

Information retrieval faces a persistent challenge: semantic search excels at understanding meaning but struggles with specifics it hasn't seen before. Product codes, newly launched items, internal terminology—these out-of-domain elements often fall outside embedding models' training scope, creating gaps in search accuracy.
Hybrid search solves this by merging semantic understanding with traditional keyword matching. The result: comprehensive retrieval that captures both conceptual relevance and literal precision.
This guide explores hybrid search mechanics, benefits, and practical implementation using modern vector search platforms.
Why Keyword Search Alone Falls Short
Traditional keyword search operates on exact term matching between queries and documents. While reliable for literal matches, this approach misses language nuances—synonyms, related concepts, contextual variations.
Search for "movie" and you won't find documents containing only "film" or "cinema," even though these terms carry identical meaning. The system sees different strings, not equivalent concepts.
This limitation becomes particularly problematic in domains with rich vocabulary variation. Medical terminology, technical documentation, customer service—all contain multiple ways of expressing the same ideas. Keyword search treats each variant as distinct, fragmenting results and frustrating users.
Semantic Search: Powerful but Incomplete
Semantic search addresses keyword limitations through embeddings—vector representations capturing text meaning in high-dimensional space. These vectors enable similarity matching based on conceptual relationships rather than literal text overlap.
Now that "movie" query returns "film" and "cinema" results because the embedding model understands their semantic relationship. The system recognizes meaning, not just characters.
However, semantic search introduces its own constraints. Embedding models learn from training data, and their understanding reflects that data's scope. Out-of-domain information—specific product identifiers, newly introduced terminology, proprietary codes—often doesn't appear in training corpora.

When users search for "SKU-8472-B" or a product launched last week, semantic embeddings provide limited help. The model hasn't encountered these terms and cannot meaningfully represent them in vector space.
This gap matters considerably in enterprise contexts where precision matters. Missing a specific product code or internal identifier can render search functionality inadequate for business operations.
How Hybrid Search Bridges Both Worlds
Hybrid search combines dense semantic embeddings with sparse keyword representations, capturing advantages of both approaches.
Understanding Dense Embeddings
Dense embeddings, generated by models like modern text embedding APIs, encode semantic meaning as vectors with mostly non-zero values across hundreds or thousands of dimensions. These representations enable similarity searches based on conceptual relationships.
Two texts discussing similar topics produce embeddings that cluster together in vector space, even when using completely different vocabulary. This property powers semantic search's ability to surface relevant content regardless of exact wording.
Understanding Sparse Embeddings
Sparse embeddings represent text through high-dimensional vectors where most values are zero. They're generated by tokenizing text into words or sub-words, then applying algorithms like TF-IDF (Term Frequency-Inverse Document Frequency), BM25, or SPLADE to weight each token's importance.
These sparse vectors capture keyword distribution patterns. Dimensions correspond to vocabulary terms, and non-zero values indicate those terms' presence and significance in the text. With vocabularies containing tens of thousands of terms but documents using only hundreds, most dimensions remain zero—hence "sparse."
Sparse embeddings enable keyword-based similarity: documents sharing important terms produce embeddings close together in this high-dimensional space, regardless of semantic meaning.
Implementing Token-Based Search with Sparse Embeddings
Building token-based search requires several steps that prepare data for keyword matching.
Data Preparation
Start with a dataset containing text fields—product names, descriptions, document titles—and associated unique identifiers. Clean text by removing formatting artifacts and normalizing case as appropriate for your domain.
Sparse Embedding Generation
Apply a vectorization algorithm to transform text into sparse embeddings. TF-IDF vectorizers from libraries like scikit-learn provide straightforward implementation: they identify important words in your corpus and generate weighted vectors representing each document's keyword profile.
The vectorizer learns which terms are distinctive versus common across documents, assigning higher weights to distinctive terms that help differentiate content.
Index Creation and Deployment
Create a vector search index configured for sparse embeddings. This index structures your sparse vectors for efficient similarity search at query time.
Deploy the index to a query endpoint that accepts search requests and returns ranked results based on sparse embedding similarity.
Query Execution
At query time, apply the same vectorization to user queries, generating sparse embeddings that represent their keyword distribution. The system then finds indexed documents with similar sparse embeddings—those sharing important keywords with the query.
Building Full Hybrid Search
Full hybrid search requires both dense and sparse embeddings for each item in your dataset.
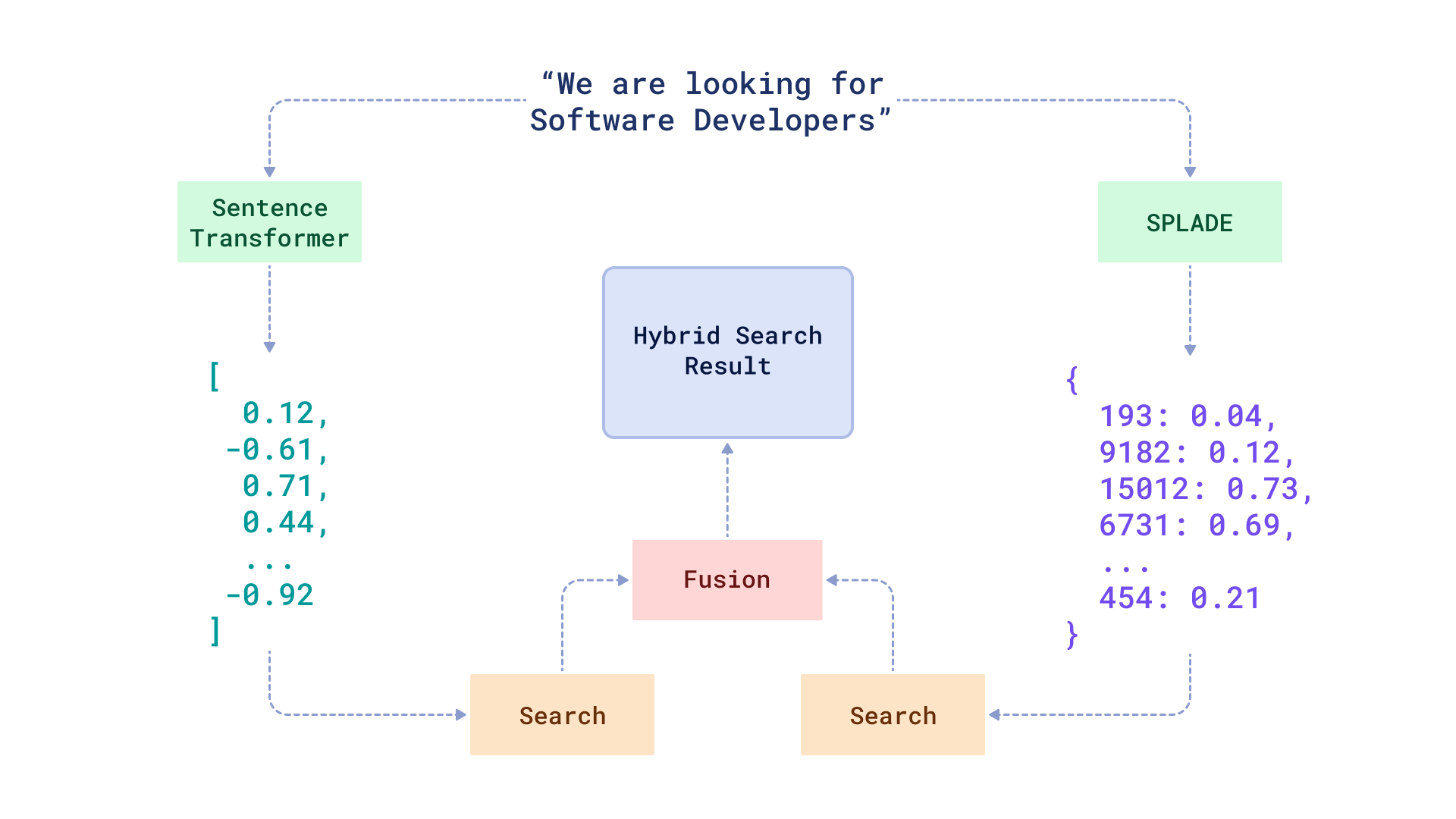
Dual Embedding Generation
For each document or item, generate two representations. Use an embedding API to create dense vectors capturing semantic meaning. Simultaneously, apply your vectorizer to produce sparse embeddings representing keyword content.
Store both representations together, associating them with the same document identifier.
Hybrid Index Configuration
Create a vector search index that accommodates both embedding types. The index maintains separate structures for dense and sparse vectors but links them to common documents.
Hybrid Query Execution
At query time, generate both dense and sparse embeddings for the user's search terms. Execute searches in both spaces—finding semantically similar content via dense embeddings and keyword-matched content via sparse embeddings.
The challenge becomes combining these separate result lists into a single unified ranking.
Reciprocal Rank Fusion: Merging Results Intelligently
Reciprocal Rank Fusion (RRF) provides the algorithm for combining rankings from semantic and keyword searches into coherent results.
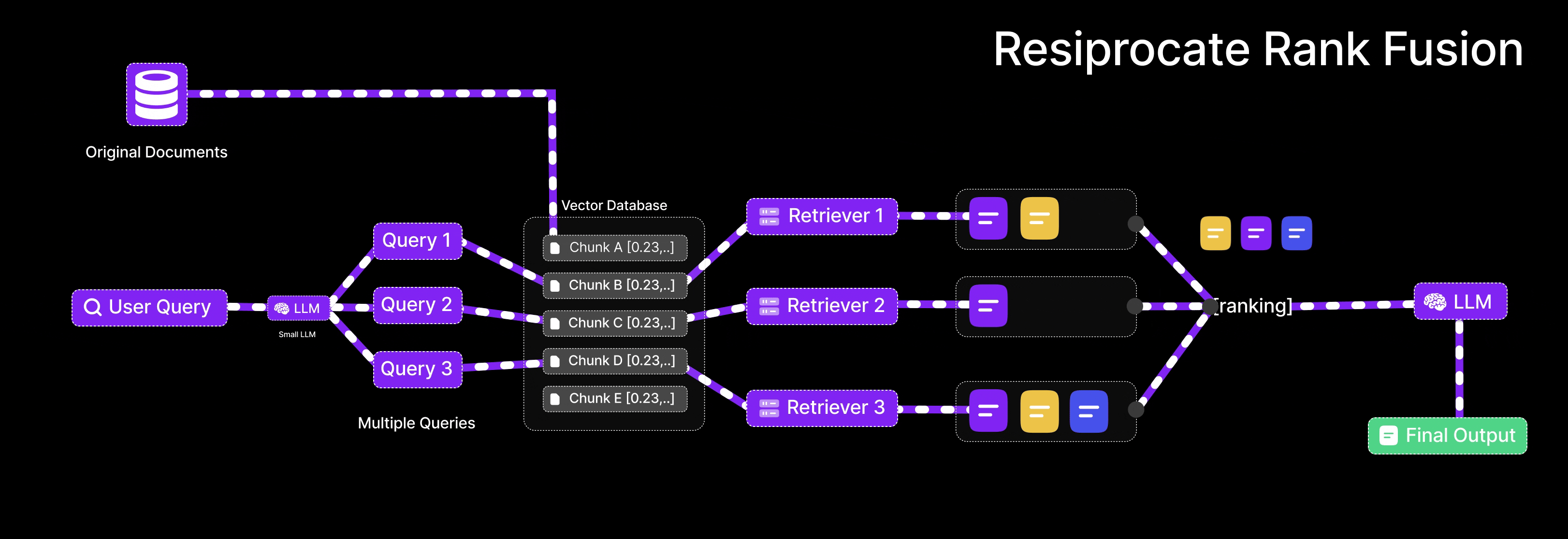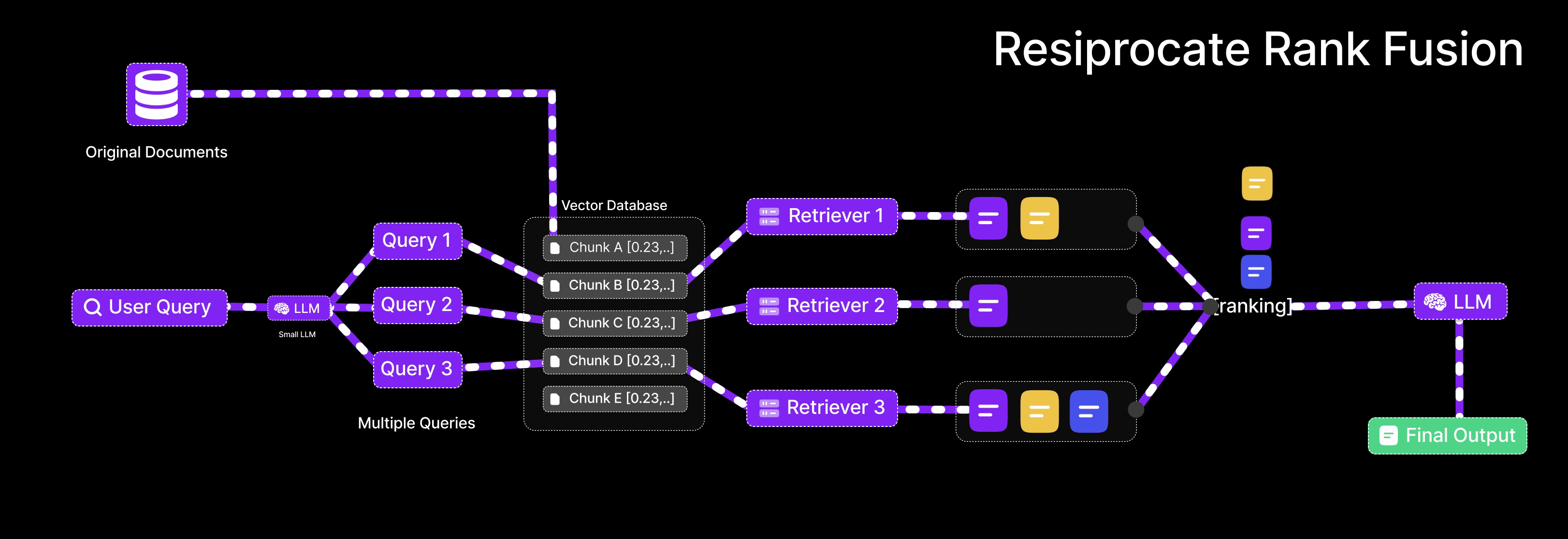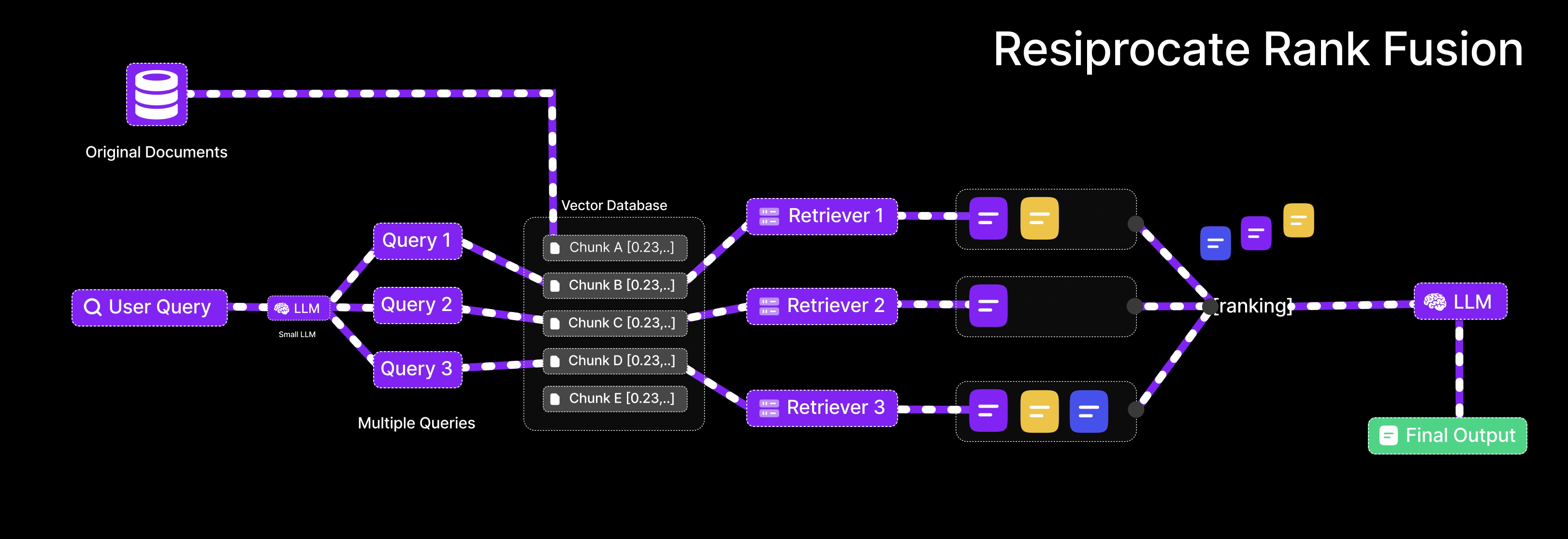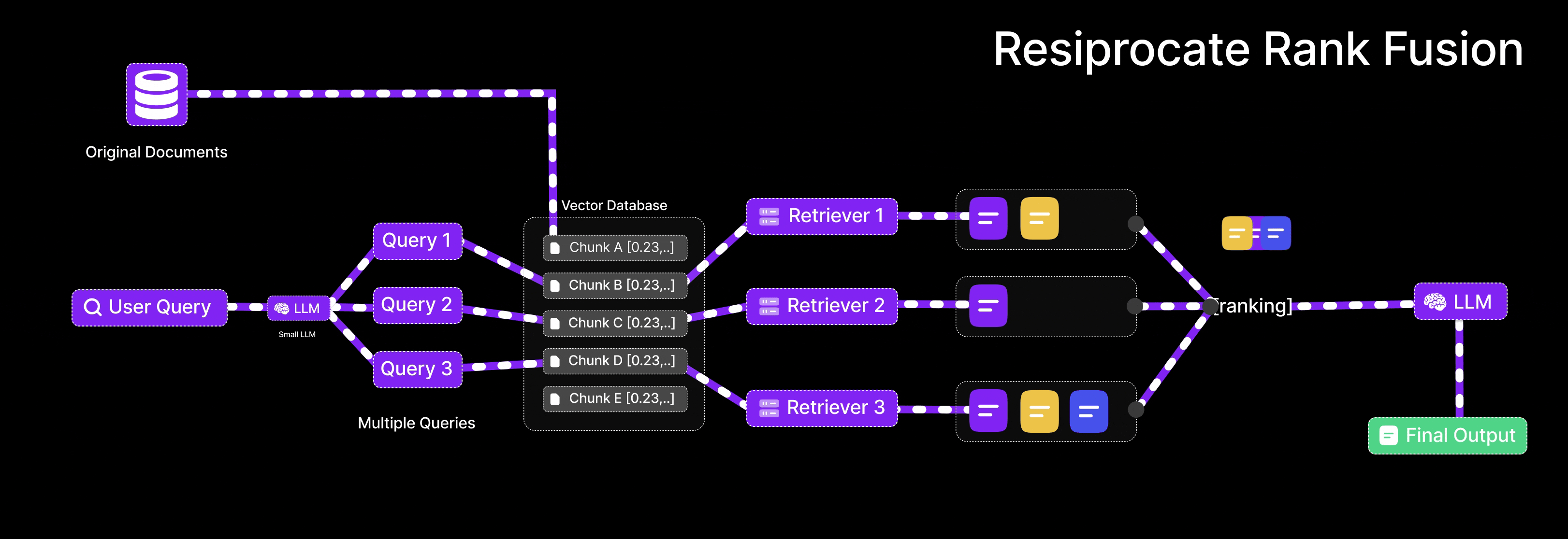
How RRF Works
RRF operates on ranked lists of items from multiple sources. For each item, it calculates reciprocal rank—the inverse of its position in each list. An item ranked first receives score 1/1 = 1.0. Second position yields 1/2 = 0.5. Third gives 1/3 ≈ 0.33, and so forth.
The algorithm sums each item's reciprocal ranks across all source lists. Items appearing high in multiple rankings accumulate larger scores. Items appearing in only one list or ranked low receive smaller scores.
Final results sort by these combined scores, naturally prioritizing items that performed well in both semantic and keyword searches.
Tuning with the Alpha Parameter
Hybrid search implementations typically provide an alpha parameter controlling the balance between dense and sparse results.
Setting alpha to 1.0 uses only dense semantic search—pure meaning-based retrieval. Setting it to 0.0 uses only sparse keyword search—pure term matching. Values between 0 and 1 blend both approaches proportionally.
An alpha of 0.5 weights semantic and keyword results equally. Adjusting alpha lets you tune retrieval behavior for your specific use case—emphasizing conceptual relevance or keyword precision as appropriate.
Benefits Hybrid Search Delivers
The combination of semantic and keyword approaches produces several valuable advantages over either method alone.

Enhanced Result Quality
Hybrid search returns results that are both conceptually relevant and contain specific keywords users mention. This dual relevance produces more satisfying search experiences—users find what they mean and what they literally asked for.
Out-of-Domain Term Handling
When semantic embeddings fail on unfamiliar terminology, keyword search picks up the slack. Specific product codes, newly released names, internal jargon—these terms match literally even when semantic understanding is absent.
This capability proves crucial for enterprise applications where domain-specific terminology dominates queries.
Reduced Query Latency
Properly implemented hybrid search achieves lower query latency than traditional token-based search engines using inverted index designs. Modern vector search infrastructure optimizes both dense and sparse similarity searches for speed.
Improved RAG Performance
Retrieval-Augmented Generation systems benefit significantly from hybrid search. By retrieving more comprehensive and accurate document sets, RAG systems access better context for generating responses, improving output quality.
Broad Applicability
Hybrid search applies across diverse use cases. Search interfaces, recommendation engines, chatbot knowledge retrieval, content discovery—any application requiring finding relevant information benefits from combining semantic and keyword approaches.
Platform Implementation: Modern Vector Search
Contemporary vector search platforms now offer native hybrid search capabilities, simplifying implementation considerably.
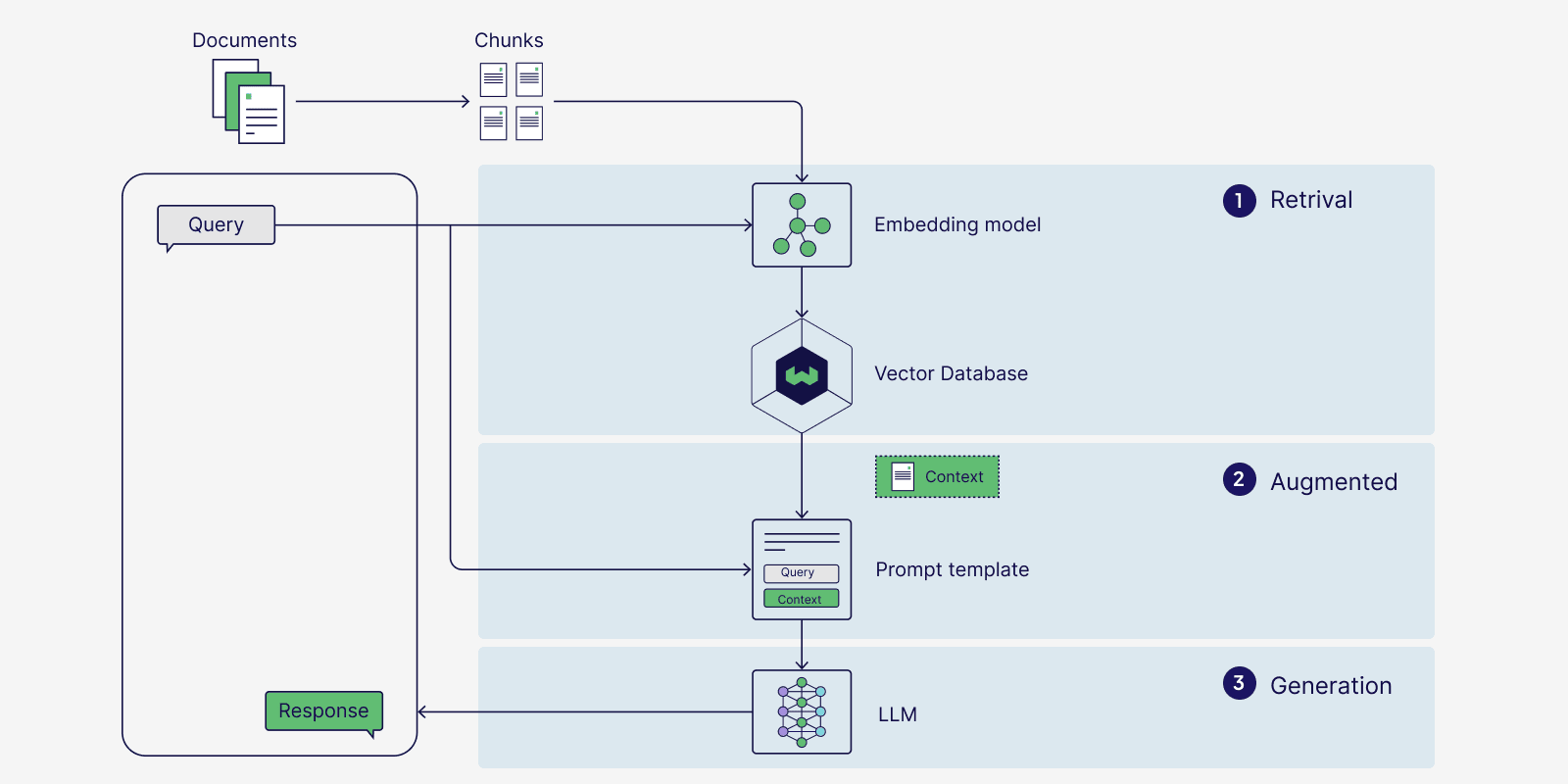
Hybrid Index Management
Platforms provide interfaces for creating indexes that accommodate both dense and sparse embeddings. You define the embedding dimensions for each type, and the system maintains appropriate data structures for efficient searches across both.
Flexible Query Execution
Query interfaces accept hybrid query objects containing both dense and sparse embeddings. The platform executes searches in both spaces and applies RRF to merge results automatically.
Customization Options
Advanced platforms offer customization for tokenization strategies, vectorization algorithms, and ranking parameters. This flexibility lets you optimize hybrid search for your specific content and query patterns.
Integration Ecosystem
Vector search platforms integrate with complementary services—embedding APIs for generating dense vectors, data pipelines for processing and indexing content, and application frameworks for building search interfaces.
Scale and Performance
Modern implementations handle millions of items while maintaining rapid retrieval times. Distributed architectures and optimized algorithms ensure hybrid search performs well even at enterprise scale.
Practical Example: E-Commerce Product Search
Consider implementing hybrid search for an online merchandise store's product catalog.
Dataset Structure
Your dataset contains product entries with titles and unique identifiers. For example: "Google Blue Kids Sunglasses," "YouTube Kids Coloring Pencils," "Google White Classic Youth Tee."
Embedding Generation
Apply a TF-IDF vectorizer to generate sparse embeddings from product titles, capturing important keywords like "Blue," "Kids," "Sunglasses." Use an embedding API to generate dense vectors representing the semantic meaning of each product description.
Index Creation
Build a hybrid index containing both embedding types for all products. Deploy this index to a query endpoint ready to accept searches.
Query Behavior
A user searches for "Kids." The hybrid system finds exact keyword matches like "Google Blue Kids Sunglasses" and "YouTube Kids Coloring Pencils" through sparse embeddings.
Simultaneously, dense embeddings recognize that "Youth" in "Google White Classic Youth Tee" relates semantically to "Kids," including this product despite the different terminology.
RRF combines these results, prioritizing products that score well in both keyword matching and semantic relevance. The user receives comprehensive results covering both literal matches and conceptually related items.
FAQ
What is hybrid search?
Hybrid search combines **semantic understanding** (dense embeddings) with **keyword precision** (sparse embeddings) to deliver more accurate and contextually relevant search results.How does hybrid search work?
It runs two parallel searches — one using semantic embeddings to understand meaning, and another using keyword matching for exact terms. The results are then merged using algorithms like **Reciprocal Rank Fusion (RRF)** to balance meaning and precision.Why is hybrid search better than keyword or semantic search alone?
Keyword search misses meaning, while semantic search struggles with unseen or domain-specific terms. Hybrid search solves both issues — it finds what users *mean* and what they *literally type*.What are the main benefits of hybrid search?
It improves search accuracy, handles new or specific terms (like product codes), reduces latency, boosts **RAG system** performance, and provides more satisfying user experiences across search, chatbots, and recommendation engines.How can I implement hybrid search?
Generate both **dense and sparse embeddings** for your content, store them in a hybrid index, and use a vector search platform that supports dual embeddings. Tune parameters like **alpha** to control the balance between semantic and keyword weighting.Which platforms support hybrid search?
Modern vector search tools — such as **Pinecone, Weaviate, Qdrant, and Vespa** — now include built-in hybrid search capabilities, making setup easier without heavy custom engineering.Where is hybrid search used in practice?
In **e-commerce**, hybrid search retrieves both literal and related items (e.g., “kids” also finds “youth” products). It’s also key for **knowledge bases, chatbots, and enterprise search** where both precision and understanding matter.Moving Forward with Hybrid Search
Hybrid search represents meaningful advancement in information retrieval capabilities. By acknowledging that semantic understanding and keyword precision both contribute value, it delivers more robust search experiences than either approach alone.
For organizations implementing search functionality, hybrid approaches offer compelling advantages. You capture the nuanced understanding that makes semantic search powerful while maintaining the literal precision that keyword matching provides.
Implementation complexity has decreased as platforms incorporate native hybrid search support. What once required custom engineering now often involves configuring existing services with both embedding types.
The key consideration is ensuring your use case benefits from both semantic and keyword capabilities. If your content contains significant out-of-domain terminology or users frequently search for specific identifiers, hybrid search likely delivers meaningful improvements over pure semantic approaches.
As embedding models continue improving and vector search infrastructure matures, hybrid search will likely become the standard approach for applications requiring comprehensive, accurate information retrieval. The question shifts from whether to implement hybrid search to how best to configure it for your specific requirements.
Start by evaluating your search quality metrics. Identify queries where semantic search alone falls short—typically those involving specific codes, proper names, or newly introduced terminology. These represent opportunities where keyword matching adds clear value.
Then measure the opposite: queries where keyword search fails to capture relevant content using different terminology. These demonstrate semantic search's contribution.
Where both patterns appear, hybrid search delivers its greatest impact—bridging both gaps simultaneously through intelligent combination of complementary approaches.
Related Articles & Suggested Reading













