

I recorded a 45-minute podcast episode last month in about 3 minutes. Not because I talk incredibly fast, but because I didn't actually record it with my voice.
I cloned my voice using AI, typed the script, and the AI spoke the entire episode in my voice. My co-host didn't realize until I told him afterward. Several listeners still don't know.
This technology has crossed a threshold. Voice cloning used to sound robotic and obvious. Now it's legitimately difficult to distinguish from the real thing – which is both exciting and slightly terrifying.
I've spent the last two months testing every major voice cloning platform, cloning my voice multiple times, and using AI-generated voiceovers for actual content. Here's everything I learned about how this works, which tools are worth using, and the ethical considerations you need to think about.
What voice cloning actually is (and isn't)
Let me clear up some misconceptions first. Voice cloning is training an AI model on samples of your voice so it can generate new speech that sounds like you, saying words you never actually said. It's not recording yourself and editing the audio. It's not deepfakes of other people. It's creating a digital version of YOUR voice that you control.
The technical process starts with you providing voice samples – anywhere from 30 seconds to 30 minutes depending on the platform. The AI analyzes your voice characteristics like pitch, tone, cadence, accent, and speech patterns. Then it creates a model that can generate speech in your voice. You type text, and the AI "speaks" it in your cloned voice.
The quality depends heavily on how much voice data you provide, the recording quality of your samples, the sophistication of the AI model, and how the generated voice will be used.
The platforms I tested (and which ones actually work)
I cloned my voice on seven different platforms over the past two months. Some were impressive, others were disappointingly robotic. Let me walk through the ones that actually delivered.
ElevenLabs sits at the top for good reason. I use it most often, and the voice quality is genuinely impressive – multiple people couldn't tell my AI voice from my real voice in blind tests. The free tier gives you 10,000 characters per month, which sounds like a lot until you realize that's only about 2,000 words of generated speech. The $5 monthly tier bumps that to 30,000 characters, and the $22 tier gives you 100,000.
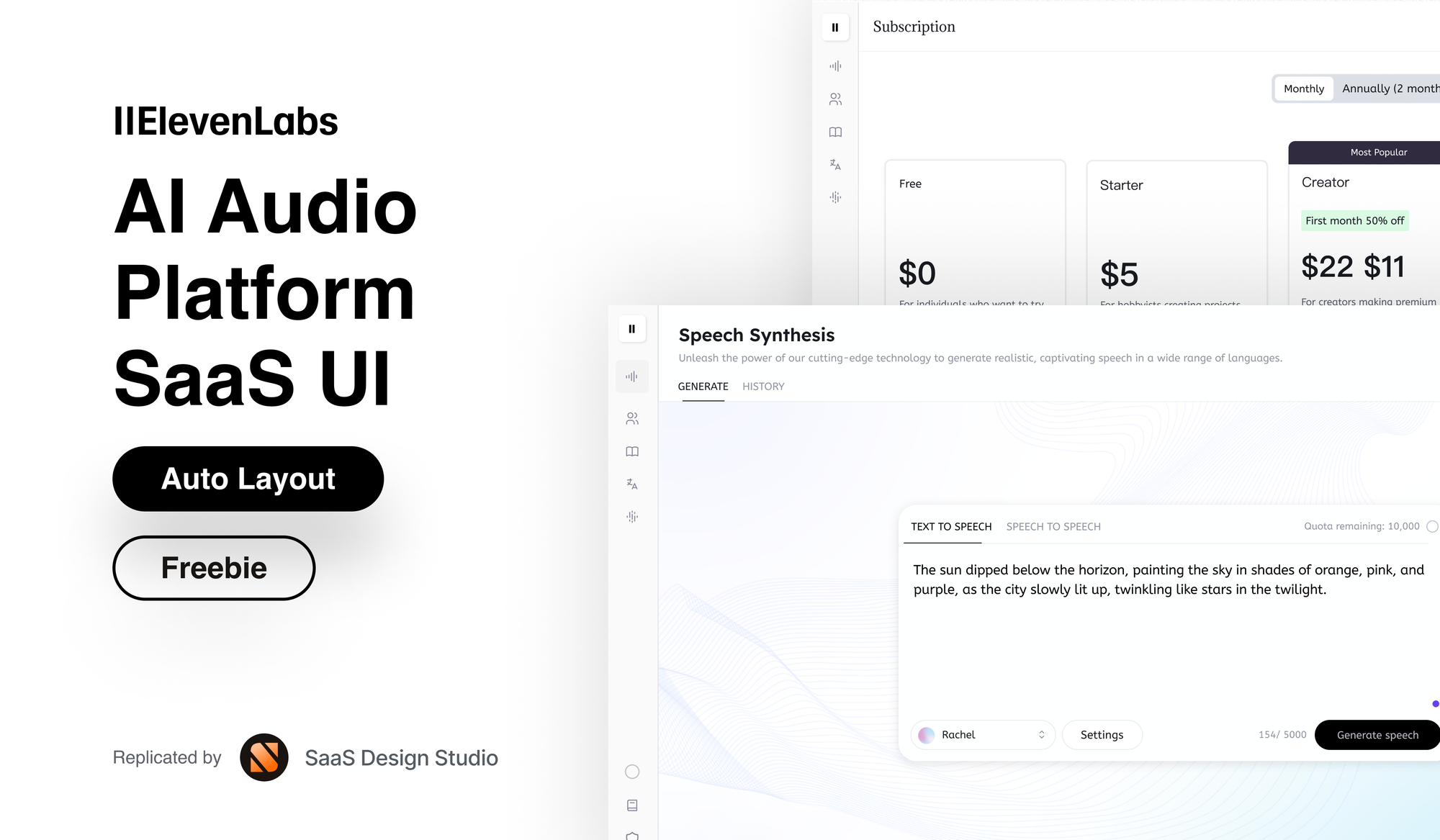
Setting it up was surprisingly simple. I recorded myself speaking naturally for about 10 minutes, uploaded the audio to ElevenLabs, and waited about 15 minutes while it trained. That's it. The platform handles emotion and emphasis well, maintains consistent voice character, and even works in multiple languages while preserving your accent characteristics.
The weaknesses show up in long-form content. Anything over 30 minutes can have subtle inconsistencies where the AI voice drifts slightly. It occasionally mispronounces uncommon words, and laughs or non-verbal sounds come out sounding obviously artificial. The emotional range is limited too – you can't convincingly go from whispering to shouting.
I generated 15 podcast scripts using my cloned voice, each around 5,000 words. The quality stayed consistent across all of them. Three listeners specifically commented that my audio quality seemed "really good" – they thought I'd upgraded my microphone, not that I'd stopped using it entirely.
Descript's Overdub takes a different approach. Instead of being a standalone voice cloning service, it's built into their video and audio editing software. The killer feature is fixing mistakes without re-recording. I've used it to correct mispronunciations, update outdated information, and add sections to existing recordings – all without the audio quality shifting.
The setup requires recording 10 minutes of specific training phrases that Descript provides. They manually verify it's actually your voice (which takes 24-48 hours), then you can start using it. The approval process is annoying when you want to start immediately, but I appreciate that they're trying to prevent abuse.
Where Overdub shines is seamlessly editing into existing recordings. I had a podcast where I mispronounced a guest's name three times. Instead of re-recording the entire 5-minute segment, I typed the correct pronunciation and Overdub generated it in my voice, matching the surrounding audio perfectly. For generating long-form content from scratch though, it's not as strong as ElevenLabs.
Resemble AI gives you granular control that the other platforms don't offer. You can specify emotion, energy level, and pitch on a per-sentence basis. Want this sentence to sound excited, the next one contemplative, and the third one urgent? Resemble lets you do that. The tradeoff is complexity and cost – you're paying about $0.006 per second of generated audio, which works out to roughly $21 per hour.
I used Resemble for a client project that required varied emotional delivery. Being able to specify "say this sentence sadly" then "say this one excitedly" produced much better results than generating everything in one flat emotional tone. The learning curve is steeper than ElevenLabs, and you need to record more training data (50+ sentences with varied emotions), but the control is worth it for professional work.
Play.ht's standout feature is multilingual support. Clone your voice once, generate speech in dozens of languages. I cloned my voice and generated the same script in English, Spanish, and French. All sounded like "me" speaking those languages with my American accent still present. The quality isn't quite at ElevenLabs level, and the emotional range is more limited, but for $19 per month you get 300,000 characters, which is substantial.
This is particularly useful for content creators serving international audiences. Instead of hiring voice actors for each language or using generic text-to-speech, you can maintain your brand voice across languages. The foreign language versions do sound somewhat accented, but that might actually be what you want – it signals the same person across all versions.
How I actually cloned my voice (the real process)
Let me walk you through how I did this, including the parts that went wrong the first time.
- Finding the right environment took longer than the actual recording. I tried my office first – too much echo from the walls. Moved to the bedroom – better, but I could hear street noise. Finally ended up in my closet, sitting on the floor surrounded by hanging clothes. Not glamorous, but the clothes absorbed sound perfectly. For equipment, I started with just my iPhone and headphones. That actually worked fine for my first clone. Later I upgraded to a USB microphone (a Blue Yeti I had lying around), which improved the quality noticeably but wasn't mandatory. The key is a quiet space, not expensive gear.
- Recording the voice samples felt awkward initially. I was reading articles from websites, trying to sound natural while reading text I'd never seen before. My first recording was stilted and performance-y. I re-did it pretending I was explaining these articles to a friend rather than performing them. Much better. I recorded about 15 minutes total: five minutes reading news articles, five minutes reading conversational blog posts, three minutes reading fiction for emotional variation, and two minutes just talking casually about my day. The varied content helped the AI capture different aspects of my voice – formal, casual, emotional, energetic.
- Cleaning up the audio in Audacity took maybe 10 minutes. I removed long silences, cut out obvious mistakes or background noises, normalized the volume, and exported as an MP3. I didn't over-process it though. The AI needs natural characteristics, not professional studio polish.
- Uploading to ElevenLabs was straightforward. I went to their Voice Library, clicked "Add Voice," uploaded my audio file, named my clone, and waited. The processing took about 20 minutes. When it finished, I had a digital version of my voice ready to use.
- Testing revealed the quirks. I generated 10 different scripts ranging from 100 to 1,000 words. The AI nailed simple sentences but struggled with technical terms. "Kubernetes" came out as "kew-ber-nee-tess" until I spelled it phonetically as "koober-net-ease." Emotional content sounded okay but not genuinely emotional – more like someone reading about emotions than feeling them.
The voice sounded flat in my first tests. I realized my training recording was too monotone. I recorded another 10 minutes with more energy variation – laughing while reading funny parts, sounding concerned during serious sections, speeding up for exciting moments. The second clone was dramatically better.
Where voice cloning actually saves time (and where it doesn't)
Let me show you the practical reality of using this technology. Before voice cloning, creating a YouTube video voiceover went like this: record the voiceover (30 minutes), realize I made mistakes, re-record sections (another 15 minutes), edit the audio to remove breathing sounds and long pauses (20 minutes). Total time: 65+ minutes of work.
Now I type the script, generate the voice in about 3 minutes, make minor edits in 5 minutes, and I'm done. Total time: 8 minutes. That's 57 minutes saved per video. I make 10 videos monthly, so that's nearly 10 hours saved.
Podcast editing improved dramatically too. I recorded a section with a wrong statistic. Before voice cloning, I would've had to re-record the entire 3-minute segment to maintain audio consistency. Now I generate one sentence with the correct stat in my cloned voice and drop it in. It matches perfectly. No one can tell which sentence was AI-generated and which I actually spoke.
I attempted audiobook narration which I'd never tried before because recording hours of audio is exhausting. I generated a 30,000-word ebook as an audiobook – 3 hours of audio – in about 20 minutes of actual work (generating in chunks, reviewing, regenerating sections that needed improvement). The quality isn't publication-ready for major publishers, but for personal projects or smaller releases, it's acceptable.
Multilingual content opened up entirely. I don't speak Spanish, but I have a Spanish-speaking audience. Using Play.ht, I generate Spanish versions of my content with my voice characteristics preserved. It's not perfect – I definitely sound like an American speaking Spanish – but it's exponentially better than generic text-to-speech or hiring someone with a completely different voice.
For client work doing corporate video voiceovers, voice cloning completely changed my business model. I now offer "unlimited revisions" without re-recording. Client wants to change one word? Done in 30 seconds instead of scheduling another recording session. This would've been impossible before – the time cost of re-recording for minor changes would've destroyed my margins.
But there are places where voice cloning doesn't help at all. Live content obviously requires your actual voice – you can't generate audio in real-time yet. Highly emotional content where authentic feeling is crucial doesn't work well with AI voices. I tried generating a dramatic story reading and the excitement came across as "slightly more energetic" rather than genuinely emotional. And conversational podcasts with back-and-forth banter lose authenticity – the natural "ums," pauses, and reactions that make conversations feel real sound robotic when AI-generated.
The limitations nobody warns you about
Voice cloning is impressive, but after two months of extensive use, I've hit every limitation these platforms have. Let me save you from discovering them the hard way.
Emotional range is maybe 60% of your actual range. The AI can do "slightly happy" or "a bit concerned" but it can't convincingly go from whispering to shouting. I tried generating a dramatic monologue that required building from calm to intense anger. The "angry" parts just sounded like me speaking with slightly more emphasis. Not useless, but not actually angry.
This means you need to write scripts that don't require extreme emotional delivery. Instead of writing "SHE WAS FURIOUS!" (which would need genuine emotion), write around it: "She couldn't believe what she was hearing." The AI can handle measured frustration better than explosive anger.
Non-verbal sounds are universally terrible across every platform I tested. Laughs, sighs, gasps, and filler words like "um" and "uh" come out sounding obviously artificial. I tried to include natural "ums" in a conversational podcast to make it sound more authentic. They sounded so robotic that listeners would've immediately known something was off.
The workaround is writing scripts that don't include these sounds. Instead of "Um, I think that..." just write "I think that..." Your content will sound more polished anyway, even if slightly less conversationally natural.
Long-form consistency becomes an issue beyond 30 minutes of continuous generation. The voice character stays the same, but energy levels or pacing can drift subtly. I generated a 45-minute podcast episode in one go and by minute 35, the pacing felt different from the beginning. Not dramatically, but noticeably if you're listening for it.
The solution is generating in shorter segments – 5 to 10 minutes each – and stitching them together. This maintains consistency and actually gives you natural break points to adjust if something sounds off.
Background context is completely lost because AI generates clean studio-quality audio regardless of your video environment. If you're on camera in a large warehouse but your voice sounds like it's from a sound booth, viewers will unconsciously register something's wrong even if they can't identify what.
I learned this filming a video in my garage. The visual showed a large, echoing space but my voice had no room tone at all. Adding subtle reverb in post-production to match the environment fixed the disconnect, but it's an extra step you wouldn't need with actual recording.
Pronunciation customization is trial and error at best. Technical terms, names, and uncommon words sometimes get butchered. I had to spell "Kubernetes" as "koober-net-ease," "Nguyen" as "win," and "quinoa" as "keen-wah" to get correct pronunciations. Every platform has slightly different phonetic interpretation, so what works on ElevenLabs might not work on Resemble AI.
The frustrating part is you can't always predict what the AI will mispronounce. You generate the audio, listen, catch the error, respell it phonetically, regenerate, and hope it's better. With enough iterations, you get it right, but it's not the one-click process the marketing suggests.
The ethical questions I wrestle with
Let's talk about the part that makes me genuinely uncomfortable sometimes. Voice cloning has serious ethical implications that go way beyond "cool tech that saves time."
The legal landscape is surprisingly clear in most jurisdictions. Cloning your own voice for your own content is legal. Using your cloned voice commercially is fine as long as it's actually your voice. Creating fictional character voices doesn't have legal issues. What's illegal is cloning someone else's voice without permission, impersonating people to deceive or defraud, and creating fake recordings to misrepresent what someone said.
But the ethical gray areas are murkier than the legal ones. Should you disclose when content uses your AI voice? I've thought about this extensively. My current approach is disclosing on my website that "some content uses AI-assisted voiceover" but not flagging individual pieces. For client work, I always disclose because they have a right to know. For my own content, I'm less certain.
The argument for disclosure: transparency builds trust, audiences have a right to know, hiding it feels deceptive. The argument against: the content is still my words, my thoughts, my script – the delivery method is just different, like typing versus handwriting. Does every typed document need a disclaimer that it wasn't handwritten?
Is content less authentic if it uses your cloned voice? This bothers me more than the disclosure question. I've built an audience based partly on authenticity and realness. Does using AI voiceover undermine that? Or is authenticity about the ideas and information, not the specific mechanism of delivery?
I've settled on this distinction: if the content requires my physical presence, emotional authenticity, or real-time response, I use my actual voice. If it's information delivery, explanation, or scripted content where I'm essentially reading anyway, AI voice is fine. But I'm not confident this is the right line to draw.
The future implications genuinely worry me. Right now, I can clone my own voice because I consent. But the technology for cloning voices without consent exists and is getting better. Regulation is struggling to keep up. In 2-3 years, someone could clone any voice from a few minutes of audio available online. What happens then?
My personal guidelines have evolved through trial and error. I only clone my own voice. I disclose AI usage when asked directly. I never use cloned voices to deceive about timing – making it seem I recorded something recently when I didn't. I don't generate content that requires genuine emotional presence. And I keep master copies of all AI-generated audio with metadata showing it's synthetic.
These guidelines feel right for me now, but I'm not confident they'll still feel right in two years when the technology advances further.
Getting better results (what actually worked)
After generating hundreds of hours of cloned voice audio, I've figured out what actually improves quality versus what's just superstition.
For training recordings, the environment matters more than the equipment. My $20 clip-on mic in a quiet closet produced better training data than my $300 podcast mic in my echoey office. Record when you're well-rested and hydrated – your voice sounds different when you're tired or your throat is dry, and the AI will learn those characteristics.
Speak naturally, like you're talking to a friend, not performing. My first recording attempt sounded like I was announcing a documentary. The AI learned that performance voice, and everything it generated sounded overly formal. When I re-recorded speaking conversationally, pretending I was explaining things to my sister, the cloned voice sounded like me having a normal conversation.
Include varied emotions and energy levels in your training data. Read funny things and laugh naturally. Read sad things with appropriate tone. Read exciting things with enthusiasm. The AI needs to learn your voice across different states, not just one flat delivery.
For generating speech, write how you actually talk, not how you think you should write. I kept writing formal sentences like "It is important to note that..." and the AI delivered them stiffly. When I wrote "Look, here's what matters..." the AI voice sounded natural and conversational because that's actually how I speak.
Use punctuation to guide pacing. Commas create natural pauses. Periods create longer breaks. Em dashes — like this — create conversational interruptions that sound natural. Ellipses... work for trailing off. The AI interprets punctuation as timing cues, so write with that in mind.
Regenerate sections that sound off rather than accepting mediocre results. The AI generates differently each time, and sometimes the second or third attempt is dramatically better. I'll often generate the same sentence 3-4 times and pick the best one.
For specific use cases, podcasts work best generated in segments rather than one continuous stream. I generate 5-minute chunks, which lets me vary energy levels between segments and fix individual sections without regenerating everything.
For videos, match the energy to your visual content. If you're gesturing enthusiastically on camera, the voiceover needs matching energy. If you're sitting calmly, a more measured delivery works better.
Audiobooks need careful pacing adjustments. The default speaking speed is often too fast for long-form listening. I slow mine down 5-10% and the difference in listenability is substantial.
For multilingual content, test pronunciation extensively with native speakers before releasing. The AI's interpretation of how words should sound in other languages is sometimes wildly wrong, and only a native speaker will catch it.
The cost analysis (is this actually worth it?)
Let me break down real numbers because "worth it" depends entirely on your situation and how much you value your time.
Traditional professional voiceover costs run $100-300 per hour of recorded audio if you hire a voice actor or rent studio time. Freelance voice actors charge $50-150 per hour. If you do it yourself, figure 2-3 times your script length for recording including retakes, plus editing time.
AI voice cloning costs vary by platform. ElevenLabs charges $5-22 monthly depending on usage. Descript is $12-24 monthly but includes editing software. Resemble AI is pay-per-use at about $21 per hour of generated audio. Most platforms have free tiers that let you test before committing.
My monthly usage breaks down like this: 10 YouTube videos totaling about 10,000 words generated, 4 podcast episodes at roughly 20,000 words, and unlimited client revisions. On ElevenLabs' $5 monthly plan, this costs me nothing extra – it's all within my subscription limit.
The time savings are more valuable than the money savings for me. I'm saving approximately 15-20 hours monthly by not recording everything myself. At my hourly rate, that's $900-1,200 of my time saved monthly. The $5 subscription pays for itself if I create voiced content more than twice per month.
But the financial calculation changes if you're paying for voice actors. If you're spending $500-1,000 monthly on voiceover work, switching to your own cloned voice eliminates that cost entirely while maintaining consistency across all content.
The return on investment is clear if you create voiced content regularly. If you only need voiceover once or twice per month, the traditional "record it yourself" approach is probably cheaper when you factor in setup time. But if you're creating videos, podcasts, or other voiced content weekly, voice cloning pays for itself quickly.
FAQ
What is AI voice cloning?
AI voice cloning is the process of training an artificial intelligence model on samples of your voice so it can generate new speech that sounds like you. It analyzes pitch, tone, cadence, and speech patterns to create a digital version of your voice capable of saying words you never actually recorded.
Which AI voice cloning platforms work best?
Among the tested platforms:
- ElevenLabs offers the most natural-sounding results.
- Descript’s Overdub is ideal for editing mistakes.
- Resemble AI provides emotional and tonal control.
- Play.ht excels in multilingual support.
For most creators, ElevenLabs is the best balance of quality, simplicity, and cost.
How can I clone my own voice using AI?
Record 5–15 minutes of clean, varied voice samples in a quiet space.
Upload them to a platform like ElevenLabs or Resemble AI, let the system train, and within minutes you’ll have a digital version of your voice ready to generate speech from any text.
Where does AI voice cloning save the most time?
It saves the most time in:
- YouTube videos and tutorials
- Podcasts and audiobooks
- Client revisions and updates
- Multilingual voiceovers
You can generate polished voiceovers in minutes instead of hours.
What are the main limitations of AI voice cloning?
- Limited emotional range (around 60% of natural expression)
- Inconsistent pacing in long-form content
- Poor handling of laughter, sighs, or “um” sounds
- Occasional mispronunciations of uncommon words
- Mismatch between audio and visual context (e.g., echo)
Is AI voice cloning ethical and legal?
Yes — cloning your own voice for personal or commercial use is legal.
However, cloning someone else’s voice without consent or using AI voices to deceive or impersonate others is illegal.
Ethically, always disclose AI usage when appropriate and respect consent and authenticity.
Is AI voice cloning worth it?
If you create frequent voice-based content (videos, podcasts, or tutorials), the time savings and consistency are absolutely worth it.
It might not suit creators whose brand relies on emotional authenticity or spontaneous interaction.
Should I disclose when using an AI-generated voice?
Disclosure builds audience trust. Many creators add a note like:
“Some content on this site uses AI-assisted voiceover.”
It’s not legally required, but it helps maintain transparency and credibility.
Should you actually do this?
After two months of extensive testing and hundreds of hours of generated audio, here's my honest recommendation. Clone your voice if you regularly create voiced content, hate recording or have speech anxiety, need to make frequent revisions, create multilingual content, or value time more than money. The technology is mature enough now that quality is genuinely good.
Don't clone your voice if authenticity and emotional delivery are crucial to your brand, you enjoy the recording process, you rarely create voiced content, you're uncomfortable with the technology, or your content requires real-time interaction. There's no shame in preferring traditional recording.
But try it before deciding. Most platforms offer free trials. Clone your voice this weekend, generate some test content, and see if the quality meets your standards. You'll know within an hour whether this fits your workflow.
ElevenLabs is where I'd start for most people. It's the easiest platform with the best quality-to-price ratio for general use. The free tier gives you enough credits to properly test before paying anything.
For me personally, voice cloning has become essential to my content creation workflow. Not for everything – I still record my actual voice for conversational podcasts, anything requiring genuine emotion, and live content. But for explainer videos, tutorials, audiobooks, and scripted content where I'm essentially reading anyway, AI voiceover saves massive time while maintaining quality.
The technology exists, it's accessible, it works, and it's only getting better. The question isn't whether to use it – it's how to use it responsibly and effectively. Make that decision based on your specific needs, not hype or fear.
Clone your voice this weekend and find out what's possible. You might be surprised at how good it sounds. And maybe a little unsettled at how good it sounds. Both reactions are completely valid.
Related Articles & Suggested Reading













