

Google DeepMind released Gemma 4 on April 2, 2026, and the announcement landed with unusual force for an open model release. The 31B variant ranked third on the Arena AI text leaderboard at launch, outperforming models with up to 20 times more parameters. The 26B Mixture of Experts variant placed sixth on the same leaderboard while activating only 3.8 billion parameters per token, making it the most parameter-efficient reasoning model currently available in the open-weight space.
Neither of those facts is the biggest news about Gemma 4.
The biggest news is that for the first time in the Gemma family's history, every model ships under the Apache 2.0 license, with no usage restrictions, no monthly active user caps, no acceptable use policy enforcement, and full commercial freedom to deploy, modify, and redistribute. Every previous Gemma release used a custom Google license that deterred enterprise adoption. That constraint is gone.
What Gemma 4 Actually Ships

Gemma 4 is a family of four models targeting four distinct deployment scenarios, all built from the same foundational research as Gemini 3, Google's commercial flagship.
The Four Models
| Model | Effective Parameters | Target Hardware | Context Window |
|---|---|---|---|
| Gemma 4 E2B | 2.3B | Smartphones, Raspberry Pi, IoT | 128K |
| Gemma 4 E4B | 4.5B | Mid-range mobile, 8GB laptops | 128K |
| Gemma 4 26B MoE | 3.8B active / 26B total | 24GB GPU (RTX 3090 or 4090) | 256K |
| Gemma 4 31B Dense | 31B | Single 80GB H100 or quantized on consumer GPU | 256K |
The naming convention is worth noting. The "E" prefix in E2B and E4B stands for effective parameters, reflecting a Per-Layer Embeddings architecture that gives a 2.3B-active model the representational depth of the full 5.1B parameter count while fitting under 1.5GB of memory with quantization. The "A" in 26B-A4B indicates active parameters in the MoE architecture.
All four models are multimodal at launch. They process text and images natively across all sizes. The edge models (E2B and E4B) also handle audio input for speech recognition and translation, capped at 30 seconds. The larger models process video up to 60 seconds at one frame per second. Every model supports over 140 languages, pre-trained with cultural nuance awareness rather than post-hoc translation.
Why This Release Is Designed for Agents
Google has been explicit about the design priority: Gemma 4 is not a chatbot model that can be used for agents. It is an agent model that also does chat well.
The practical implications are specific. Every model in the family ships with native function calling, structured JSON output, multi-step planning support, and configurable extended thinking mode via system prompts or an enable_thinking=True parameter. The models can output bounding boxes for UI element detection, which is directly useful for browser automation and screen-parsing workflows. They support interleaved text, image, and audio inputs in any order within a single context window.
On the τ2-bench agentic tool use benchmark, Gemma 4 scores reflect the design priority. The models were purpose-built to chain tools across steps without requiring specialized fine-tuning for each capability, which is the practical bottleneck for deploying agents in production.
Google highlighted the on-device capability specifically. With the AICore Developer Preview for Android, developers can prototype agentic workflows that run entirely on-device without a cloud API call. The E2B model processes 4,000 input tokens across two tool calls in under three seconds on a Qualcomm Dragonwing IQ8 NPU. That kind of latency changes what is practical for mobile agent applications.
Benchmark Performance in Context
The headline numbers from Google's launch compare favorably, but deserve careful reading.
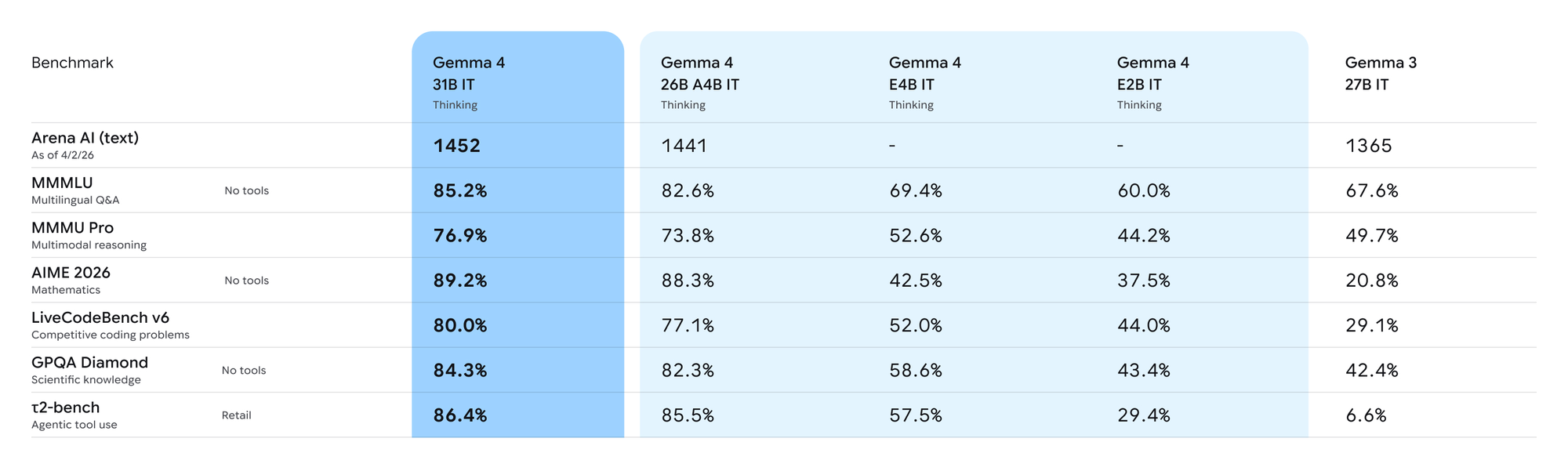
On AIME 2026 math competition reasoning, the 31B Dense model scores 89.2%, compared to 20.8% for Gemma 3 27B. On Codeforces competitive programming, the ELO jumped from 110 to 2,150. On LiveCodeBench v6, it scores 80%. These are large improvements over the previous generation, and the jump from Gemma 3 to Gemma 4 is the largest single-generation improvement independent reviewers at ai.rs described in the open model space.
The competitive picture at the 30B tier is more nuanced. Against Qwen 3.5 27B, Gemma 4 31B leads on AIME math (89.2% versus approximately 85%) and competitive programming, while Qwen 3.5 edges ahead on MMLU Pro (86.1% versus 85.2%) and GPQA Diamond science reasoning (85.5% versus 84.3%). The margins are thin in both directions.
Llama 4 Scout, despite its 109B total parameters, trails both on most reasoning benchmarks. On LiveCodeBench v6 coding specifically, Llama 4 Maverick scores 43.4%, well below either competitor at far larger parameter counts.
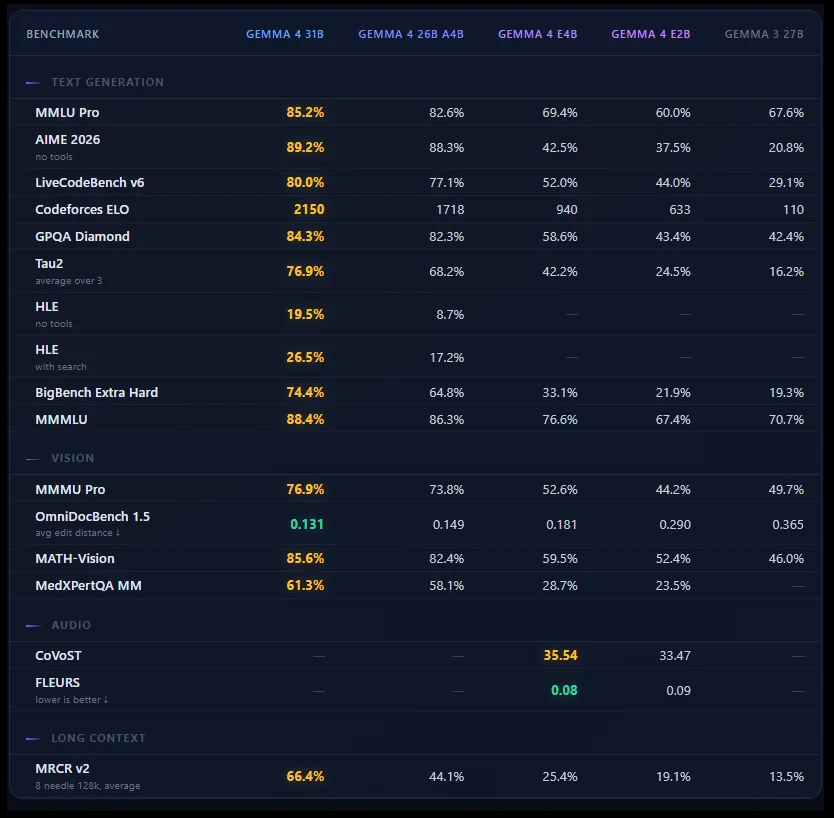
Key Benchmark Comparison (April 2026)
| Benchmark | Gemma 4 31B | Qwen 3.5 27B | Llama 4 Scout |
|---|---|---|---|
| AIME 2026 (math) | 89.2% | ~85% | Trails |
| LiveCodeBench v6 | 80.0% | Competitive | 43.4% (Maverick) |
| MMLU Pro | 85.2% | 86.1% | Trails |
| GPQA Diamond | 84.3% | 85.5% | Trails |
| Arena AI ELO (text) | 1452 (#3) | ~1441 (26B MoE is #6) | Lower |
The Arena AI leaderboard rankings matter for a reason that raw benchmark scores do not fully capture: they are based on human preference votes, not accuracy metrics. Gemma 4's 31B model placed third with humans consistently preferring its responses even when automated benchmarks showed near-identical scores against competitors. Something about how the model structures its answers resonates with human evaluators in ways that accuracy numbers do not measure.
The License Change Is the Real Structural Story
Previous Gemma releases had a problem that benchmark scores could not solve. The custom Gemma license included provisions that gave Google the right to terminate access, restricted certain commercial use cases, and introduced enough legal uncertainty that enterprises with compliance teams avoided the model family.
Gemma 4 moves entirely to Apache 2.0, the same license used by Linux, Kubernetes, and TensorFlow. This means no monthly active user limits, no acceptable use policy enforcement, and full freedom for sovereign AI deployments where data cannot leave a controlled environment.
The Register framed this directly: the license change is Google's attempt to win over enterprises that need a domestic US alternative to Chinese open-weight models from Alibaba, Moonshot AI, and Z.AI, many of which now compete directly with proprietary models, without the legal ambiguity of earlier Gemma releases.
For the practical comparison that matters to most production deployments, Gemma 4 and Qwen 3.5 now operate on an identical licensing basis. Llama 4's community license, with its 700 million MAU cap and Meta acceptable use policy, is now the most restrictive license among the three leading open model families.
Where It Runs and How to Get It
Google shipped Gemma 4 with day-one support across the tools developers already use.
- Inference frameworks: Hugging Face Transformers, vLLM, llama.cpp, Ollama, MLX, LM Studio, NVIDIA NIM, SGLang, and Unsloth all have compatibility at launch.
- Download sources: Model weights are available on Hugging Face, Kaggle, and Ollama directly.
- Cloud deployment: Google AI Studio (26B MoE and 31B), Vertex AI (26B MoE as fully managed and serverless), and Google Cloud Run with NVIDIA RTX PRO 6000 Blackwell GPUs. GKE with vLLM integration is available for teams needing elastic scaling.
- Edge and mobile: The AICore Developer Preview for Android, LiteRT-LM for IoT and edge devices, and the AI Edge Gallery app.
- Fine-tuning: Google Colab, Vertex AI, and consumer gaming GPUs all support training. Unsloth and TRL have LoRA fine-tuning support.
Hardware requirements break down clearly: E2B runs on smartphones and Raspberry Pi. E4B runs on 8GB laptops. The 26B MoE fits on a 24GB GPU such as an RTX 3090 or 4090 with Q4 quantization. The 31B Dense fits on a single 80GB H100 at full bfloat16 precision, or on consumer GPUs using quantized versions.
What Developers Found in the First 24 Hours
The benchmark numbers are real. The early deployment experience has been rougher.
Within 24 hours of release, complaints surfaced on developer forums about the 31B model running at approximately one-fifth the throughput of Qwen 3.5 on equivalent hardware. The 26B MoE, despite its efficiency advantage in active parameters, was more VRAM-hungry than competing models for equivalent context lengths. Gemma 3 27B with Q4 quantization fits 20K context tokens on an RTX 5090. Qwen 3.5 fits 190K on the same card. Gemma 4's 256K context window is real on paper, but requiring significantly more VRAM than alternatives makes it impractical on most consumer hardware.
Tooling compatibility at launch also had gaps. Hugging Face Transformers did not initially recognize the architecture, PEFT had issues with the new layer types, and QLoRA fine-tuning required workarounds.
This is not unusual for a complex new architecture at release, and the analysis from Interconnects.ai noted that Google has a track record of shipping rough early releases that improve rapidly. The fundamental architectural quality is high. The ecosystem support will catch up. But developers building production systems this week should expect friction that did not exist with more mature model families.
How It Fits Against Llama 4 and Qwen 3.5
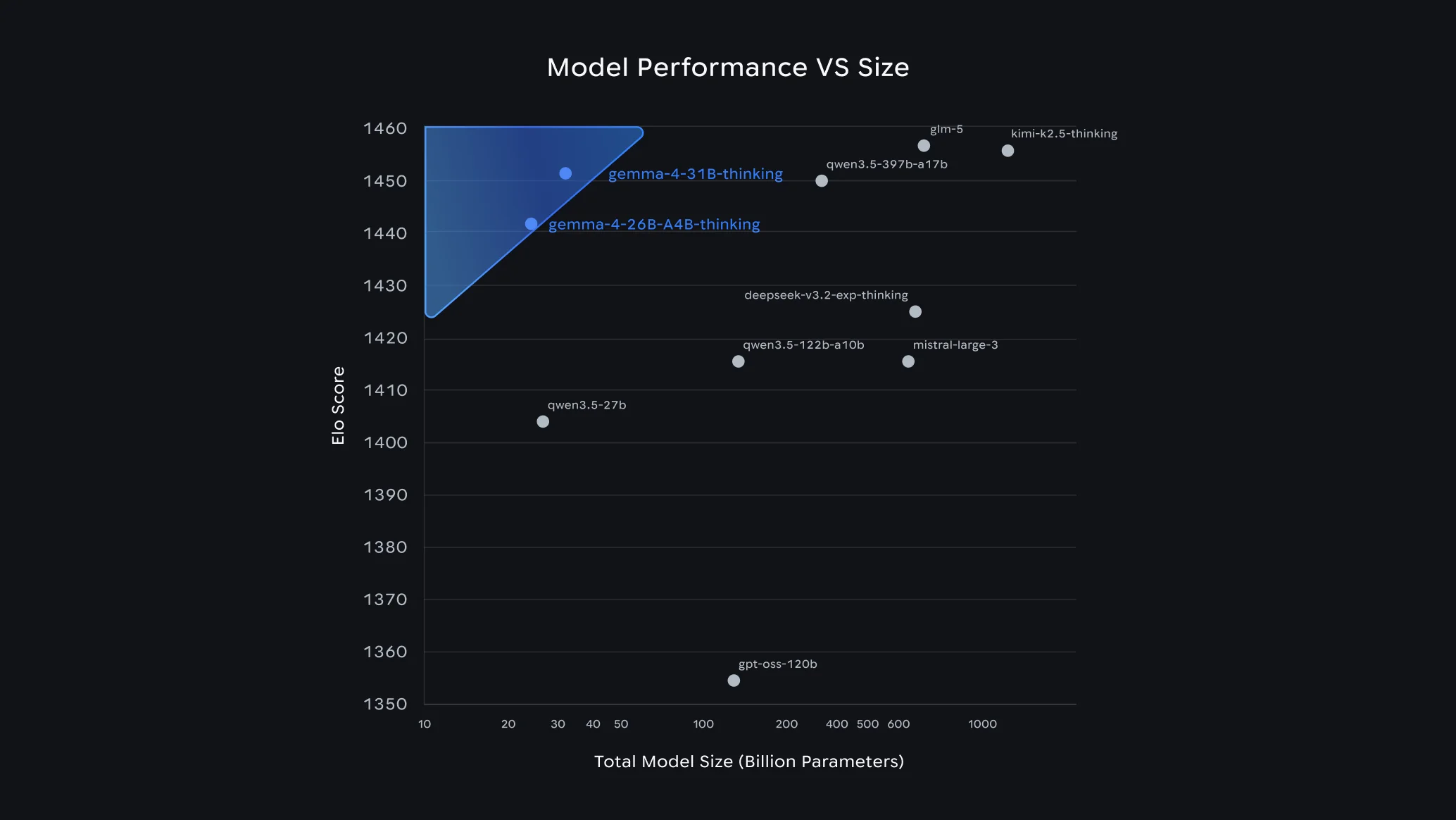
April 2026 was, as Let's Data Science described it, the most crowded month in open-source AI history. Alibaba released Qwen 3.6-Plus on the same day as Gemma 4 with a 1 million token context window. Meta's Llama 4 Scout already offered 10 million tokens. Google entered a competitive landscape rather than an open field.
The honest comparison for production deployments:
Gemma 4 31B is the strongest choice when you need the best quality-to-size ratio under a true open-source license, particularly for math reasoning, coding, and multimodal workflows on consumer or workstation hardware.
Qwen 3.5 has a measurable edge on real-world software engineering benchmarks, specifically SWE-bench Verified at 72.4% versus Gemma 4's lower score, which tests actual GitHub issue resolution rather than synthetic coding problems. If patching real codebases is the primary use case, Qwen 3.5 has the practical advantage and more mature tooling built around it.
Llama 4 is the choice when you need massive context, specifically the 10 million token Scout or the raw scale of the Maverick 400B, and when the 700 million MAU license cap is not a concern.
The practical workflow that Lushbinary and others have documented: route cheap classification and simple queries to Gemma 4 E4B, complex reasoning to the 26B MoE, and fall back to proprietary frontier models for the hardest five percent of queries. That routing pattern can reduce inference costs by 60% to 80% while maintaining output quality on the tasks that matter.
Conclusion
Gemma 4 is not Google's most capable model. Gemini 3 is. What Gemma 4 is, for the first time in the family's history, is Google's serious attempt to offer the open-model community something worth deploying in production without legal strings attached.
The Apache 2.0 license removes the last principled reason to avoid Gemma in enterprise settings. The benchmark performance at the 30B tier is genuinely competitive with the best open models available. The agentic-first design is aligned with where AI infrastructure investment is heading. And the edge variants, running multimodal agentic workflows on a Raspberry Pi or a smartphone without a cloud dependency, represent a capability threshold that competing model families have not matched at equivalent sizes.
The rough launch edges are real and will be fixed. The underlying technical quality is not in question. Whether Gemma 4 builds the ecosystem adoption that Llama and Qwen have accumulated over years of community engagement is the longer story, and that depends on factors benchmarks do not measure.
Frequently Asked Questions
What is Google Gemma 4?
Gemma 4 is a family of four open-weight AI models released by Google DeepMind on April 2, 2026, under the Apache 2.0 license. Built from the same research as Gemini 3, the family spans from 2.3B-effective-parameter edge models that run on smartphones and Raspberry Pi to a 31B dense model that runs on a single H100 GPU. All models support multimodal input, native function calling, and agentic workflows.
Is Gemma 4 free to use commercially?
Yes. Gemma 4 is released under the Apache 2.0 license, which permits unrestricted commercial use, modification, and redistribution with no monthly active user caps and no acceptable use policy enforcement. This is a significant change from previous Gemma versions, which used a custom Google license that restricted certain commercial use cases and gave Google termination rights.
How does Gemma 4 compare to Llama 4 and Qwen 3.5?
The 31B Dense model ranks third on the Arena AI text leaderboard and leads on math reasoning (89.2% on AIME 2026) and competitive programming benchmarks. Qwen 3.5 edges ahead on MMLU Pro and GPQA Diamond science reasoning, and has a measurable lead on real-world software engineering benchmarks (SWE-bench Verified). Llama 4 offers vastly larger context windows (10 million tokens) but trails on reasoning benchmarks and carries a more restrictive license with a 700 million MAU cap.
What hardware does Gemma 4 require?
The E2B model runs on smartphones and Raspberry Pi in under 1.5GB of memory. The E4B runs on 8GB laptops. The 26B MoE model fits on a 24GB GPU such as an RTX 3090 or 4090 with Q4 quantization. The 31B Dense model fits on a single 80GB H100 at full precision, or on consumer GPUs with quantization.
What are the main limitations of Gemma 4 at launch?
Early developers found the 31B model runs at roughly one-fifth the throughput of Qwen 3.5 on equivalent hardware. The 26B MoE is more VRAM-hungry than competing models at similar context lengths, making the advertised 256K context window impractical on most consumer hardware. Tooling compatibility with Hugging Face Transformers, PEFT, and QLoRA required workarounds at launch. These issues are typical for a new architecture and expected to resolve as ecosystem support matures.
What does "agentic" mean in the context of Gemma 4?
Agentic capabilities refer to the model's ability to plan across multiple steps, call external tools and APIs, and complete tasks autonomously rather than simply answering a single question. Gemma 4 has native function calling, structured JSON output, multi-step planning, and support for chaining tools together. It can also detect UI elements for screen automation. Google designed Gemma 4 primarily for these agentic workflows rather than as a general chatbot.
Related Articles













