

Nobody scheduled this. There was no press summit, no coordinated release calendar, no polite arrangement between labs. Yet February 2026 has somehow become the most consequential single month in AI model competition since GPT-4 first arrived and made the industry recalibrate everything it thought it knew about language models.
Anthropic opened the month on February 5 with Claude Opus 4.6, a significant upgrade to its flagship model featuring new agent teams, PowerPoint integration, and a 1M token context window. OpenAI, already operating well into the GPT-5 family by this point, released GPT-5.3-Codex on the same day. DeepSeek, the Chinese lab that rattled global equity markets a little over a year ago when V3 dropped, is expected to release V4 at any moment, with phased rollout testing already underway and a context window upgrade from 128K to over 1 million tokens quietly confirmed earlier this month.
For builders, business leaders, and anyone who relies on these tools professionally, the pace is both exciting and genuinely difficult to track. The question isn't whether AI is getting better – it clearly is, fast. The question is which system is getting better in the ways that actually matter for your specific work, and whether the gap between these models is wide enough to justify switching, staying, or splitting usage across multiple providers.
This piece breaks all of that down.
What Just Happened
The February cluster of releases looks coincidental but probably isn't. Anthropic, OpenAI, and DeepSeek are all responding to the same underlying dynamics: the emergence of real-world agentic deployment, the shift from "smart chatbot" to "autonomous work engine," and the growing realization that benchmark leaderboards don't capture what enterprise customers actually need.
Anthropic launched Claude Opus 4.6 on February 5. The headline capability is agent teams: rather than routing every step of a complex task through a single agent working sequentially, Opus 4.6 can now split tasks across multiple agents that coordinate in parallel. For a financial analyst running a multi-source research job, or a developer spinning up a new service across several microservices simultaneously, that distinction isn't cosmetic. It can mean the difference between a task taking two hours and one taking twenty minutes.
Twelve days later, on February 17, Anthropic dropped Claude Sonnet 4.6, making it the default model for free and Pro users. The key point: Sonnet 4.6 is bringing Opus-class performance to a mid-tier price point. Early access developers reportedly prefer it to the Opus 4.5 from November 2025, which says something about how rapidly the capability curve is compressing across model tiers.
OpenAI, meanwhile, has been operating at a relentless pace since GPT-5 launched in August 2025. The company released GPT-5.3-Codex on February 5 as well, the most capable agentic coding model in its lineup, now capable of moving beyond writing code toward using code as a tool to operate a computer and complete work end to end. OpenAI describes the model as helping accelerate its own development process, a recursive capability milestone that is easy to bury in a press release and easy to underestimate in practice.
DeepSeek has not yet formally released V4 as of this writing. But the pre-launch signals are unusually concrete. The company quietly expanded its context window from 128K to over 1 million tokens, upgraded its knowledge cutoff to May 2025, and its app prompted users to update to version 1.7.4. Analysts at Nomura Securities believe V4's release is imminent, noting the company appears to be following the same quiet-before-launch pattern that preceded V3. The timing, intentionally or not, once again coincides with the Lunar New Year – the same playbook DeepSeek used when R1 launched in January 2025 and caused Nvidia's stock to drop 17 percent in a single session.
How the Technology Actually Works
To understand why these releases matter beyond headline benchmarks, it helps to understand what each lab has actually built differently.
Claude Opus 4.6
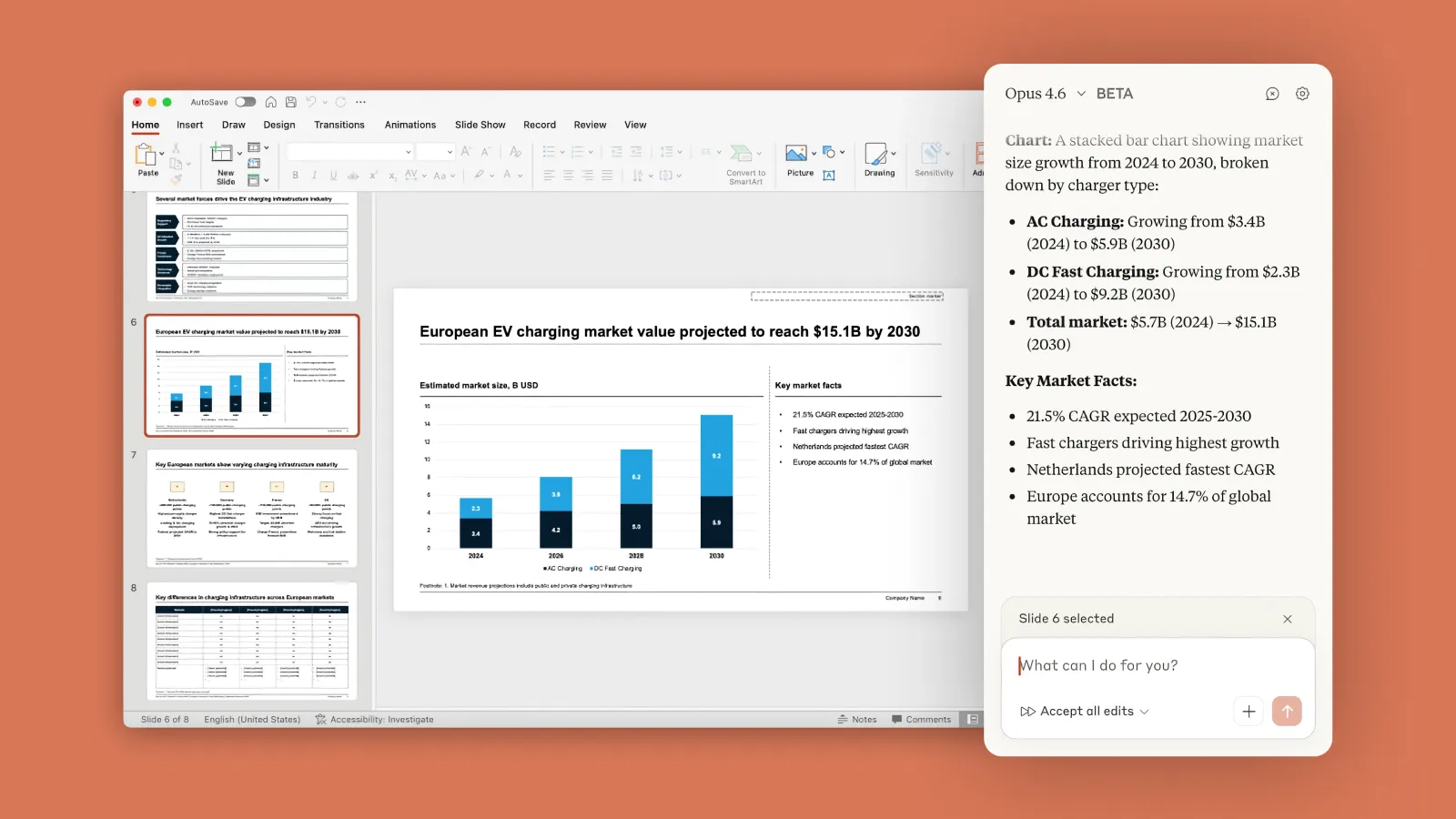
Anthropic's agent teams architecture is the most structurally novel addition in this cycle. Previous Claude models could execute long-horizon tasks, but the agent handled work sequentially. Opus 4.6 enables parallel sub-agents that split responsibilities, each owning its piece of a task while coordinating with others. Anthropic compares the experience to directing a team of talented humans, not prompting a single assistant.
The model also introduces adaptive thinking, where it reads contextual signals to decide how much extended reasoning a given task actually warrants. On the simpler end, it moves quickly. On harder problems, it deliberately slows down and revisits its reasoning before committing to an answer. Developers can also tune this manually with an effort parameter, choosing between high, medium, or low to trade off intelligence, latency, and cost.
On GDPval-AA, an evaluation of economically valuable knowledge work across finance, legal, and other domains, Opus 4.6 reportedly outperforms GPT-5.2 by around 144 Elo points. It also leads all frontier models on Humanity's Last Exam, a multidisciplinary reasoning test designed to be genuinely hard.
Sonnet 4.6 brings much of this to a more accessible tier. It now supports a 1M token context window in beta, matching Opus, and shows meaningful improvements in computer use, which Anthropic says is reaching human-level capability for tasks like navigating complex spreadsheets or filling out multi-step web forms. The model also shows significantly improved resistance to prompt injection attacks, a meaningful safety advancement for enterprise deployment.
GPT-5.3-Codex
OpenAI's February release takes a different angle. GPT-5.3-Codex is not a generalist model – it is a specialist system built for agentic coding and expanding into what OpenAI calls "a general collaborator on the computer." The model combines the coding architecture from GPT-5.2-Codex with the reasoning and professional knowledge from GPT-5.2 into a single unified system that is also 25 percent faster than its predecessor.
What makes GPT-5.3-Codex genuinely notable is a detail OpenAI tucked into the announcement: the model was instrumental in creating itself. The Codex team used early versions to debug its own training, manage its own deployment, and diagnose test results. That's not a marketing line. It reflects a real shift in how AI development pipelines now work, and it signals a compounding capability dynamic that labs operating without this recursive loop will find increasingly difficult to match.
The broader GPT-5 family includes a real-time router that automatically switches between a fast mode and a reasoning mode depending on task complexity. The router has been controversial – a bug on launch day caused the router to malfunction, making GPT-5 appear significantly less capable than it was – but when operating correctly, the system allows users to get fast responses for simple queries without sacrificing depth on harder problems.
OpenAI has also been refining GPT-5's personality. The model is intentionally less sycophantic than GPT-4o, with targeted evaluations showing sycophantic responses dropped from 14.5 percent to under 6 percent. For professional users who found earlier ChatGPT versions frustratingly agreeable, this is a meaningful behavioral change.
DeepSeek V4

DeepSeek's approach is structurally different from both American competitors. Where OpenAI and Anthropic are scaling compute aggressively and building deep ecosystem integrations, DeepSeek has consistently prioritized doing more with less. The V3 generation achieved competitive performance with a fraction of the training cost that comparable American models required, which is the source of its geopolitical resonance: it suggested that hardware export restrictions might not be as effective a constraint as Western policymakers assumed.
V4 is expected to extend this philosophy. The architecture introduces mHC (Manifold Constrained Hyper-Connectivity), which is designed to optimize information flow between neural network layers while preventing instability in very deep models. DeepSeek Sparse Attention, already present in V3, uses a dynamic mechanism to identify only the most relevant context blocks for each query, allowing the model to handle very long contexts without compute scaling exponentially.
The 1M token context expansion confirmed ahead of V4's release suggests the model will match what Anthropic and Google have already shipped in their flagship tiers. Given DeepSeek's track record of achieving this at dramatically lower inference cost, that is a meaningful competitive development.
Why It Matters Right Now
The convergence happening in February 2026 is not just about benchmark improvements. It reflects a structural transition in what AI models are for.
The first wave of the current AI era was about intelligent completion: you gave a model a prompt, it gave you an output. The second wave introduced reasoning: models that could work through problems step by step, catching their own errors, engaging with harder logic. The wave breaking right now is agentic: models that can sustain multi-step work autonomously across real software environments, real browser sessions, and real file systems without constant human intervention.
Every major lab has now built for this. Claude has agent teams and Claude Code. OpenAI has Codex and a computer-use architecture that is evolving rapidly. DeepSeek has emphasized agent training data synthesis across over 1,800 environments in V3.2. The race is no longer about which model can write the best essay. It is about which model can actually get work done without a human watching every step.
For enterprise customers, this raises real procurement questions. Claude's ecosystem integration with Excel and PowerPoint, and its agent teams capability, is clearly targeting white-collar knowledge workers. OpenAI's Codex ecosystem targets software development teams. DeepSeek remains the most attractive option for organizations that need high-capability reasoning at low inference cost and are either comfortable running open-source deployments or have privacy constraints that make American providers complicated.
The Competitive Landscape
These three labs do not operate in isolation. Google's Gemini family is also in the mix, and Mistral, Cohere, and a range of other providers are serving specific enterprise niches. But the clearest three-way tension in February 2026 is between OpenAI, Anthropic, and DeepSeek, because each represents a genuinely different philosophy about where value gets created.
OpenAI is building an AI platform company. GPT-5 and its variants are designed to be the intelligence layer across a massive installed base – ChatGPT's consumer footprint, Microsoft Copilot, the API ecosystem, Codex for developers. The company is betting that distribution and ecosystem depth will prove as durable as model quality.
Anthropic is building for trust and enterprise reliability. Claude's safety evaluations are the most detailed in the industry, its character is intentionally more consistent and less prone to the kind of behavioral drift that makes enterprise deployment risky, and the company's focus on agentic work for knowledge professionals is increasingly well-defined. The Dario Amodei phrase "vibe working" – the equivalent of vibe coding but for general office tasks – is not just a soundbite. It is a market thesis: AI that can run financial analyses, build presentations, and coordinate research without hand-holding.
DeepSeek is a wildcard that is also, increasingly, a permanent feature. Its open-weight models can be self-hosted, which appeals to regulated industries, security-sensitive organizations, and any company that does not want its data flowing through American cloud infrastructure. The fact that its models have consistently matched or approached the performance of closed Western models at dramatically lower cost has forced the entire industry to recalibrate its assumptions about what training efficiency actually means.
What This Means for Users and Businesses
If you are a developer or team lead trying to make a decision right now, here is the honest practical breakdown.
For general knowledge work and office task automation, Claude Opus 4.6 or Sonnet 4.6 is the most coherent end-to-end choice in February 2026. The agent teams feature, the Excel and PowerPoint integrations, and the model's documented strength on real-world knowledge work benchmarks all point in the same direction. The 1M token context window in beta also means long-document workflows are now viable without workarounds.
For software development specifically, GPT-5.3-Codex is the benchmark leader. Its SWE-Bench Pro performance, the recursive self-improvement loop built into the Codex development process, and OpenAI's deep GitHub and VS Code integrations make it the strongest choice for pure coding workflows. Claude Code paired with Opus 4.6 is genuinely competitive -- Anthropic claims Opus 4.6 leads on Terminal-Bench 2.0, and Claude Code's adoption has been remarkable across the industry -- but for teams already embedded in the GitHub ecosystem, Codex has a structural advantage.
For organizations that need reasoning power at low cost, or that have data sovereignty concerns making American cloud providers complicated, DeepSeek V3.2 is the current answer while V4 enters its final pre-release phase. Self-hosting remains viable, and the open-weight availability is a genuine differentiator in regulated industries.
For most individual users, the gap between these models in day-to-day tasks is smaller than the headlines suggest. The real differentiation shows up at the edges: on the most complex multi-step tasks, on the longest documents, and on agentic workflows that run for minutes or hours without human input. If your AI usage is primarily writing assistance, summarization, or simple Q&A, you will not feel the frontier in any of these releases the way a developer running autonomous coding sessions overnight will.
Future Outlook
The pace of release cycles is not slowing down. Anthropic went from Opus 4.5 in November 2025 to Opus 4.6 in February 2026 and Sonnet 4.6 twelve days after that. OpenAI went from GPT-5 in August 2025 to GPT-5.2-Codex to GPT-5.3-Codex in weeks. DeepSeek, if V4 delivers on expectations, will have iterated from V3 to V4 in roughly fourteen months.
The implication is that any competitive advantage any single lab holds right now is probably temporary – measured in months, not years. What matters more for long-term market positioning is ecosystem lock-in (Claude in Excel, Claude Code, Codex in GitHub), cost structure at scale (where DeepSeek maintains a meaningful advantage), and safety and trust reputation (where Anthropic has the strongest documented track record).
The agentic shift is the defining trend. All three labs are converging on the same conclusion: the most economically valuable capability is not smarter text generation, it is sustained autonomous work. The question being answered in real time is which system can act like a reliable colleague on hard, ambiguous tasks – not which one produces the cleanest paragraph.
February 2026 is not the end of this competition. It might not even be the middle. But it is the moment when the model war stopped being theoretical and started being about who can actually do your job.
Frequently Asked Questions
What is the best AI model available in February 2026?
That depends heavily on your use case. For knowledge work and enterprise office tasks, Claude Opus 4.6 leads on key real-world benchmarks and offers the most coherent end-to-end workflow suite, including Excel and PowerPoint integrations. For software development, GPT-5.3-Codex is the benchmark leader in agentic coding. For organizations prioritizing cost efficiency or data sovereignty, DeepSeek V3.2 -- and soon V4 -- remains the strongest open-weight option.
How does Claude Opus 4.6 differ from previous Claude models?
Claude Opus 4.6 introduces agent teams, which allow multiple AI agents to work in parallel on complex tasks rather than executing steps sequentially. It also adds adaptive thinking, improved code review and debugging skills, a 1M token context window in beta, and direct PowerPoint integration. It outperforms its predecessor Claude Opus 4.5 by 190 Elo points on the GDPval-AA knowledge work benchmark.
Is GPT-5.3-Codex a separate model from GPT-5?
Yes. GPT-5.3-Codex is a specialized variant of the GPT-5 family, optimized specifically for agentic coding. It combines the coding architecture from GPT-5.2-Codex with the general reasoning capabilities of GPT-5.2, and runs approximately 25 percent faster than its predecessor. It is available through Codex surfaces for paid ChatGPT users.
When is DeepSeek V4 releasing?
As of late February 2026, DeepSeek V4 has not formally launched but phased rollout testing is underway. The company upgraded its context window to over 1 million tokens, updated its knowledge cutoff to May 2025, and pushed a pre-release app update. Analysts at Nomura Securities expect the formal release is imminent, following the same pre-launch pattern seen with V3.
Why did DeepSeek V3 cause a stock market drop and will V4 do the same?
When DeepSeek V3 released in late 2024, it demonstrated competitive performance with major American models at a fraction of the training cost, which raised questions about the necessity of high-end AI chips and US hardware export strategy. Nvidia's stock fell 17 percent. Nomura Securities has noted that V4's release may not recreate the same panic because the market now prices in DeepSeek's efficiency, the competitive landscape is more complex, and V4 appears to be an architectural maturity step rather than a disruptive shock.
Can Claude Sonnet 4.6 replace Claude Opus for most tasks?
Anthropic says yes, for many use cases. Early access developers report preferring Sonnet 4.6 to Opus 4.5 -- the previous flagship from November 2025 -- on a range of tasks. Sonnet 4.6 is now the default model for free and Pro users, priced the same as Sonnet 4.5, and features a 1M token context window in beta. It does not include agent teams, which remain an Opus 4.6 capability.
How do these models handle long-running agentic tasks?
All three systems now offer extended context windows of 1 million tokens or more and improved ability to sustain autonomous workflows. Claude Opus 4.6's agent teams allow parallel execution across multiple sub-agents. GPT-5.3-Codex uses context compaction to work coherently across multiple context windows on long-running tasks. DeepSeek's Sparse Attention mechanism is designed to handle very long contexts without compute scaling prohibitively. That said, complex multi-step orchestration remains an active area of improvement across all labs.
Is it worth switching AI providers right now?
For most individual and small team users, switching costs likely exceed the marginal benefit of any single model's advantages over another. The models are close enough on everyday tasks that workflow, integration, and pricing tend to matter more than raw capability. For enterprise teams running serious agentic workloads – autonomous coding, long-document analysis, complex financial research – the architectural differences between Claude's agent teams, OpenAI's Codex ecosystem, and DeepSeek's open-weight efficiency are worth evaluating carefully against specific use cases.
Related Articles













