrong side of history" by maintaining a closed approach. The Allen Institute for AI released Olmo 3 in November. Mira Murati's Thinking Machines Lab released tooling to help developers customize open-source models, including eight from Qwen — an endorsement that would have been unusual from someone with her background even a year ago.
None of these moves close the gap. Qwen derivatives remain more than 40% of new Hugging Face language model remixes. Meta's Llama has fallen to around 15%. The direction of momentum is clear.
The Risks: What's Real and What's Exaggerated
The risks attached to Chinese open-source AI are genuinely varied and do not all carry the same weight. This is where most coverage gets imprecise — treating every concern as equally urgent, or dismissing all of them as political theater.
Embedded Censorship: Documented and Real
A report from the Center for AI Standards and Innovation (CAISI) at NIST and the Department of Commerce, released in September 2025, found that Chinese state censorship appears structurally embedded in DeepSeek models — not applied as an external filter, but built into the weights themselves.
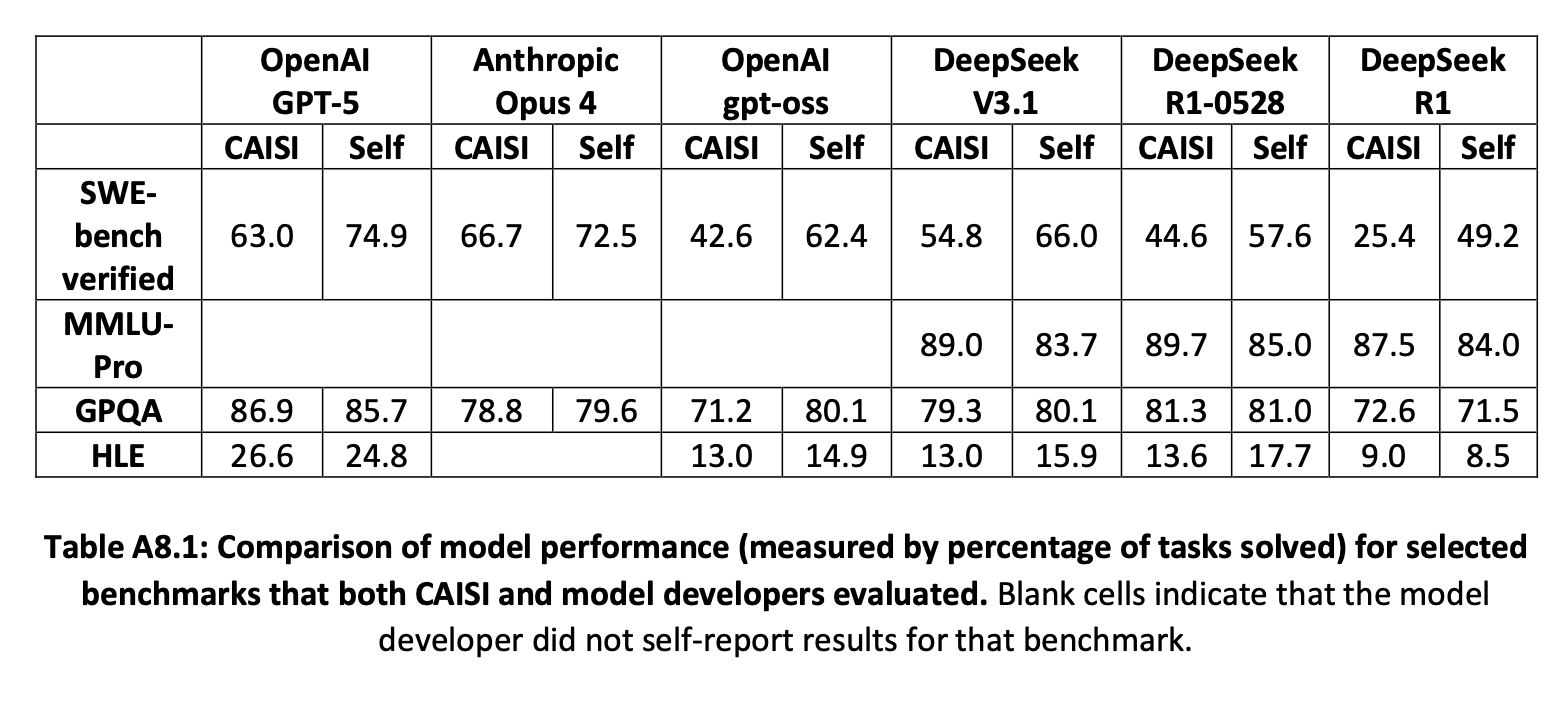
Key findings from the CAISI report:
- DeepSeek models echoed CCP narratives 4x more often than US reference models on politically sensitive topics
- The most aligned model, DeepSeek R1-0528, aligned with state narratives 25.7% of the time when prompted in Chinese
- Because the weights run locally, these patterns persist regardless of where the model is deployed
The practical impact, however, depends entirely on the use case. A developer building a code completion tool or retail chatbot is unlikely to ever encounter these effects. An organization building research tools or news analysis products that routinely process politically sensitive content faces a more substantive problem.
Bottom line: Censorship risk is real, but highly context-dependent.
Security Vulnerabilities: Present but Uneven
Independent researchers have found Chinese models vulnerable to jailbreaking techniques that Western models had patched considerably earlier:
- Kela Cyber demonstrated in early 2025 that DeepSeek R1 remained vulnerable to the "Evil Jailbreak" technique — a method OpenAI had addressed years prior — enabling the generation of infostealer malware and ransomware instructions
- Palo Alto Networks' Unit 42 found R1 vulnerable to three additional distinct jailbreaking techniques: Crescendo, Deceptive Delight, and Bad Likert Judge
These are genuine concerns for deployments with safety implications. They are less immediately relevant for the majority of developer use cases — text generation, data extraction, code completion — that do not depend on safety guardrails.
Bottom line: Security vulnerabilities are patchy and uneven, not uniform dealbreakers.
Supply Chain Dependency: The Most Serious Long-Term Risk
The concern that national security experts find hardest to dismiss is not about any single model's censorship patterns or jailbreak vulnerabilities. It is about dependency.
Unlike proprietary models accessed through APIs, open-weight models are downloaded and embedded in production systems — a dependency that is difficult to reverse quickly. The risk scenario is straightforward: if Chinese companies were to restrict access, change licensing terms, introduce unexpected behavior through updates, or if geopolitical conditions made continued use legally untenable, businesses and researchers relying on this infrastructure could find themselves cut off from critical systems with limited options.
The dependency is also compounding. Qwen-derived models represent more than 40% of new open-source derivatives on Hugging Face, which means that even models that do not originate in China are increasingly built on Chinese foundations. Removing that foundation from the ecosystem at some future point would not be a clean operation.
"Open models are a fundamental piece of AI research, diffusion, and innovation, and the US should play an active role leading rather than following other contributors."
— Nathan Lambert, ATOM project
Bottom line: Supply chain dependency is the risk that compounds quietly over time and is hardest to reverse.
The "Adversary AI" Label: Useful but Imprecise
The CAISI report labeled Chinese models "adversary AI" — a characterization that national security researchers have pushed back on as analytically imprecise.
Models like Qwen are built by Alibaba, a commercial technology company, not a state intelligence agency. The relationship between Chinese tech companies and the Chinese state is genuinely different from the equivalent relationship between Amazon or Google and the US government — but framing every Chinese open-source release as a state-directed operation conflates different levels and types of influence.
What is demonstrably true is that Beijing has treated AI as an instrument of national power since 2017, and its regulatory frameworks explicitly link commercial AI development to state priorities. What is also true is that most developers currently building on Qwen or DeepSeek are making a practical engineering choice, not a political one.
Bottom line: The adversary framing captures a real dynamic but overstates it in ways that make good policy harder to design.
What the West Has Done — and What Is Missing
The policy and competitive response from the West has been inconsistent at best.
Regulatory Actions So Far
| Country / Region | Action | Date |
|---|---|---|
| Italy | Blocked DeepSeek app over data privacy | January 2025 |
| Taiwan | Banned government departments from using DeepSeek | February 2025 |
| Germany | Asked Apple and Google to remove DeepSeek | June 2025 |
| US (Trump administration) | Weighed penalties, debated access restrictions | Ongoing 2025 |
| EU (multiple DPAs) | Investigations into data transfers to China | 2025 |
None of this has meaningfully slowed adoption. Developers and enterprises are still choosing Chinese models because they perform well and cost less — and the regulatory response has been reactive and fragmented rather than grounded in a coherent framework for managing AI supply chain risk.
Where the Performance Gap Actually Sits
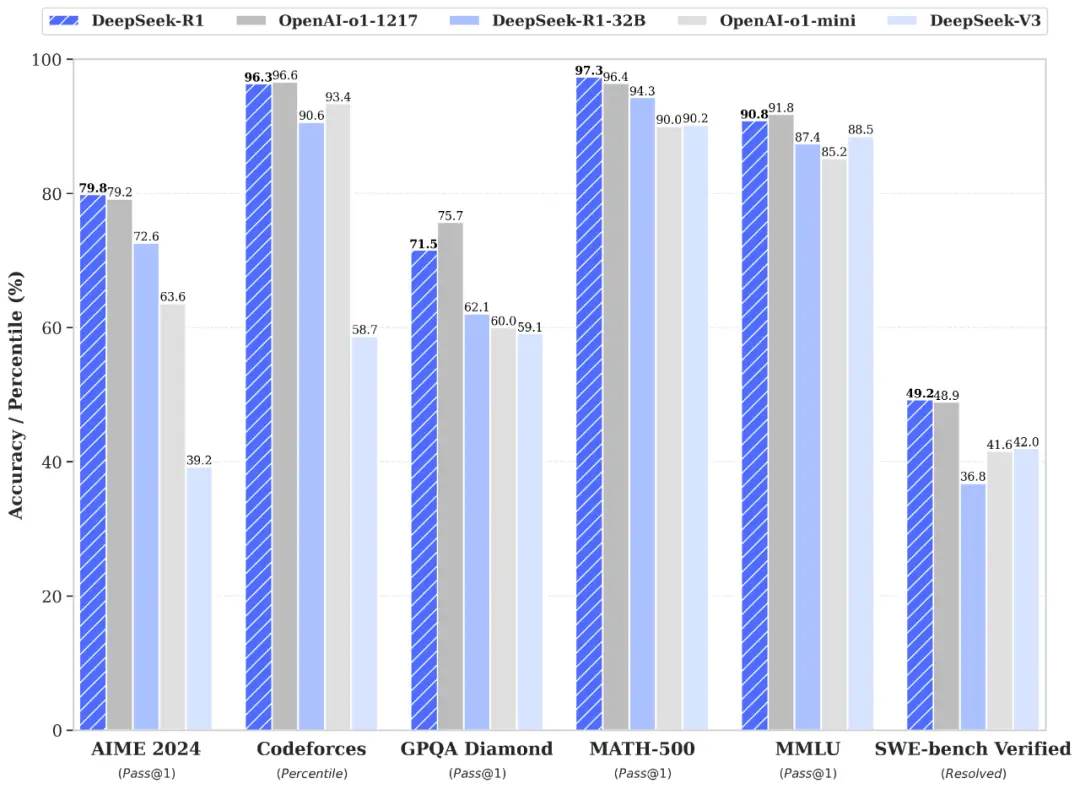
Estimates from Epoch AI suggest Chinese models trail leading US releases by approximately seven months on average. That gap briefly narrowed during DeepSeek's R1 launch, then widened again as US firms pushed ahead at the frontier through massive infrastructure investment.
The lead at the absolute frontier still belongs to US models. But the frontier is not where most applications are built. Most commercial AI products are built at a performance level that Chinese open-source models already match — and because those models are free to use and optimized for local deployment, the cost advantage they carry at that tier is substantial and durable.
The Actual Strategic Problem
The core vulnerability for the West is not that Chinese labs are closing in on closed proprietary models. It is that the West has effectively ceded the open-source tier of the AI ecosystem by default.
As OpenAI, Anthropic, and Google retreated from open releases — for safety, commercial, and regulatory reasons — Chinese developers filled the vacuum with models explicitly built for the use cases that open weights enable.
"In the Chinese programmer community, open source has become politically correct — a response to US dominance in proprietary AI."
— Liu Zhiyuan, Professor of Computer Science, Tsinghua University
By releasing strong research, Chinese labs build reputation, gain developer mindshare, and accumulate a global base that increasingly treats their models as the default starting point for new AI applications. That compounding dynamic is harder to reverse through ban orders than through building credible Western alternatives.
Who Should Be Worried — and Who Should Probably Relax
The honest answer to the article's question depends heavily on who is asking.
Organizations That Should Be Cautious
High-risk categories where the concerns are concrete, not theoretical:
- Government agencies — any department handling classified or sensitive national security data
- Defense contractors — organizations with DoD relationships or security clearances
- Healthcare organizations — entities subject to HIPAA or similar sensitive data regulations
- Financial institutions — firms with strict data governance and audit requirements
- Research and media organizations — any platform regularly processing politically sensitive content where CCP narrative alignment could materially affect outputs
For these organizations, the prudent approach is to audit current and planned use of Chinese-origin models, apply the same due diligence to model selection as to any critical infrastructure supplier, and maintain clear options to substitute quickly if conditions change.
"The biggest factor where this matters is for government and high-stakes enterprise applications where security is paramount. There are natural concerns over what data the model was pre-trained and post-trained on and whether it exhibits behaviors the company wouldn't want."
— Nathan Benaich, founder, Air Street Capital
Developers and Startups Who Are Probably Fine
A startup building a writing assistant, code completion tool, document summarizer, or customer service bot on top of Qwen or a Qwen-derived model is taking a dependency risk and a potential censorship risk that is, in most real-world deployments, manageable.
The censorship patterns documented by CAISI matter most when a model is regularly asked about politically sensitive topics — a scenario that describes a fraction of commercial AI applications.
The more acute risk for this category is supply chain dependency: building critical product infrastructure on a model family that could, under certain geopolitical conditions, become difficult or legally complicated to use. Maintaining the ability to substitute to a Western equivalent is a form of business resilience planning, not paranoia.
Policymakers and National Security Agencies
For this audience, the concern is less about any specific application and more about the ecosystem-level dynamic. A global developer community that increasingly treats Chinese model families as the default foundation for AI development is, through accumulating technical choices, building dependencies that are hard to reverse.
The policy response that would actually address this:
- Investing substantially in competitive Western open-source alternatives
- Creating programs like ATOM at scale with meaningful government support
- Funding projects like Reflection AI (a startup specifically founded to build a capable Western open-source alternative, recently valued at $8 billion)
These are more effective long-term responses than reactive actions targeting specific models or companies after they have already been embedded into global developer workflows.
What Happens Next
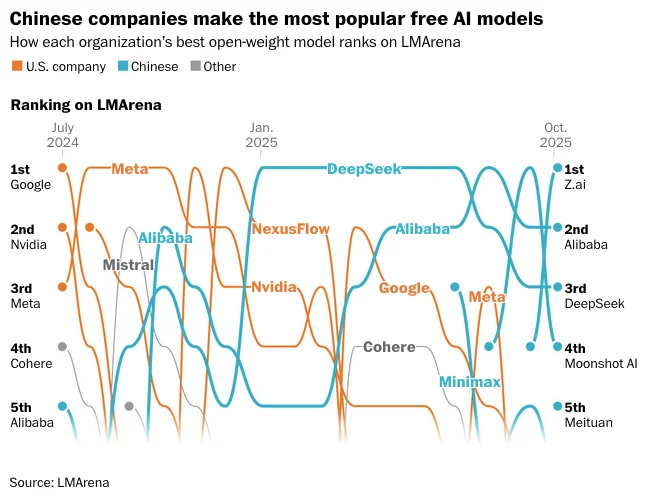
MIT Technology Review's 2026 forecast was blunt: expect more Silicon Valley apps to quietly ship on top of Chinese open models, and expect the lag between Chinese releases and the Western frontier to keep shrinking — from months to weeks, and sometimes less.
The momentum of Chinese open-source AI is not a temporary disruption that will resolve itself. It is the consequence of a deliberate strategic choice — to build a global developer base through open, permissive releases at competitive performance levels and low cost — that has worked exactly as intended.
The West's competitive options are not exhausted:
- Meta's Llama 4 represents a serious investment in open-source agentic capability
- OpenAI's pivot toward open weights signals that the closed-only strategy is under revision
- ATOM, Olmo, and Reflection AI represent the emerging infrastructure of a credible Western open-source response
But responses have to match the scale of the challenge. Chinese models are now the foundation for most of the world's open-source AI ecosystem, and that position is not going to change through press releases, ban orders, or the strategic deployment of the phrase "adversary AI."
Whether this ultimately represents a threat to Western technological leadership, an economic advantage for global developers, or something more complicated than either framing captures is a question that 2026 and the years that follow will answer with considerably more clarity than the current debate provides.
Frequently Asked Questions
Why are so many AI startups building on Chinese open-source models?
The primary reasons are cost and performance. Chinese open-source models like DeepSeek R1 and Alibaba's Qwen deliver near-frontier AI capabilities at dramatically lower cost than Western proprietary alternatives like GPT-5 or Claude. They are freely downloadable, can be run locally without sending data to the cloud, and carry permissive licenses that allow fine-tuning and commercial use. For startups with tight margins and large user bases, the economics are difficult to ignore.
What are the main security risks of using Chinese open-source AI models?
The documented risks include structural censorship patterns aligned with Chinese state narratives, security vulnerabilities that have been slower to patch than those in leading Western models, and data privacy concerns when using Chinese companies' hosted APIs. A NIST-affiliated report found DeepSeek models echoed CCP narratives four times more often than US reference models. Security researchers found vulnerabilities in DeepSeek R1 that Western models had addressed years earlier. These risks vary significantly by use case and deployment context.
Do Chinese models like DeepSeek and Qwen spy on users?
The answer depends on how the models are deployed. When using Chinese companies' hosted APIs or consumer chatbot apps, data is typically processed and stored on servers in China, which raises legitimate data sovereignty concerns. When open-weight models are downloaded and run locally on your own hardware, data does not leave your infrastructure — though the model weights themselves may contain behavioral patterns reflecting their training.
What is the difference between open-source and open-weight AI models?
Open-weight means the model's parameters — the numerical values that encode its learned capabilities — are publicly released and can be downloaded, modified, and deployed by anyone. Full open-source additionally implies releasing training data, code, and documentation. Most Chinese models are open-weight rather than fully open-source, but the open-weight property is what makes them practically free to use and customize. This is the key distinction from closed proprietary models like GPT-5, which are accessible only through paid APIs.
Is there a Western alternative to DeepSeek and Qwen for open-source AI?
Meta's Llama series remains the most prominent Western open-weight alternative, though it has lost significant market share to Chinese models. OpenAI released its first open-weight models in August 2025 after years of maintaining a closed approach. Projects like the Allen Institute for AI's Olmo series and the ATOM initiative by Nathan Lambert are specifically focused on building competitive Western open-source alternatives. Reflection AI, a startup founded explicitly to address this gap, was recently valued at $8 billion.
Should enterprises ban Chinese AI models entirely?
A blanket ban is both impractical and analytically imprecise. Government agencies, defense contractors, and organizations handling sensitive regulated data should treat Chinese models with the same due diligence they apply to any high-risk infrastructure supplier — which may well lead to avoidance. Commercial enterprises building general-purpose AI features face lower risk and may find the cost advantages significant, provided they maintain the ability to substitute to Western alternatives if conditions change.
How did China's AI labs achieve competitive models despite US chip export controls?
This remains partly contested. Chinese labs have developed and published novel efficiency techniques — including new training algorithms and mixture-of-experts optimization — that extract more capability per unit of compute than previous approaches. DeepSeek in particular demonstrated that frontier-level performance is achievable on constrained hardware. Some US researchers and companies have alleged that Chinese labs also distilled knowledge from leading Western models, raising intellectual property questions.
What is the ATOM project and why does it matter?
ATOM, which stands for American Truly Open Models, is a project by ML researcher Nathan Lambert that tracks open-weight model development and advocates for sustained US investment in competitive open-source alternatives to Chinese models. Lambert and others argue that open models are a fundamental piece of AI research and innovation, and that the US ceding the open-source tier of the AI ecosystem to Chinese labs by default represents a long-term strategic vulnerability that cannot be addressed through export controls or model bans alone.
Related Articles













