
Bring Any Idea to Life with Gemini 3: The Definitive Guide
In the escalating arms race of artificial intelligence, version numbers often disguise the magnitude of the leap. Google’s Gemini 3 is not merely an incremental update to the 1.5 Pro lineage; it is a foundational architectural shift designed to bridge the gap between passive chatbot interaction and autonomous, agentic execution. Released in preview in late 2025, Gemini 3 arrives with a specific mandate: to serve as the cognitive engine for the "vibe coding" era, where natural language prompts translate into complex, multi-step software engineering tasks without the fragility that plagued earlier LLMs.
For developers, enterprise architects, and power users, the release of Gemini 3 signals the end of the "prompt-and-pray" cycle. With features like Deep Think, Thought Signatures, and the new Antigravity platform, Google is aggressively targeting the space occupied by OpenAI’s o1/GPT-5 class models and Anthropic’s Claude Sonnet series. This guide dissects the technical reality of Gemini 3, stripping away the marketing veneer to expose the pricing structures, API constraints, and reasoning capabilities that will determine if it is the right tool to bring your next idea to life.
Gemini 3
The Architecture of Reason: Deep Think and Thought Signatures
Gemini 3’s most significant deviation from its predecessors is the exposure of its internal reasoning process, a feature Google calls Thinking Level. Unlike standard LLMs that predict the next token immediately, Gemini 3 can be configured to deliberate before responding. This "System 2" thinking style is accessible via API parameters, allowing developers to balance latency against logical depth.
The Mechanics of Thought Signatures
Perhaps the most critical technical introduction is the concept of Thought Signatures. In previous stateless API interactions, maintaining the context of a model's reasoning chain during multi-turn conversations or function calling was notoriously difficult. Gemini 3 introduces encrypted representations of the model's internal thought process.
When building complex agents that require multiple round-trips (e.g., checking a database, analyzing the data, then formatting a report), developers must now return these Thought Signatures in subsequent API calls. This cryptographic enforcement ensures that the model does not "forget" its reasoning path mid-workflow. Omitting these signatures in function calling results in strict 400 errors, a design choice that prioritizes reliability over flexibility. It essentially forces developers to adopt best practices for state management in AI applications.
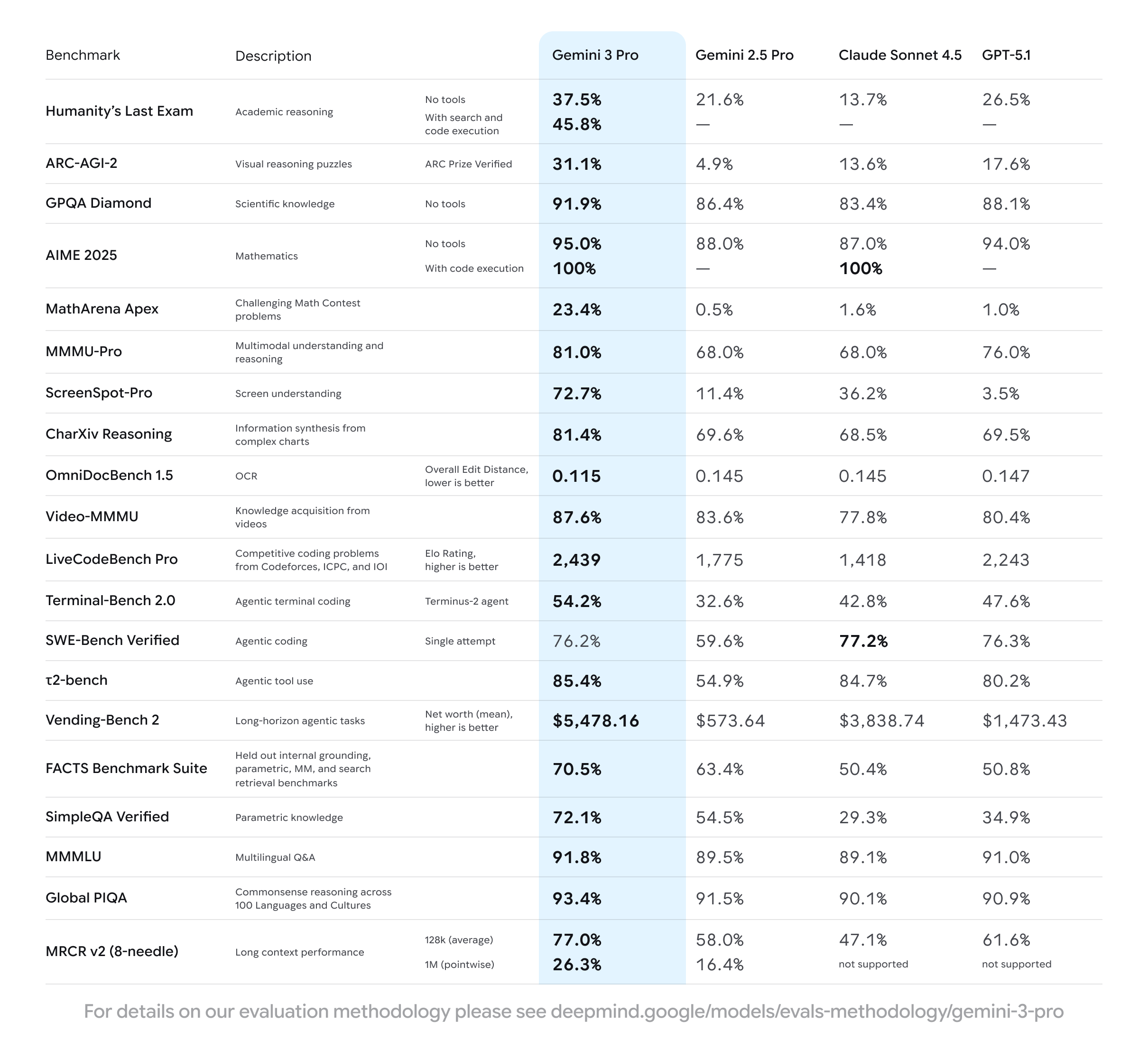
Model Evaluation: Gemini 3 Pro
Evaluation Approach
Gemini 3 Pro underwent comprehensive testing across multiple key areas:
- Reasoning capabilities
- Multimodal performance
- Agentic tool use
- Multi-lingual functionality
- Long-context processing
Methodology
Testing Parameters: All Gemini scores use pass@1 methodology with single-attempt settings, meaning no majority voting or parallel test-time compute. Testing was conducted via the Gemini API using model-id gemini-3-pro-preview with default sampling settings. Multiple trials were averaged for smaller benchmarks to reduce variance.
Comparative Data: Results for non-Gemini models come from provider self-reported numbers. For Claude Sonnet 4.5 and GPT-5.1, high reasoning results are prioritized when available. Google DeepMind independently calculated scores for several benchmarks using official provider APIs where public data was unavailable.
Benchmark Categories
Reasoning and Academic Knowledge
- Humanity's Last Exam: Results sourced from ScaleAI leaderboard (Gemini 2.5 Pro, Claude Sonnet 4.5) and Artificial Analysis (GPT-5.1). Gemini 3 Pro results are self-computed with blocklists to avoid benchmark contamination.
- ARC-AGI-2: Sourced from ARC Prize website (ARC Prize Verified, semi-private set)
- MathArena Apex: Reported by matharena.ai
Image Understanding
- MMMU-Pro: Scores averaged across Standard (10 options) and Vision settings
- ScreenSpotPro: Gemini 3 uses function calling with "capture screenshot" tool and extra_high media resolution (60.5 score with high resolution)
- CharXiv Reasoning: 1000 reasoning questions from validation split
- OmniDocBench 1.5: Average Edit Distance across Text, Formula, Table, and ReadingOrder metrics
Video Processing
- Video-MMMU: Computed using media_resolution=HIGH (280 tokens per frame) and temperature=0
Code Generation
- LiveCodeBench Pro: ELO Rating from public leaderboard
- Terminal-Bench 2.0: Public leaderboard results using Terminus 2 agent harness
- SWE-bench Verified: Single-attempt scaffolding with bash tool, file operations, and submit tool (averaged over 10 runs)
- τ2-bench: Standard sierra framework across Retail (85.3%), Airline (73.0%), and Telecom (98.0%) categories
- Vending-bench 2: Results from andonlabs.com evaluations
Tool Use
Evaluated across various agentic scenarios and function-calling tasks.
Factuality
- FACTS Benchmark Suite: New robust factuality benchmarks (not directly comparable to previous FACTS Grounding results)
- SimpleQA Verified: Official Kaggle leaderboard results
Long Context
- MRCR v2: 128k cumulative score for cross-model comparison, plus 1M context window pointwise value demonstrating full-length capability
Key Findings
Gemini 3 Pro demonstrates significant performance improvements over Gemini 2.5 Pro across all evaluated benchmarks as of November 2025.
The Ecosystem: Antigravity and Android Studio Otter
A model is only as useful as the tools that wield it. Google has launched Google Antigravity, a dedicated IDE designed specifically for "agentic development." Unlike standard code editors where AI is a plugin (like Copilot), Antigravity treats the prompt as the source code. It allows developers to spin up autonomous agents that can edit multiple files, run terminal commands, and iterate on errors without human intervention.
Android Studio Integration
For mobile developers, Gemini 3 Pro is embedded directly into Android Studio Otter. This is not a simple chat sidebar; the model has read/write access to the project structure, enabling it to refactor legacy Java code into Kotlin, generate UI layouts from screenshots, and debug crash logs with context awareness that generic chatbots lack. This integration highlights Google’s strategy: verify the model's capabilities by dogfooding it in the most complex IDE environment available.
Pricing Analysis and Hidden Token Costs
Understanding the bill for Gemini 3 requires more than just looking at the sticker price. Google has introduced a tiered pricing structure that penalizes inefficiency but rewards caching.
The Base Rate:
- Input: $2.00 per million tokens (prompts < 200k tokens).
- Output: $12.00 per million tokens.
The "Deep Think" Tax:
Crucially, "thinking tokens"—the internal monologue the model generates to solve hard problems—are billed as output tokens. If you enable high-level reasoning for a complex query, the model might generate 2,000 invisible thinking tokens before producing 500 visible response tokens. You pay for 2,500 output tokens. This hidden cost can balloon budgets if the thinking_level parameter is left unchecked on high-volume applications.
Context Caching Efficiency:
To mitigate this, Google offers aggressive pricing for Context Caching ($0.20/1M input tokens + storage fees). For developers building RAG (Retrieval-Augmented Generation) apps where the system prompt or knowledge base remains static, this is an essential optimization lever that undercuts competitor pricing for long-context tasks.
Developer Experience: APIs, SDKs, and Function Calling
Gemini 3’s API introduces granular controls that senior engineers have been demanding.
Streaming Function Calling:
Previously, tool use in LLMs was a "stop-and-go" process. The model would pause, request a tool, wait for the output, and then resume. Gemini 3 supports streaming function arguments. This means as the model decides to call a weather API, it streams the arguments (e.g., {"city": "Tokyo"...) in real-time, allowing the UI to update or the backend to pre-fetch data before the JSON is even fully formed. This reduces perceived latency significantly.
Multimodal Function Responses:
Functions can now return images or PDFs directly to the model. If an agent requests a chart from a data analysis tool, the tool can return the raw image data, which Gemini 3 can then analyze and describe in the final response. This closes the loop on true multimodal agentic workflows.
Real User Sentiment: The Reddit & Product Hunt Consensus
Since its November 2025 preview launch, the developer community has stress-tested Gemini 3 extensively. The consensus is nuanced.
The Good:
- "Vibe Coding": Users on r/LocalLLaMA and r/singularity report that Gemini 3 captures the intent of coding prompts better than GPT-4o or Claude 3.5, requiring fewer follow-up corrections for boilerplate generation.
- Math & Logic: The Deep Think mode is widely praised for solving AIME 2025 level math problems that cause other models to hallucinate.
The Bad:
- Narrative Sterility: For creative writing and translation, users note a "robotic" quality. It lacks the prose elegance of Claude or the conversational fluidity of GPT-5.1. It is a tool for builders, not poets.
- Strictness: The enforcement of Thought Signatures and strict parameter validation has frustrated hackers used to looser API constraints. Google is trading ease-of-use for enterprise stability, which alienates the hobbyist crowd.
- Rate Limits: As a preview model, users frequently hit capacity limits, specifically when using Deep Think mode.
Limitations and Risks
Before migrating your production stack to Gemini 3, consider these hard limitations:
- Knowledge Cutoff (Jan 2025): Without active grounding (Search enabled), the model is blind to events post-January 2025. RAG is mandatory for current-events applications.
- Deep Think Context Cap: While the standard model boasts a 1M token window, enabling Deep Think shrinks this to ~192k tokens. You cannot dump an entire codebase into the context window and ask for deep reasoning simultaneously.
- Technical Debt Generator: The ease of generating code with Antigravity poses a risk of "orphaned code"—software written by AI that human teams do not fully understand and cannot maintain without AI assistance. This creates a dependency loop that organizations must manage carefully.
Final Verdict: Is Gemini 3 Ready for Production?
Gemini 3 is Google’s most confident stride into the agentic AI future. It is not a general-purpose chatbot; it is a specialized engine for reasoning and code synthesis. If your use case involves complex data extraction, autonomous software engineering, or heavy logic puzzles, Gemini 3 Pro is currently the class leader.
However, for creative writing, simple chatbots, or tasks requiring massive context with deep reasoning, the constraints (pricing of thinking tokens and the Deep Think context cap) require careful architectural planning. Gemini 3 proves that the future of AI isn't just about generating text—it's about generating thought, and for the first time, Google is letting developers pay for exactly that.
Learn more about Gemini 3 on the official developers website
Read also about Google AI:













