Remember when ChatGPT couldn't count letters in "strawberry"?
Two years ago, asking an AI model to count the R's in "strawberry" produced hilariously inconsistent results—hallucinations, guesses, and occasional lucky hits. Today, you can watch the same question trigger something different: the model visibly "thinks," spelling out each letter, methodically counting, and arriving at the correct answer: three.
This shift feels magical, as though artificial intelligence suddenly learned logic. The reality is more nuanced and arguably more interesting. These models haven't discovered reasoning in any human sense. They've learned to spend more computational resources—more tokens—before delivering answers. And they can afford this luxury because the underlying systems have exploded in scale, from GPT-2's 117 million parameters trained on eight billion tokens to trillion-parameter behemoths processing roughly 15 trillion tokens across massive GPU clusters.
This evolution represents a fundamental pivot in AI development strategy, one that carries significant implications for how organizations deploy and budget for AI capabilities.
The Pre-Training Plateau: When Bigger Stopped Being Better
For years, AI progress followed a predictable pattern governed by scaling laws: more parameters plus more training data equals better performance. Larger models trained on bigger datasets consistently outperformed their smaller predecessors.
This approach delivered remarkable results, but it's hitting practical limits. We've essentially scraped the accessible internet for training data. GPU clusters are pushing the boundaries of power consumption and cooling capacity. Many researchers now acknowledge we're approaching what they call a "pre-training plateau"—a point where simply building bigger models yields diminishing returns.
Rather than confronting this wall head-on, researchers asked a different question: If we can't scale the model further, could we scale the answer time instead?
This question spawned a new generation of AI systems called reasoning models. They use the same neural architecture and weights as traditional models, but implement a new scaling dimension—inference-time compute. The hypothesis: users will tolerate longer wait times (seconds, minutes, or more) if the results justify the delay.
How Reasoning Models Actually Work
Understanding reasoning models requires grasping how they differ from standard language models at the operational level.
Traditional Token Generation
Standard GPT-style models generate one token at a time in a single stream, continuing until they reach an end-of-text marker that signals completion. This marker isn't arbitrary—models learn to produce it during training because engineers include it in all training examples, teaching the system when to stop generating.
The Two-Stream Approach
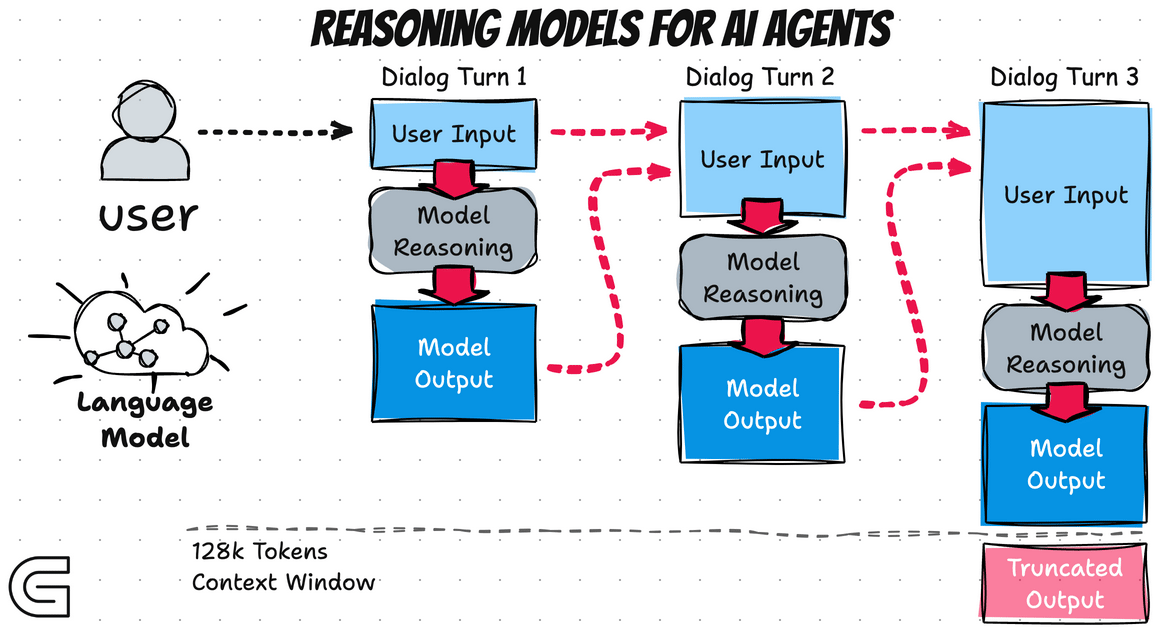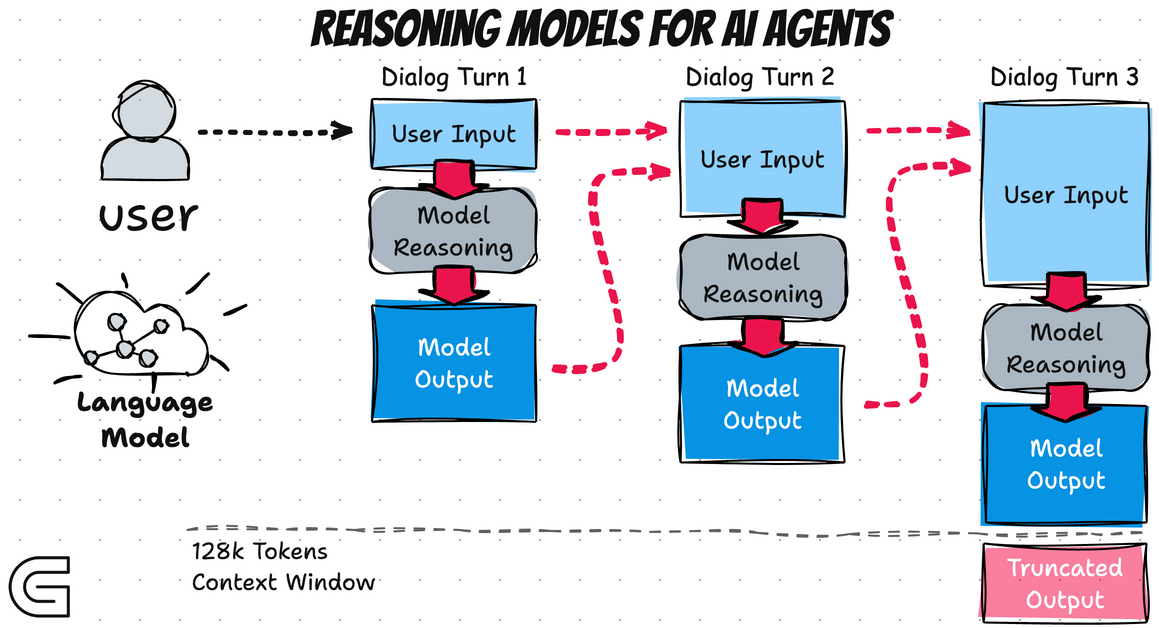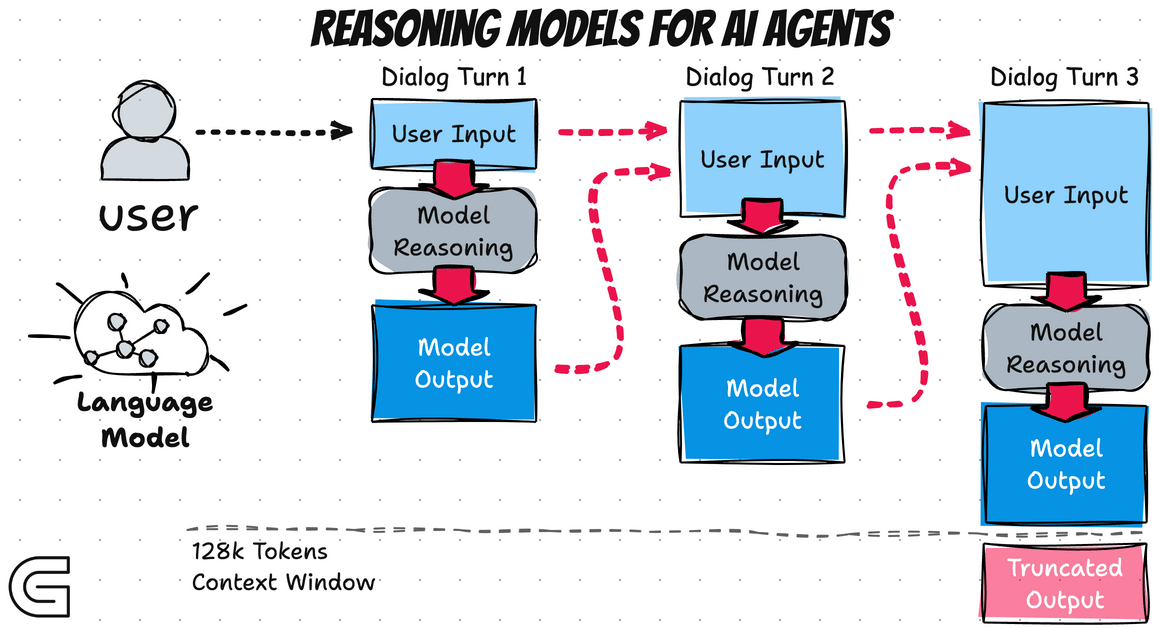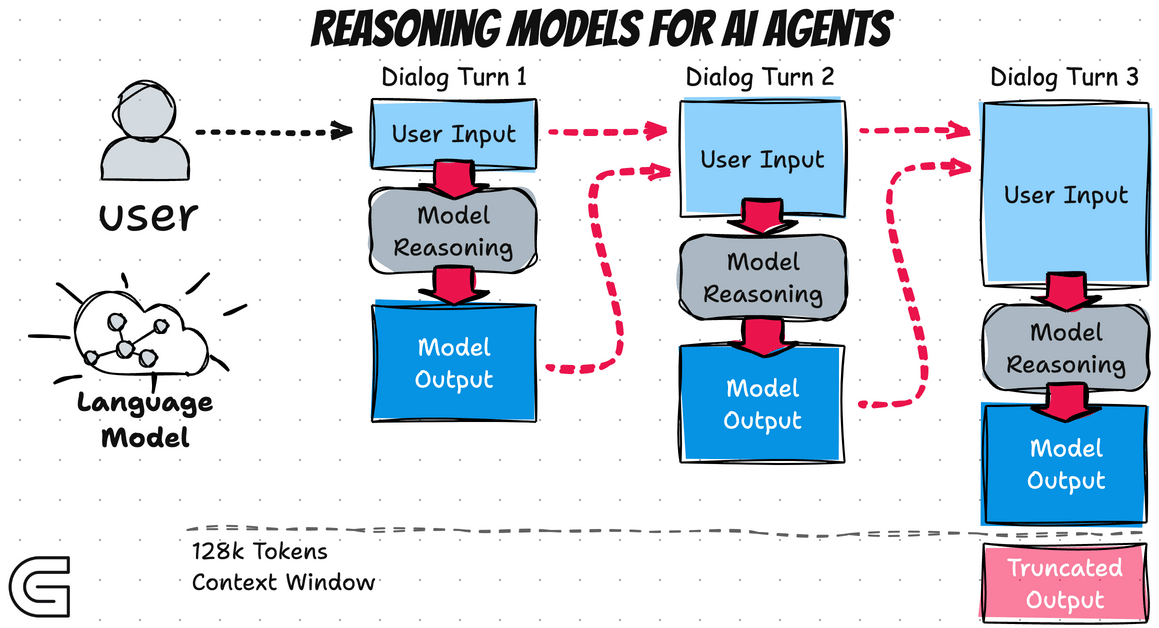
Reasoning models generate two distinct streams instead of one. First comes a hidden internal monologue—a chain of thought where the model works through the problem step by step. This isn't visible to users (or at least, not fully visible in commercial implementations).
Engineers introduced a new token—end-of-thinking—to mark where this private reasoning concludes. Only after reaching this marker does the model generate the polished response users see, eventually emitting the standard end-of-text marker.
The model hasn't become logical in any philosophical sense. It's still predicting the next most probable token based on patterns in training data. However, it now predicts a longer preamble first, walking through solutions methodically. This extended process provides more context that nudges probability distributions toward correct final tokens.
Think of it as giving the model a scratch pad where it can show its work before committing to an answer—exactly like humans do when solving complex problems.
Creating Reasoning Models: The Training Process
Building reasoning models involves several distinct phases beyond standard pre-training.
Starting Point: Pre-Trained Foundation
Reasoning models begin with massive pre-trained foundations like GPT-4 or Gemini-class models. The standard pre-training phase remains unchanged—the model learns language patterns from enormous text corpora.
Supervised Fine-Tuning with Chain-of-Thought
Engineers then construct specialized datasets where each example contains three components: a question, a complete chain-of-thought demonstration showing step-by-step reasoning, and the final answer.
Mathematics and coding prove particularly valuable for this training because they offer verifiable, binary outcomes. Either the theorem is proved correctly or it isn't. Either the code executes successfully or it fails. This clear feedback enables more effective training.
The model processes these examples through supervised fine-tuning, learning to place the end-of-thinking token before the end-of-text token—establishing the two-stream generation pattern.
Reinforcement Learning for Accuracy
Next comes reinforcement learning that focuses on outcome quality rather than process. Instead of evaluating every token, the system grades only final answers using specialized functions—perhaps another language model, human reviewers, or automated validators like code compilers.
Correct answers require no gradient updates. Incorrect answers trigger small penalties that adjust model weights. This process resembles the reinforcement fine-tuning that enables models to adapt their style and structure based on relatively few examples.
Calibration: Learning When to Think
Finally, models undergo calibration with questions requiring varying levels of reasoning—some trivial, some moderately complex, some extremely challenging. This teaches the system when to provide quick responses and when to invest substantial thinking time.
Just as humans answer "2+2" instantly but need tools for complex calculus, reasoning models learn to allocate computational resources appropriately.
Deployment: Dynamic Thinking Allocation
At deployment, reasoning models autonomously decide how long to think before responding.
Ask a simple factual question, and the model might generate one or two hidden reasoning tokens before immediately responding. Pose a complex challenge—designing a novel algorithm, for instance—and you might watch it process for sixty seconds, generating hundreds of private deduction tokens before producing output.
This flexibility comes at a cost. Every thinking token consumes API credits and GPU cycles. For workflows involving multiple model calls—like AI agents that query the model ten or more times per task—these costs compound rapidly. What seemed like an affordable side project can suddenly resemble renting a small data center.
This represents the dark side of inference-time scaling: we've replaced parameter growth with thinking-time growth, and the financial implications followed.
OpenAI's Controlled Summaries
OpenAI's implementation adds another wrinkle. Rather than exposing the complete thinking process, they provide controlled summaries of the reasoning. What you see isn't exactly what the model generated internally.
This has two important implications. First, you cannot use these summaries to train your own reasoning models—they're sanitized versions rather than raw internal states. Second, if crucial reasoning context is needed for follow-up questions, you must explicitly copy it into your next prompt. The model doesn't automatically carry its private notes forward between conversation turns.
New Prompting Strategies for Reasoning Models
The emergence of reasoning models requires adjusting how we interact with AI systems.
Traditional Prompting: Explicit Instruction
With standard language models, effective prompting often involved explicit step-by-step guidance: "Let's think step by step" or "First list the letters, then count the R's." We essentially had to teach the model how to approach problems.
Reasoning Model Prompting: Define Goals, Not Methods
Reasoning models have chain-of-thought built in. They don't need procedural instructions. Instead, optimal prompts focus on goals and constraints rather than methodology.
Provide clear objectives and guidelines you want the system to follow. The model will determine necessary steps and actions independently. More information about what you want—rather than how to proceed—produces better results.
Cost and Latency Management
Since you're paying for thinking tokens, cost-conscious prompts should acknowledge this explicitly: "Reason briefly for at most five steps, then answer." Conversely, when deep analysis justifies the expense: "Take as much time as needed to thoroughly explore this problem."
Making the model "conscious" of your priorities helps it allocate thinking resources appropriately.
The New Scaling Dimension: Inference-Time Compute
Traditional scaling operated along two axes: model parameters and training data. We maximized both until hitting physical constraints—power consumption, hardware limitations, and depleted training corpora.
Reasoning models introduce a third axis: test-time or inference-time compute. Instead of building taller buckets or filling them with more data, we "shake the bucket longer" each time we retrieve information.
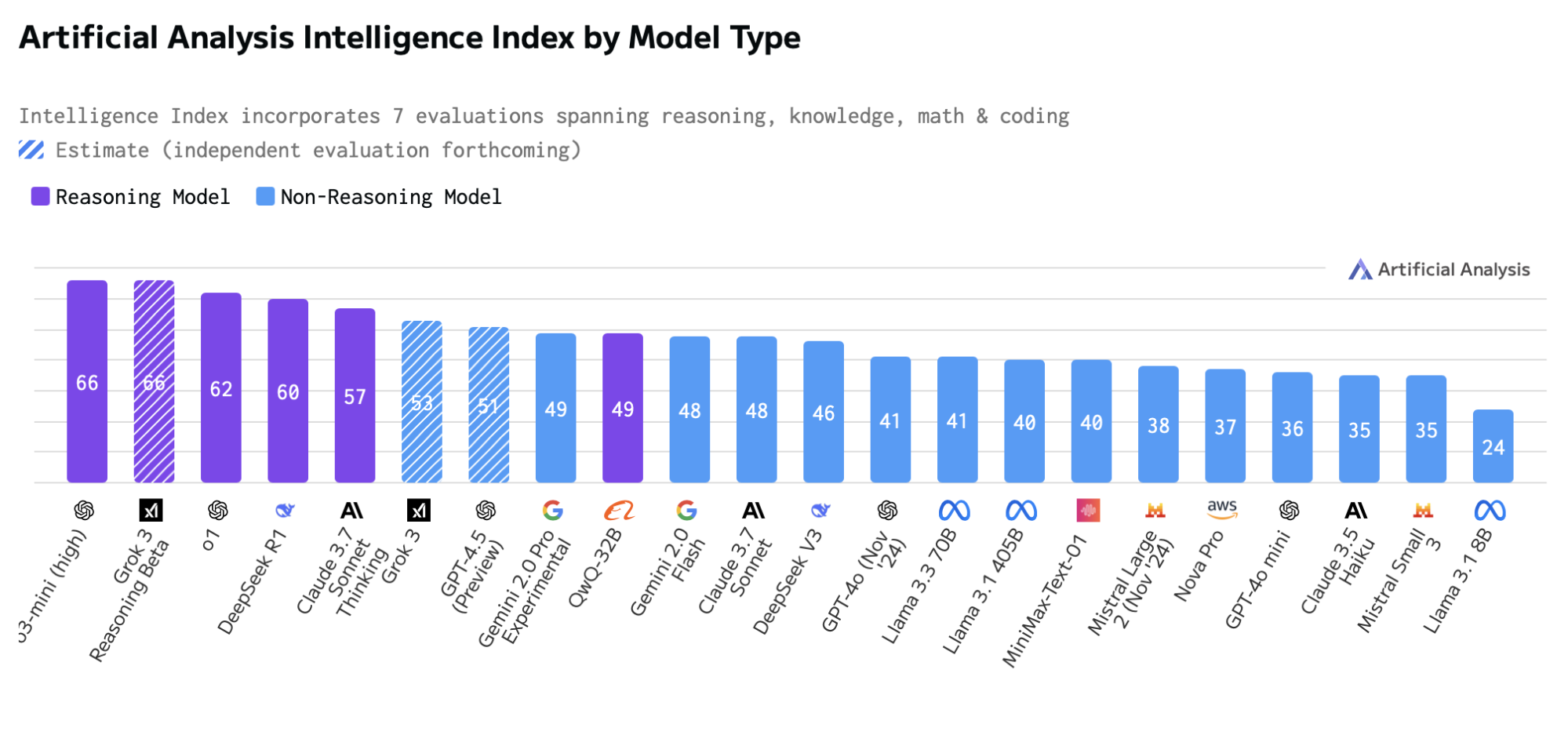
This approach proves clever but not unlimited. Early implementations like OpenAI's O1 and DeepSeek R1 demonstrate substantial improvements on mathematics and coding benchmarks with moderate additional thinking time. However, the curve flattens as thinking extends further.
Eventually, feeding the model excessive quantities of its own tokens hits diminishing returns. If the knowledge isn't already in the model's base understanding, additional thinking time can't conjure it from nothing.
This limitation connects inference-time scaling to another crucial capability: tool use. When internal reasoning reaches its limits, models need external resources—web searches, calculators, code execution environments. This naturally leads to agentic systems that combine reasoning with environmental interaction.
The Reasoning Question: Are These Models Actually Thinking?
The terminology around "reasoning models" invites an important philosophical question: do these systems genuinely reason?
The answer depends on your definition of reasoning, but from a technical perspective, the answer is largely no—at least not in any way that resembles human cognition.
These models remain next-token predictors. They're extraordinarily sophisticated statistical machines that predict subsequent tokens based on preceding context. The apparent logic emerges from sampling more conditional probabilities, not from symbolic manipulation or causal understanding of the world.
The chain-of-thought mechanism helps models expose intermediate states that were previously hidden in their internal processing. This makes final outputs more accurate and provides transparency that humans can audit. However, every step in that chain represents the same statistical prediction game that's powered language models since GPT-2—just executed over longer sequences with more computational resources.
Understanding this distinction matters because it sets appropriate expectations. Reasoning models excel at problems with clear solution paths and verifiable outcomes. They struggle with genuinely novel challenges requiring insight beyond pattern matching in training data.
Practical Deployment: Choosing the Right Tool
The proliferation of reasoning models doesn't obsolete traditional language models. Instead, it expands the toolkit available for different scenarios.
When to Use Standard Models
For straightforward tasks—customer support responses, content summarization, simple translations—smaller, faster standard models remain optimal. They deliver adequate quality at lower latency and cost.
When to Use Reasoning Models
Complex research questions, multi-step code generation, mathematical problem-solving, and tasks requiring deep analysis justify reasoning models despite higher costs. The improved accuracy and reliability often offset the computational expense.
Hybrid Architectures
Sophisticated systems increasingly combine both model types. Reasoning models serve as the "brain," handling strategic planning and complex decision-making. Standard models act as "executors," performing specific actions like translation, tool use, or structured output generation based on the reasoning model's instructions.
This division of labor optimizes both performance and cost—reserving expensive reasoning compute for decisions where it adds genuine value.
Environmental and Economic Considerations
The shift toward inference-time scaling carries implications beyond technical performance.
Every additional thinking token consumes electricity and produces heat that requires cooling. GPU time represents real energy expenditure with environmental consequences. As organizations deploy reasoning models at scale, the cumulative power consumption becomes substantial.
From a practical standpoint, this argues for thoughtful model selection. Use the simplest model or approach that adequately solves your problem. Reserve reasoning models for situations where their additional capability justifies the resource consumption.
Someone pays for those extra seconds of GPU time—whether through direct API costs or infrastructure expenses. Our planet pays through increased power consumption. Both considerations deserve weight in deployment decisions.
FAQ
What are AI reasoning models?
Reasoning models are advanced AI systems that use extra inference-time compute to “think” step by step before producing an answer, improving accuracy on complex tasks.How do reasoning models differ from standard AI models?
Unlike standard models that generate one output stream, reasoning models create a hidden chain-of-thought first, then deliver a polished final answer.Do reasoning models actually think like humans?
No. They remain probabilistic token predictors, but their extended internal reasoning process makes outputs appear more logical and reliable.When should I use reasoning models?
Use them for complex problem-solving like math, code generation, or deep analysis. For simpler tasks, standard models are faster and cheaper.Are reasoning models more expensive to run?
Yes. Longer reasoning consumes more GPU time and API credits, which increases costs and latency compared to standard models.Can I control the reasoning time of these models?
Yes. You can set constraints in prompts (e.g., “reason briefly” or “analyze in depth”) to balance accuracy, cost, and speed.What are the environmental implications of reasoning models?
More inference-time compute means higher energy use. Organizations should apply reasoning models selectively to minimize environmental and financial costs.Looking Forward: The Next Frontier
We began with a simple question about counting letters in "strawberry" and uncovered a new scaling dimension that trades inference-time compute for improved reasoning capability.
Whether this approach represents a path toward artificial general intelligence or merely provides breathing room before the next fundamental breakthrough remains an open question. Current evidence suggests it's powerful but not unlimited—a valuable addition to our AI toolkit rather than a revolution in machine cognition.
The practical takeaway for organizations is clear: When your model isn't performing adequately, don't immediately assume you need a larger model. Try giving it time to think first. Let it generate that internal chain-of-thought and see whether the improved answer justifies the additional tokens.
This approach often delivers better results at lower total cost than training or deploying fundamentally larger systems. It represents a smarter way to extract value from existing AI infrastructure.
As these technologies mature, we'll continue discovering optimal combinations of model size, training data, and inference-time compute for different problem domains. The future of AI likely involves navigating all three dimensions strategically rather than maximizing any single axis.
For now, we have new tools that think before they speak. Use them wisely, use them appropriately, and keep an eye on both the invoice and the environmental impact. The most sophisticated AI strategy isn't about deploying the most advanced models—it's about matching capabilities to needs with intelligence and restraint.
Related Articles & Suggested Reading